Assessment of quality degradation in modern voice deepfake detectors under cross-linguistic shift from English to Ukrainian
DOI:
https://doi.org/10.15587/2706-5448.2026.352336Keywords:
anti-spoofing, voice deepfakes, voice cloning, linguistic shift, biometric authenticationAbstract
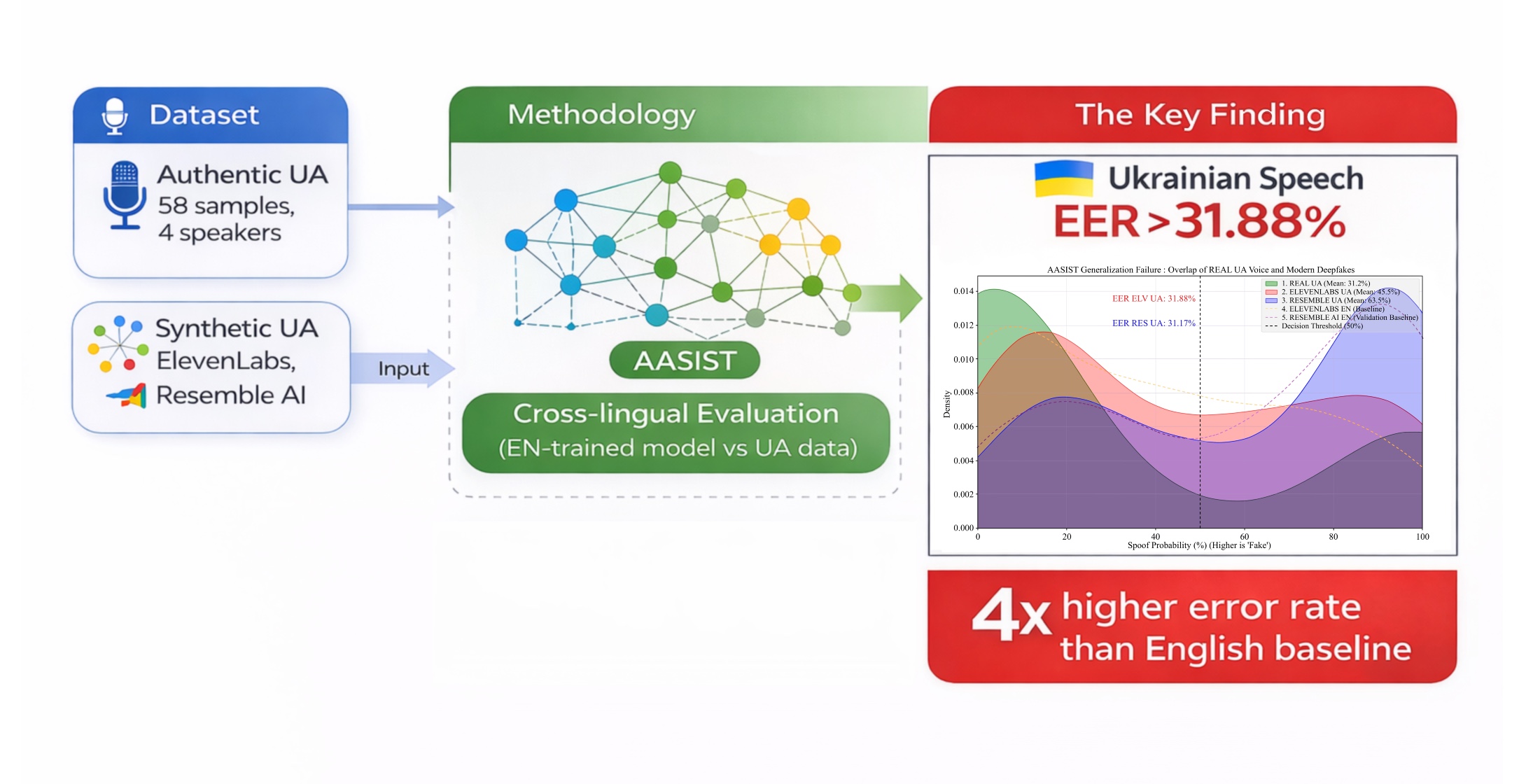
The research object is the processes and algorithms of automated discrimination between real and synthesized speech (anti-spoofing systems) when they function in conditions of a pronounced linguistic shift. The research solves the scientific and practical issue of quantitatively assessing the critical degradation of the precision of modern neurolinguistic detectors, using the example of the AASIST architecture with graph attention, when they encounter high-quality voice attacks in the Ukrainian. Special attention was paid to attacks formed using industrial new-generation neural vocoders, which are practically not represented in classic English training samples.
The essence of the obtained results lies in establishing and mathematically confirming the existence of a significant “generalization gap” in cross-language testing. It was experimentally proven that the transition from the English acoustic domain into the Ukrainian domain causes the growth of the equal error rate (EER) coefficient by 2.5–3.5 times. In the most advanced synthesis systems, the EER reached a critical threshold of 25.64%, which indicates the loss of the system’s protective capabilities in this language domain.
These results were obtained through the usage of an experimental stand, which unites the AASIST model and closed-end commercial APIs of neural speech cloning. Unlike standard tests on archive databases, the suggested approach, using a specially EXT dataset that includes five independent attack groups, allowed for modeling real cyber threat scenarios.
In practice, these results can be used in the design of voice biometric authentication systems in the banking and governmental sectors of Ukraine and justify the mandatory necessity of linguistic adaptation and deep fine-tuning of classifiers using localized datasets to achieve the required level of information security.
References
- Rabhi, M., Bakiras, S., Di Pietro, R. (2024). Audio-deepfake detection: Adversarial attacks and countermeasures. Expert Systems with Applications, 250, 123941. https://doi.org/10.1016/j.eswa.2024.123941
- Vynogradov, I. (2025). Voice fake detection: modern techniques and applications for Ukrainian language. Measuring and computing devices in technological processes, 82 (2), 31–36. https://doi.org/10.31891/2219-9365-2025-82-5
- Marek, B., Kawa, P., Syga, P. (2024). Are audio DeepFake detection models polyglots? arXiv preprint. https://doi.org/10.48550/arXiv.2412.17924
- Liu, T., Kukanov, I., Pan, Z., Wang, Q., Sailor, H. B., Lee, K. A. (2024). Towards Quantifying and Reducing Language Mismatch Effects in Cross-Lingual Speech Anti-Spoofing. 2024 IEEE Spoken Language Technology Workshop (SLT), 1185–1192. https://doi.org/10.1109/slt61566.2024.10832142
- Moreno, V., Lima, J., Simões, F., Violato, R., Neto, M. U., Runstein, F., Costa, P. (2025). Revealing Cross-Lingual Bias in Synthetic Speech Detection under Controlled Conditions. 5th Symposium on Security and Privacy in Speech Communication, 1–7. https://doi.org/10.21437/spsc.2025-1
- Kong, J., Kim, J., Bae, J. H. (2020). HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis. Advances in Neural Information Processing Systems (NeurIPS), 33. Available at: https://doi.org/arXiv:2010.05646
- Wang, X., Delgado, H., Tak, H., Jung, J., Shim, H., Todisco, M. et al. (2024). ASVspoof 5: crowdsourced speech data, deepfakes, and adversarial attacks at scale. The Automatic Speaker Verification Spoofing Countermeasures Workshop (ASVspoof 2024), 1–8. https://doi.org/10.21437/asvspoof.2024-1
- Delgado, H., Evans, N., Kinnunen, T., Lee, K. A., Liu, X., Nautsch, A. et al. (2021). ASVspoof 2021 Evaluation Plan. arXiv preprint. Available at: https://www.asvspoof.org/asvspoof2021/asvspoof2021_evaluation_plan.pdf
- Todisco, M., Delgado, H., Evans, N. (2017). Constant Q cepstral coefficients: A spoofing countermeasure for automatic speaker verification. Computer Speech & Language, 45, 516–535. https://doi.org/10.1016/j.csl.2017.01.001
- Tak, H., Patino, J., Todisco, M., Nautsch, A., Evans, N., Larcher, A. (2021). End-to-End anti-spoofing with RawNet2. ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 6369–6373. https://doi.org/10.1109/icassp39728.2021.9414234
- Tak, H., Jung, J., Patino, J., Kamble, M., Todisco, M., Evans, N. (2021). End-to-end spectro-temporal graph attention networks for speaker verification anti-spoofing and speech deepfake detection. 2021 Edition of the Automatic Speaker Verification and Spoofing Countermeasures Challenge, 1–8. https://doi.org/10.21437/asvspoof.2021-1
- Jung, J., Heo, H.-S., Tak, H., Shim, H., Chung, J. S., Lee, B.-J. et al. (2022). AASIST: Audio Anti-Spoofing Using Integrated Spectro-Temporal Graph Attention Networks. ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 6367–6371. https://doi.org/10.1109/icassp43922.2022.9747766
- Tak, H., Todisco, M., Wang, X., Jung, J., Yamagishi, J., Evans, N. (2022). Automatic Speaker Verification Spoofing and Deepfake Detection Using Wav2vec 2.0 and Data Augmentation. The Speaker and Language Recognition Workshop (Odyssey 2022), 112–119. https://doi.org/10.21437/odyssey.2022-16
- Zhang, Q., Wen, S., Hu, T. (2024). Audio Deepfake Detection with Self-Supervised XLS-R and SLS Classifier. Proceedings of the 32nd ACM International Conference on Multimedia, 6765–6773. https://doi.org/10.1145/3664647.3681345
- Models. ElevenLabs. Available at: https://elevenlabs.io/docs/models
- Dubbing. ElevenLabs. Available at: https://elevenlabs.io/docs/capabilities/dubbing
- Realtime Text-to-Speech AI Voice Generator built for Voice Agents. Resemble AI. Available at: https://www.resemble.ai/text-to-speech-converter/
- Ukrainian Text-to-Speech and AI Voice Generator. Resemble AI. Available at: https://www.resemble.ai/ukrainian-tts/
- What's new in Azure Speech in Foundry Tools? Microsoft Learn. Available at: https://learn.microsoft.com/azure/ai-services/speech-service/releasenotes
- Gemini-TTS. Chirp 3 HD – Supported languages (uk-UA). Google Cloud. Available at: https://cloud.google.com/text-to-speech/docs/gemini-tts
- Language Support – Languages supported by Speechify Text-to-Speech API. Speechify. Available at: https://docs.sws.speechify.com/docs/features/language-support
- Bringing technology to life. ElevenLabs. Available at: https://elevenlabs.io
- Bringing technology to life. Resemble AI. Available at: https://www.resemble.ai
- Kinnunen, T., Lee, K. A., Delgado, H., Evans, N., Todisco, M., Sahidullah, M. et al. (2018). t-DCF: a Detection Cost Function for the Tandem Assessment of Spoofing Countermeasures and Automatic Speaker Verification. The Speaker and Language Recognition Workshop (Odyssey 2018), 312–319. https://doi.org/10.21437/odyssey.2018-44
- Wang, X., Yamagishi, J., Todisco, M., Delgado, H., Nautsch, A., Evans, N. et al. (2020). ASVspoof 2019: A large-scale public database of synthesized, converted and replayed speech. Computer Speech & Language, 64, 101114. https://doi.org/10.1016/j.csl.2020.101114
- Yi, J., Wang, C., Tao, J., Zhang, X., Zhang, C. Y., Zhao, Y. (2023). Audio Deepfake Detection: A Survey. Journal of Latex Class Files, 14 (8). https://doi.org/10.48550/arXiv.2308.14970
- Yamagishi, J., Wang, X., Todisco, M., Sahidullah, M., Patino, J., Nautsch, A. et al. (2021). ASVspoof 2021: accelerating progress in spoofed and deepfake speech detection. 2021 Edition of the Automatic Speaker Verification and Spoofing Countermeasures Challenge, 47–54. https://doi.org/10.21437/asvspoof.2021-8
- Müller, N. M., Czempin, P., Dieckmann, J., Froghyar, A., Böttinger, K. (2022). Does Audio Deepfake Detection Generalize? https://doi.org/10.48550/arXiv.2203.16263
- Liu, X., Wang, X., Sahidullah, M., Patino, J., Delgado, H., Kinnunen, T. et al. (2023). ASVspoof 2021: Towards Spoofed and Deepfake Speech Detection in the Wild. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31, 2507–2522. https://doi.org/10.1109/taslp.2023.3285283
- Voicefakedetector. GitHub repository. Available at: https://github.com/ipvinner/voicefakedetector Last accessed: 22.12.2025
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2026 Ivan Vynogradov

This work is licensed under a Creative Commons Attribution 4.0 International License.
The consolidation and conditions for the transfer of copyright (identification of authorship) is carried out in the License Agreement. In particular, the authors reserve the right to the authorship of their manuscript and transfer the first publication of this work to the journal under the terms of the Creative Commons CC BY license. At the same time, they have the right to conclude on their own additional agreements concerning the non-exclusive distribution of the work in the form in which it was published by this journal, but provided that the link to the first publication of the article in this journal is preserved.