Розробка методу адаптивної реконфігурації систем потокового опрацювання даних на основі системних метрик
DOI:
https://doi.org/10.15587/2706-5448.2025.344185Ключові слова:
розподілені системи, потокове опрацювання даних, Kafka Streams, адаптивність, динамічність, RocksDBАнотація
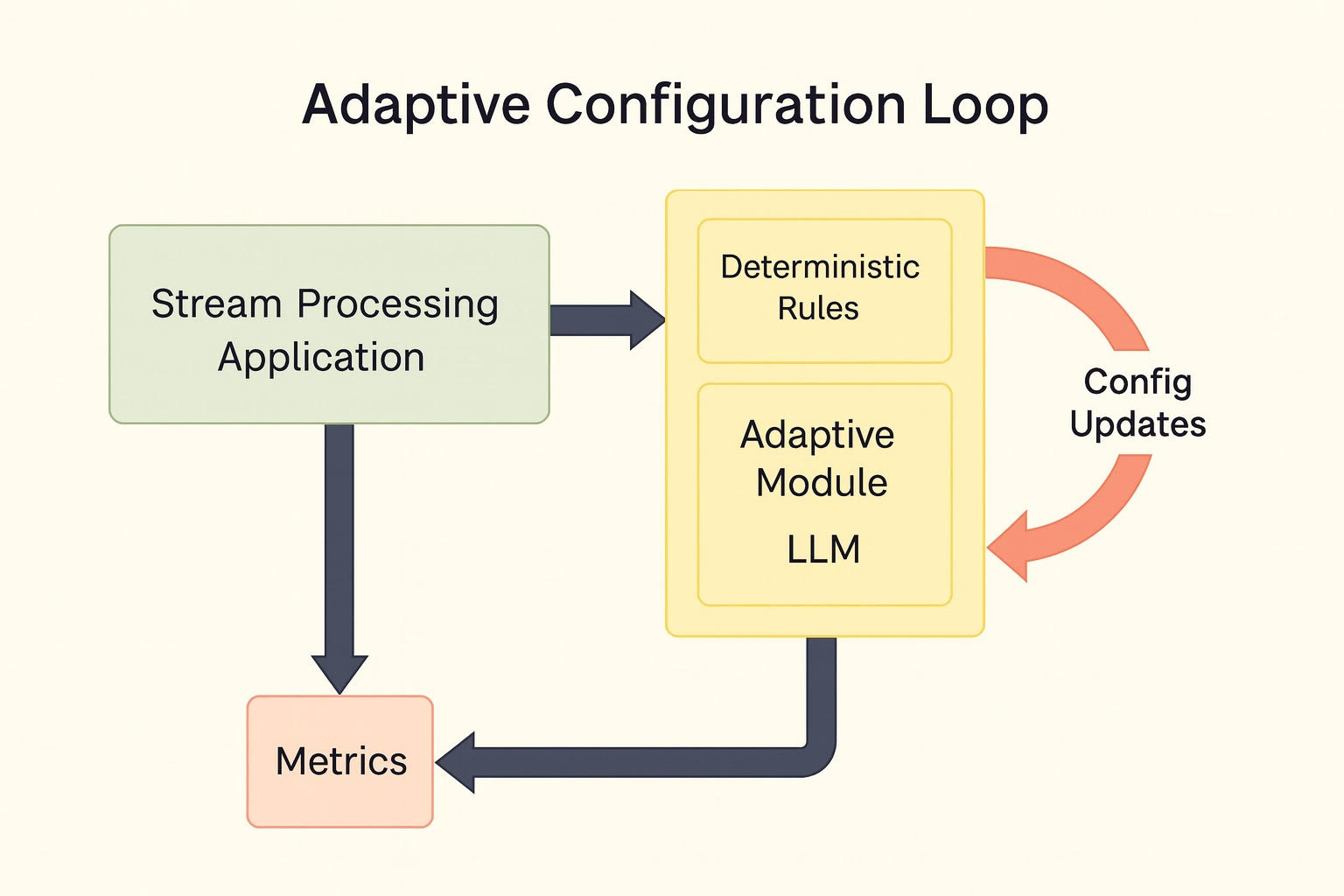
Об’єктом дослідження є процес адаптивної зміни налаштувань для систем потокового опрацювання даних задля покращення окремих характеристик додатків. Проблема, яка вирішувалась в цій роботі, полягає у відсутності універсального підходу до автоматичного оновлення конфігурацій сховищ стану під час роботи застосунків. Зокрема, можливість адаптації без залучення програмних інженерів. Рішення реалізовано для Kafka Streams, але спроєктоване як портоване до інших фреймворків, що використовують RocksDB як сховище стану. Системи потокового опрацювання працюють на статичних конфігураціях, що обмежує їхню ефективність при зміні навантаження. У цьому дослідженні запропоновано адаптивний модуль, який спостерігає за системними метриками та оновлює параметри сховища стану без втручання оператора. Модуль відстежує метрики застосунку, застосовує детерміністичні правила, а за неоднозначних ситуацій використовує донавчену LLM (Large Language Model) для вибору нових значень конфігурацій. Після цього метод динамічно оновлює налаштування та перезапускає відповідний інстанс. У середовищі експериментів адаптивні запуски усунули затримки запису, підвищили частку влучань у memtable з 2% до 40% та у кеш блоків – з 15% до 80%, зменшили дискові навантаження приблизно вдвічі та збільшили пропускну здатність приблизно на 5%, за рахунок підвищеного використання оперативної пам’яті. Для уникнення виняткових ситуацій, а також хибних адаптацій було використано експериментально обґрунтоване 10-хвилинне вікно спостереження. Метод підходить для систем із фіксованими ресурсами, навантаженням із великою кількістю різних ключів та потребою у безпечній автоматизації з обмеженнями. Архітектура є універсальною й може застосовуватися не лише для Kafka Streams, а й для інших фреймворків зі сховищами типу RocksDB.
Посилання
- Fragkoulis, M., Carbone, P., Kalavri, V., Katsifodimos, A. (2023). A survey on the evolution of stream processing systems. The VLDB Journal, 33 (2), 507–541. https://doi.org/10.1007/s00778-023-00819-8
- Checkpointing. Apache Flink. Available at: https://nightlies.apache.org/flink/flink-docs-master/docs/dev/datastream/fault-tolerance/checkpointing/ Last accessed: 27.10.2025
- Bashtovyi, A., Fechan, A. (2023). Change Data capture for migration to event-driven microservices Case Study. 2023 IEEE 18th International Conference on Computer Science and Information Technologies (CSIT). IEEE, 1–4. https://doi.org/10.1109/csit61576.2023.10324262
- Vyas, S., Tyagi, R. K., Sahu, S. (2023). Fault Tolerance and Error Handling Techniques in Apache Kafka. Proceedings of the 5th International Conference on Information Management & Machine Intelligence. Association for Computing Machinery, 1–5. https://doi.org/10.1145/3647444.3647844
- A persistent key-value store for fast storage environments. RocksDB. Available at: https://rocksdb.org/ Last accessed: 27.10.2025
- Cardellini, V., Lo Presti, F., Nardelli, M., Russo, G. R. (2022). Runtime Adaptation of Data Stream Processing Systems: The State of the Art. ACM Computing Surveys, 54 (11s), 1–36. https://doi.org/10.1145/3514496
- Herodotou, H., Odysseos, L., Chen, Y., Lu, J. (2022). Automatic Performance Tuning for Distributed Data Stream Processing Systems. 2022 IEEE 38th International Conference on Data Engineering (ICDE). IEEE, 3194–3197. https://doi.org/10.1109/icde53745.2022.00296
- Venkataraman, S., Panda, A., Ousterhout, K., Armbrust, M., Ghodsi, A., Franklin, M. J. et al. (2017). Drizzle. Proceedings of the 26th Symposium on Operating Systems Principles. Association for Computing Machinery, 374–389. https://doi.org/10.1145/3132747.3132750
- Geldenhuys, M., Pfister, B., Scheinert, D., Thamsen, L., Kao, O. (2022). Khaos: Dynamically Optimizing Checkpointing for Dependable Distributed Stream Processing. Proceedings of the 17th Conference on Computer Science and Intelligence Systems, 30, 553–561. https://doi.org/10.15439/2022f225
- Sun, D., Peng, J., Zhu, T., Kua, J., Gao, S., Buyya, R. (2025). Toward High‐Availability Distributed Stream Computing Systems via Checkpoint Adaptation. Concurrency and Computation: Practice and Experience, 37 (15-17). https://doi.org/10.1002/cpe.70171
- Liu, J., Gulisano, V. (2025). On-demand Memory Compression of Stream Aggregates through Reinforcement Learning. Proceedings of the 16th ACM/SPEC International Conference on Performance Engineering. Association for Computing Machinery, 240–252. https://doi.org/10.1145/3676151.3719369
- Wladdimiro, D., Arantes, L., Sens, P., Hidalgo, N. (2024). PA-SPS: A predictive adaptive approach for an elastic stream processing system. Journal of Parallel and Distributed Computing, 192, 104940. https://doi.org/10.1016/j.jpdc.2024.104940
- Hovorushchenko, T., Medzatyi, D., Voichur, Y., Lebiga, M. (2023). Method for forecasting the level of software quality based on quality attributes. Journal of Intelligent & Fuzzy Systems, 44 (3), 3891–3905. https://doi.org/10.3233/jifs-222394
- How to Tune RocksDB for Your Kafka Streams Application (2021). Confluent. Available at: https://www.confluent.io/blog/how-to-tune-rocksdb-kafka-streams-state-stores-performance/ Last accessed: 27.10.2025
- Oh, S., Moon, G. E., Park, S. (2024). ML-Based Dynamic Operator-Level Query Mapping for Stream Processing Systems in Heterogeneous Computing Environments. 2024 IEEE International Conference on Cluster Computing (CLUSTER). IEEE, 226–237. https://doi.org/10.1109/cluster59578.2024.00027
- Vysotska, V., Kyrychenko, I., Demchuk, V., Gruzdo, I. (2024). Holistic Adaptive Optimization Techniques for Distributed Data Streaming Systems. Proceedings of the 8th International Conference on Computational Linguistics and Intelligent Systems. Volume II: Modeling, Optimization, and Controlling in Information and Technology Systems Workshop (MOCITSW-CoLInS 2024). https://doi.org/10.31110/colins/2024-2/009
- Dong, S., Kryczka, A., Jin, Y., Stumm, M. (2021). RocksDB: Evolution of Development Priorities in a Key-value Store Serving Large-scale Applications. ACM Transactions on Storage, 17 (4), 1–32. https://doi.org/10.1145/3483840
- Bashtovyi, A. V., Fechan, A. V. (2025). Evaluating fault recovery in distributed applications for stream processing applications: business insights based on metrics. Radio Electronics, Computer Science, Control, 3, 17–27. https://doi.org/10.15588/1607-3274-2025-3-2
##submission.downloads##
Опубліковано
Як цитувати
Номер
Розділ
Ліцензія
Авторське право (c) 2025 Artem Bashtovyi, Andrii Fechan

Ця робота ліцензується відповідно до Creative Commons Attribution 4.0 International License.
Закріплення та умови передачі авторських прав (ідентифікація авторства) здійснюється у Ліцензійному договорі. Зокрема, автори залишають за собою право на авторство свого рукопису та передають журналу право першої публікації цієї роботи на умовах ліцензії Creative Commons CC BY. При цьому вони мають право укладати самостійно додаткові угоди, що стосуються неексклюзивного поширення роботи у тому вигляді, в якому вона була опублікована цим журналом, але за умови збереження посилання на першу публікацію статті в цьому журналі.