Розробка алгоритму пошуку дублікатів в програмному коді на базі абстрактного синтаксичного дерева
DOI:
https://doi.org/10.15587/2706-5448.2023.286472Ключові слова:
виявлення клонів, абстрактне синтаксичне дерево, AST, хешування, пошук вразливостей, помилкові сигналиАнотація
Об'єктом дослідження даної роботи є алгоритм пошуку дублікатів в програмному коді на базі абстрактного синтаксичного дерева (Abstract Syntaxes Tree – AST). Головними задачами, що вирішувалися в рамках даного дослідження, є виявлення дублікатів коду та пошук вразливостей в програмному коді.
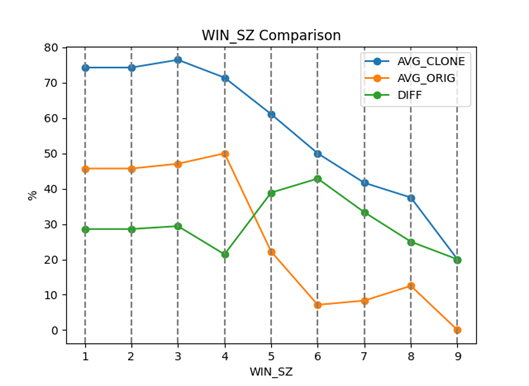
Отримані результати показали, що запропонований алгоритм є стійким до клонів типу 1 та 2, що означає його ефективність у виявленні схожих фрагментів коду з ідентичним або варіативним текстом. Проте, для клонів типу 3 та 4, алгоритм може показувати меншу ефективність через зміну структури AST для цих типів клонів.
Експериментальні дослідження запропонованого алгоритму показали, що алгоритм може виявляти співпадіння між непов'язаними файлами через наявність типових ланцюжків AST, що присутні у багатьох програмах. Це може призводити до певного рівня помилкових сигналів (False-Positive) у виявленні дублікатів.
Тестування алгоритму в задачі пошуку вразливостей показало, що:
- Найкраще розпізнавання спостерігається для вразливості «SQL-ін'єкція», але вона також має найбільшу кількість помилкових сигналів.
- Вразливості «виток пам'яті» та «розіменування нульового вказівника» розпізнаються з однаковою ефективністю та помилковими сигналами.
- «Переповнення буферу» має найнижчий показник розпізнавання, але меншу кількість помилкових сигналів порівняно з «SQL-ін'єкцією».
Дослідження показало, що використання AST дозволяє ефективно виявляти дублікати коду та вразливості в програмному коді. Розроблений інструмент може допомогти розробникам програмного забезпечення зменшити зусилля з обслуговування, покращити якість коду та забезпечити безпеку програмного продукту.
Посилання
- Koschke, R. (2007). Survey of research on software clones. In Dagstuhl Seminar Proceedings. Schloss Dagstuhl-Leibniz-Zentrum für Informatik. doi: https://doi.org/10.4230/DagSemProc.06301.13
- Kim, M., Bergman, L., Lau, T., Notkin, D. (2004). An ethnographic study of copy and paste programming practices in OOPL. Proceedings. 2004 International Symposium on Empirical Software Engineering. ISESE'04, 83–92. doi: https://doi.org/10.1109/isese.2004.1334896
- Ain, Q. U., Butt, W. H., Anwar, M. W., Azam, F., Maqbool, B. (2019). A Systematic Review on Code Clone Detection. IEEE Access, 7, 86121–86144. doi: https://doi.org/10.1109/access.2019.2918202
- Kal Viertel, F. P., Brunotte, W., Strüber, D., Schneider, K. (2019). Detecting Security Vulnerabilities using Clone Detection and Community Knowledge. International Conferences on Software Engineering and Knowledge Engineering, 245–324. doi: https://doi.org/10.18293/seke2019-183
- Nishi, M. A., Damevski, K. (2018). Scalable code clone detection and search based on adaptive prefix filtering. Journal of Systems and Software, 137, 130–142. doi: https://doi.org/10.1016/j.jss.2017.11.039
- Kaliuzhna, T., Kubiuk, Y. (2022). Analysis of machine learning methods in the task of searching duplicates in the software code. Technology Audit and Production Reserves, 4 (2 (66)), 6–13. doi: https://doi.org/10.15587/2706-5448.2022.263235
- Singh, M., Sharma, V. (2015). Detection of File Level Clone for High Level Cloning. Procedia Computer Science, 57, 915–922. doi: https://doi.org/10.1016/j.procs.2015.07.509
- Yang, Y., Ren, Z., Chen, X., Jiang, H. (2018). Structural function based code clone detection using a new hybrid technique. 2018 IEEE 42nd annual computer software and applications conference (COMPSAC), 1, 286–291. doi: https://doi.org/10.1109/compsac.2018.00045
- NVD. Available at: https://nvd.nist.gov/ Last accessed: 22.07.2023
- Li, Z., Zou, D., Xu, S., Ou, X., Jin, H., Wang, S. et al. (2018). VulDeePecker: A Deep Learning-Based System for Vulnerability Detection. Proceedings 2018 Network and Distributed System Security Symposium. doi: https://doi.org/10.14722/ndss.2018.23158
- Chrenousov, A., Savchenko, A., Osadchyi, S., Kubiuk, Y., Kostenko, Y., Likhomanov, D. (2019). Deep learning based automatic software defects detection framework. Theoretical and Applied Cybersecurity, 1 (1). doi: https://doi.org/10.20535/tacs.2664-29132019.1.169086
- Appel, A. W. (2015). Verification of a Cryptographic Primitive. ACM Transactions on Programming Languages and Systems, 37 (2), 1–31. doi: https://doi.org/10.1145/2701415
##submission.downloads##
Опубліковано
Як цитувати
Номер
Розділ
Ліцензія
Авторське право (c) 2023 Yevhenii Kubiuk, Gennadiy Kyselov

Ця робота ліцензується відповідно до Creative Commons Attribution 4.0 International License.
Закріплення та умови передачі авторських прав (ідентифікація авторства) здійснюється у Ліцензійному договорі. Зокрема, автори залишають за собою право на авторство свого рукопису та передають журналу право першої публікації цієї роботи на умовах ліцензії Creative Commons CC BY. При цьому вони мають право укладати самостійно додаткові угоди, що стосуються неексклюзивного поширення роботи у тому вигляді, в якому вона була опублікована цим журналом, але за умови збереження посилання на першу публікацію статті в цьому журналі.






