Development of clustering models for extended opinion holders based on aggregated stylometric and sentiment features of chat messages
DOI:
https://doi.org/10.15587/2706-5448.2025.344630Keywords:
clustering models, natural language processing, semantic and sentiment analysis, explainable artificial intelligenceAbstract
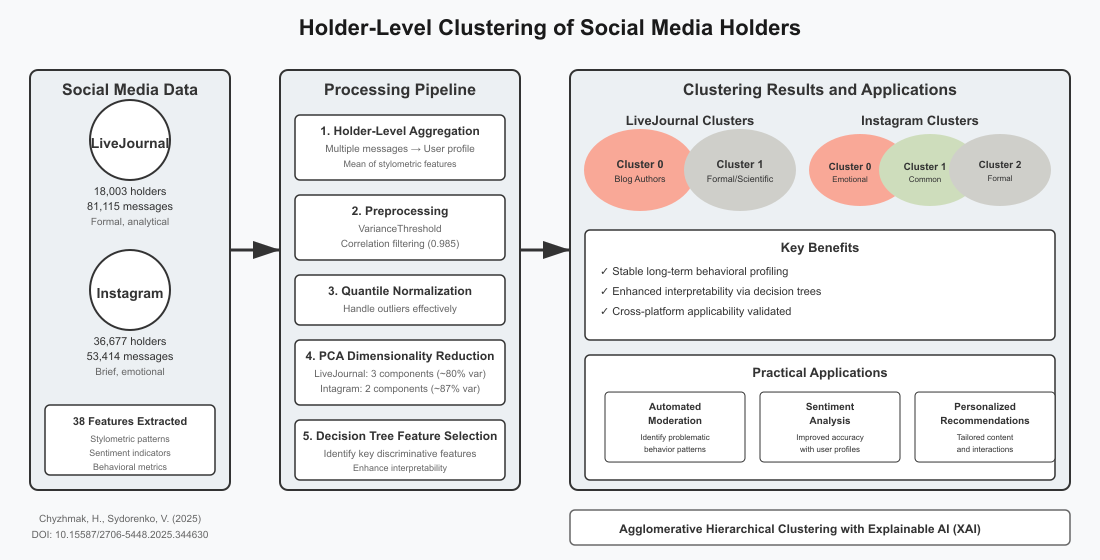
The subject of research is the methods and technologies for monitoring holder opinion groups in social media based on stylometric and sentiment features. One of the most important problems is the increasing complexity of text content, which makes user behavior analysis more difficult because of anonymity, informal language, slang, emojis, and non-standard writing styles. Stable, long-term behavioral patterns are not captured by methods based on single-message evaluation.
This research proposes a holder-level clustering method based on aggregated stylometric and sentiment features taken from several messages per user. The methodology includes agglomerative hierarchical clustering, which is enhanced by decision tree analysis for feature selection and cluster interpretability, quantile normalization, dimensionality reduction via PCA (LiveJournal provided six components explaining 81.7% of the variance, while Instagram provided four components explaining 83.5% of the variance), and data preprocessing (VarianceThreshold, removal of highly correlated features). Ultimately, the majority of users were covered by two clusters for LiveJournal and three clusters for Instagram. The result is a set of clustering models that efficiently group holders into logical, understandable clusters based on their overall communication style and emotional expression. The primary advantages of the proposed approach are as follows: holder-level aggregation ensures stability and consistency in profiling; two-stage clustering with intermediate feature selection enhances explainability; the method demonstrates cross-platform applicability, validated on both LiveJournal and Instagram. As a result, over time, more accurate and dynamic user profiles can be developed, enabling improved sentiment analysis, automated moderation, and customized user interaction. This approach offers significant benefits over conventional single-message analysis methods in terms of results transparency, behavioral insight depth, and profile stability. Customized social media recommendations, automated moderation, and social sentiment analysis can all benefit from the study's findings.
References
- Sydorenko, V., Kravchenko, S., Rychok, Y., Zeman, K. (2020). Method of Classification of Tonal Estimations Time Series in Problems of Intellectual Analysis of Text Content. Transportation Research Procedia, 44, 102–109. https://doi.org/10.1016/j.trpro.2020.02.015
- Sydorenko, V., Rychok, Y., Oladko, M. (2022). Method for Evaluation the Pattern of Internet Service Customers Based on Stylometric Analysis Oof their Text Content. 2022 IEEE 4th International Conference on Modern Electrical and Energy System (MEES), 1–6. https://doi.org/10.1109/mees58014.2022.10005654
- F. Mosteller and D.L. Wallace Inference and Disputed Authorship; The Federalist. Addison-Wesley Series in Behavioral Science; Quantitative Methods. Reading, Mass., Palo Alto, London, Addison-Wesley Publishing Company, Inc., 1964, XV p. 287 p., $ 12.50. (1965). Recherches Économiques de Louvain, 31 (8), 721–721. https://doi.org/10.1017/s0770451800020777
- Stamatatos, E. (2008). A survey of modern authorship attribution methods. Journal of the American Society for Information Science and Technology, 60 (3), 538–556. https://doi.org/10.1002/asi.21001
- Rangel, F., Rosso, P., Koppel, M., Stamatatos, E., Inches, G. (2013). Overview of the Author Profiling Task at PAN 2013. Working Notes of CLEF 2013 Conference. Valencia: CEUR, 1179. https://ceur-ws.org/Vol-1179/CLEF2013wn-PAN-RangelEt2013.pdf
- Giorgi, S., Preoţiuc-Pietro, D., Buffone, A., Rieman, D., Ungar, L., Schwartz, H. A. (2018). The Remarkable Benefit of User-Level Aggregation for Lexical-based Population-Level Predictions. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels: Association for Computational Linguistics, 1167–1172. https://doi.org/10.18653/v1/d18-1148
- Chyzhmak, H., Sydorenko, V. (2023). Classification models of direct opinion holders in the space of stylometric and sentiment features of chat messages. 2023 IEEE 5th International Conference on Modern Electrical and Energy System (MEES), 1–6. https://doi.org/10.1109/mees61502.2023.10402395
- Rychok, Yu. S., Sydorenko, V. M. (2021). Model otsinky sentyment-komponent u zadachakh sentyment-analizu skladnoho tekstovoho kontenta. Fizychni protsesy ta polia tekhnichnykh i biolohichnykh obiektiv. Kremenchuk, 83–86.
- LiveJournal. Available at: https://www.livejournal.com/
- Instagram. Available at: https://www.instagram.com
- Ali, S., Abuhmed, T., El-Sappagh, S., Muhammad, K., Alonso-Moral, J. M., Confalonieri, R. et al. (2023). Explainable Artificial Intelligence (XAI): What we know and what is left to attain Trustworthy Artificial Intelligence. Information Fusion, 99, 101805. https://doi.org/10.1016/j.inffus.2023.101805
- GitHub – agentcooper/node-livejournal: LiveJournal API. Available at: https://github.com/agentcooper/node-livejournal
- 7 000 000 Russian comments from Instagram (2025). Available at: https://t.me/danokhlopkov/395
- VarianceThreshold. Scikit-learn. Available at: https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.VarianceThreshold.html
- Kuhn, M., Johnson, K. (2013). Applied Predictive Modeling. New York: Springer. https://doi.org/10.1007/978-1-4614-6849-3
- Amaratunga, D., Cabrera, J. (2001). Analysis of Data From Viral DNA Microchips. Journal of the American Statistical Association, 96 (456), 1161–1170. https://doi.org/10.1198/016214501753381814
- Aitchison, J., Brown, J. A. C. (1958). The Lognormal Distribution. The Incorporated Statistician, 8 (3), 145. https://doi.org/10.2307/2986416
- Box, G. E. P., Cox, D. R. (1964). An analysis of transformations. Journal of the Royal Statistical Society, Series B, 26 (2), 211–252. Available at: http://www.econ.illinois.edu/~econ508/Papers/boxcox64.pdf
- Pearson, K. (1901). LIII. On lines and planes of closest fit to systems of points in space. The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science, 2 (11), 559–572. https://doi.org/10.1080/14786440109462720
- Nielsen, F. (2016). Hierarchical Clustering. Introduction to HPC with MPI for Data Science. Cham: Springer, 195–211. https://doi.org/10.1007/978-3-319-21903-5_8
- Rudin, C. (2019). Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nature Machine Intelligence, 1 (5), 206–215. https://doi.org/10.1038/s42256-019-0048-x
- Phillips, P. J., Hahn, C. A., Fontana, P. C., Yates, A. N., Greene, K., Broniatowski, D. A., Przybocki, M. A. (2021). Four principles of explainable artificial intelligence. National Institute of Standards and Technology. https://doi.org/10.6028/nist.ir.8312
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2025 Heorhii Chyzhmak, Valeriy Sydorenko

This work is licensed under a Creative Commons Attribution 4.0 International License.
The consolidation and conditions for the transfer of copyright (identification of authorship) is carried out in the License Agreement. In particular, the authors reserve the right to the authorship of their manuscript and transfer the first publication of this work to the journal under the terms of the Creative Commons CC BY license. At the same time, they have the right to conclude on their own additional agreements concerning the non-exclusive distribution of the work in the form in which it was published by this journal, but provided that the link to the first publication of the article in this journal is preserved.