Розгляд актуальних проблем автоматичного реферування текстів природної мови з використанням методів штучного інтелекту
DOI:
https://doi.org/10.15587/2706-5448.2024.309472Ключові слова:
автоматичне реферування, обробка природної мови, штучний інтелект, генеративні моделі, нейронні мережі, глибинне навчанняАнотація
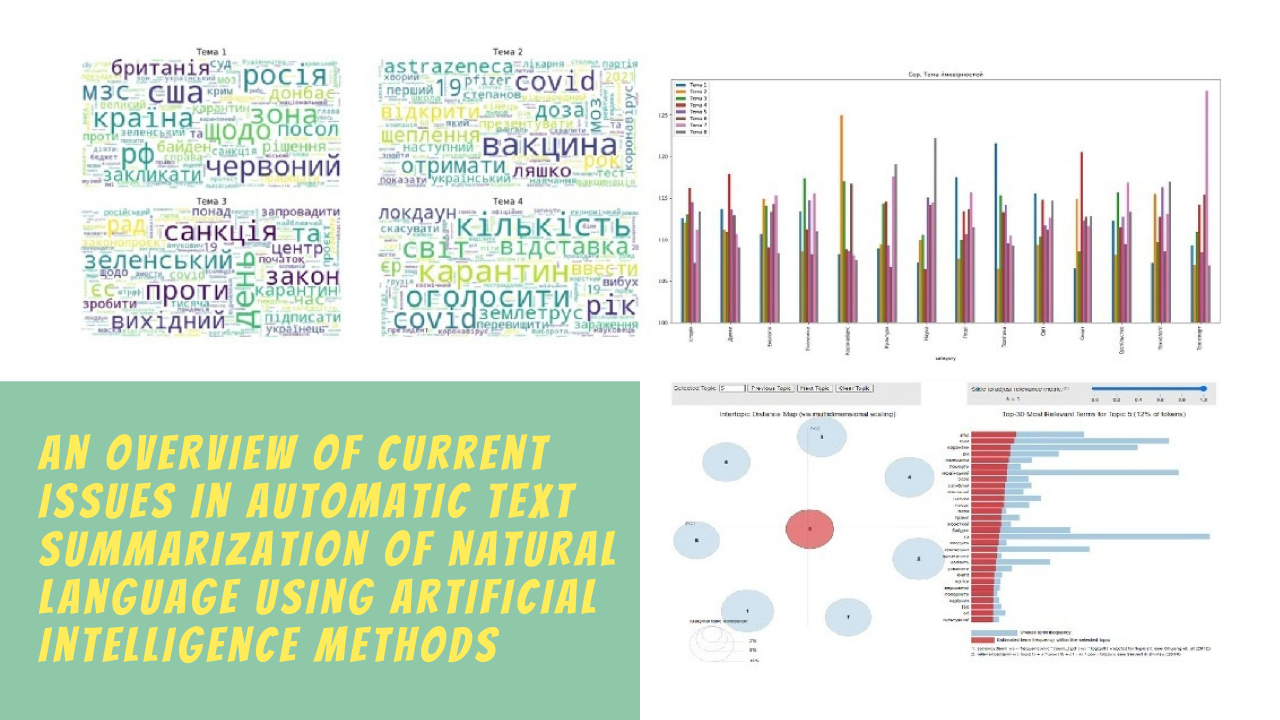
Об'єктом дослідження є задачі автоматичного реферування текстів природної мови. Важливість цих задач обумовлена наявною проблемою створення рефератів, які б адекватно відображали зміст оригінального тексту та виділяли ключову інформацію. Це завдання вимагає здатності моделей глибоко аналізувати контекст тексту, що ускладнює процес реферування.
Представлено результати, які демонструють ефективність використання генеративних моделей на основі нейронних мереж, методів аналізу семантики тексту та глибинного навчання для автоматичного створення рефератів. Використання моделей показало високий рівень адекватності та інформативності рефератів. GPT (Generative Pre-trained Transformer) генерує тексти, які виглядають як написані людиною, що робить його корисним для автоматичного створення рефератів.
Наприклад, модель GPT генерує скорочені реферати на основі введеного тексту, а модель BERT використовується для реферування текстів у багатьох областях, включаючи пошукові системи та обробку природної мови. Це дозволяє отримувати короткі, але інформативні реферати, які зберігають основний зміст оригіналу та забезпечує можливість отримання високоякісних рефератів, які можуть бути використані для реферування веб-сторінок, електронних листів, соціальних медіа та іншого контенту. У порівнянні з традиційними методами реферування, штучний інтелект забезпечує такі переваги, як більша точність, інформативність та здатність обробляти великі обсяги тексту ефективніше, що полегшує доступ до інформації та покращує продуктивність у обробці текстів.
Автоматичне реферування текстів з використанням моделей штучного інтелекту дозволяє значно скоротити час, необхідний для аналізу великих обсягів текстової інформації. Це особливо важливо у сучасному інформаційному середовищі, де кількість доступних даних постійно зростає. Використання цих моделей сприяє ефективному використанню ресурсів та підвищує загальну продуктивність у різних сферах, включаючи наукові дослідження, освіту, бізнес та медіа.
Посилання
- Pustejovsky, J., Stubbs, A. (2012). Natural Language Annotation for Machine Learning. Cambridge: Farnham, 343.
- Natural language processing. Available at: https://en.wikipedia.org/wiki/Natural_language_processing
- Luhn, H. P. (1958). The Automatic Creation of Literature Abstracts. IBM Journal of Research and Development, 2 (2), 159–165. https://doi.org/10.1147/rd.22.0159
- Guarino, N., Masolo, C., Vetere, G. (1999). Content-Based Access to the Web. IEEE Intelligent Systems, 70–80.
- Lin, C.-Y., Hovy, E. H. (2000). The Automated acquisition of topic signatures for text summarization. Proceedings of COLING-00. Saarbrücken, 495–501. https://doi.org/10.3115/990820.990892
- Deerwester, S., Dumais, S. T., Furnas, G. W., Landauer, T. K., Harshman, R. (1990). Indexing by latent semantic analysis. Journal of the American Society for Information Science, 41 (6), 391–407. https://doi.org/10.1002/(sici)1097-4571(199009)41:6<391::aid-asi1>3.0.co;2-9
- Gong, Y., Liu, X. (2001). Generic text summarization using relevance measure and latent semantic analysis. Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 19–25. https://doi.org/10.1145/383952.383955
- PageRank. Available at: https://en.wikipedia.org/wiki/PageRank
- Kupiec, J., Pedersen, J., Chen, F. (1995). A trainable document summarizer. Proceedings of the 18th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval – SIGIR ’95. ACM, 68–73. https://doi.org/10.1145/215206.215333
- Ouyang, Y., Li, W., Li, S., Lu, Q. (2011). Applying regression models to query-focused multi-document summarization. Information Processing & Management, 47 (2), 227–237. https://doi.org/10.1016/j.ipm.2010.03.005
- Wong, K.-F., Wu, M., Li, W. (2008). Extractive summarization using supervised and semi-supervised learning. Proceedings of the 22nd International Conference on Computational Linguistics – COLING ’08, 985–992. https://doi.org/10.3115/1599081.1599205
- Zhou, L., Hovy, E. (2003). A web-trained extraction summarization system. Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology – NAACL ’03, 205–211. https://doi.org/10.3115/1073445.1073482
- Conroy, J. M., O’leary, D. P. (2001). Text summarization via hidden Markov models. Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 406–407. https://doi.org/10.1145/383952.384042
- Shen, D., Sun, J.-T., Li, H., Yang, Q., Chen, Z. (2007). Document Summarization Using Conditional Random Fields. IJCAI, 7, 2862–2867.
- SummarizeBot. Available at: https://www.summarizebot.com/about.html
- SMMRY. Available at: https://smmry.com/about
- Generative Pre-trained Transformer. Available at: https://openai.com/chatgpt
- Devlin, J., Chang, M.-W. (2018). Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing. Available at: https://research.google/blog/open-sourcing-bert-state-of-the-art-pre-training-for-natural-language-processing/
- TextTeaser. Available at: https://pypi.org/project/textteaser/
- Answers to Frequently Asked Questions about NLTK (2022). Available at: https://github.com/nltk/nltk/wiki/FAQ
- Gensim. Available at: https://radimrehurek.com/gensim/intro.html#what-is-gensim
- SUMY. Available at: https://github.com/miso-belica/sumy
- Bert-Extractive-Summarizer. Available at: https://github.com/dmmiller612/bert-extractive-summarizer
- Ukrainska pravda. Available at: https://www.pravda.com.ua/
- Pymorphy2 0.9.1. Available at: https://pypi.org/project/pymorphy2/
- Support vector machine. Available at: https://en.wikipedia.org/wiki/Support_vector_machine
- Tag Cloud. Available at: https://en.wikipedia.org/wiki/Tag_cloud
##submission.downloads##
Опубліковано
Як цитувати
Номер
Розділ
Ліцензія
Авторське право (c) 2024 Oleksii Kuznietsov, Gennadiy Kyselov

Ця робота ліцензується відповідно до Creative Commons Attribution 4.0 International License.
Закріплення та умови передачі авторських прав (ідентифікація авторства) здійснюється у Ліцензійному договорі. Зокрема, автори залишають за собою право на авторство свого рукопису та передають журналу право першої публікації цієї роботи на умовах ліцензії Creative Commons CC BY. При цьому вони мають право укладати самостійно додаткові угоди, що стосуються неексклюзивного поширення роботи у тому вигляді, в якому вона була опублікована цим журналом, але за умови збереження посилання на першу публікацію статті в цьому журналі.






