Розроблення підходу ДО створення спеціалізованого словника для тренування чат-ботів з генеративним штучним інтелектом
DOI:
https://doi.org/10.15587/1729-4061.2026.351414Ключові слова:
велика мовна модель, предметно-специфічні знання, управління термінологією, семантична узгодженістьАнотація
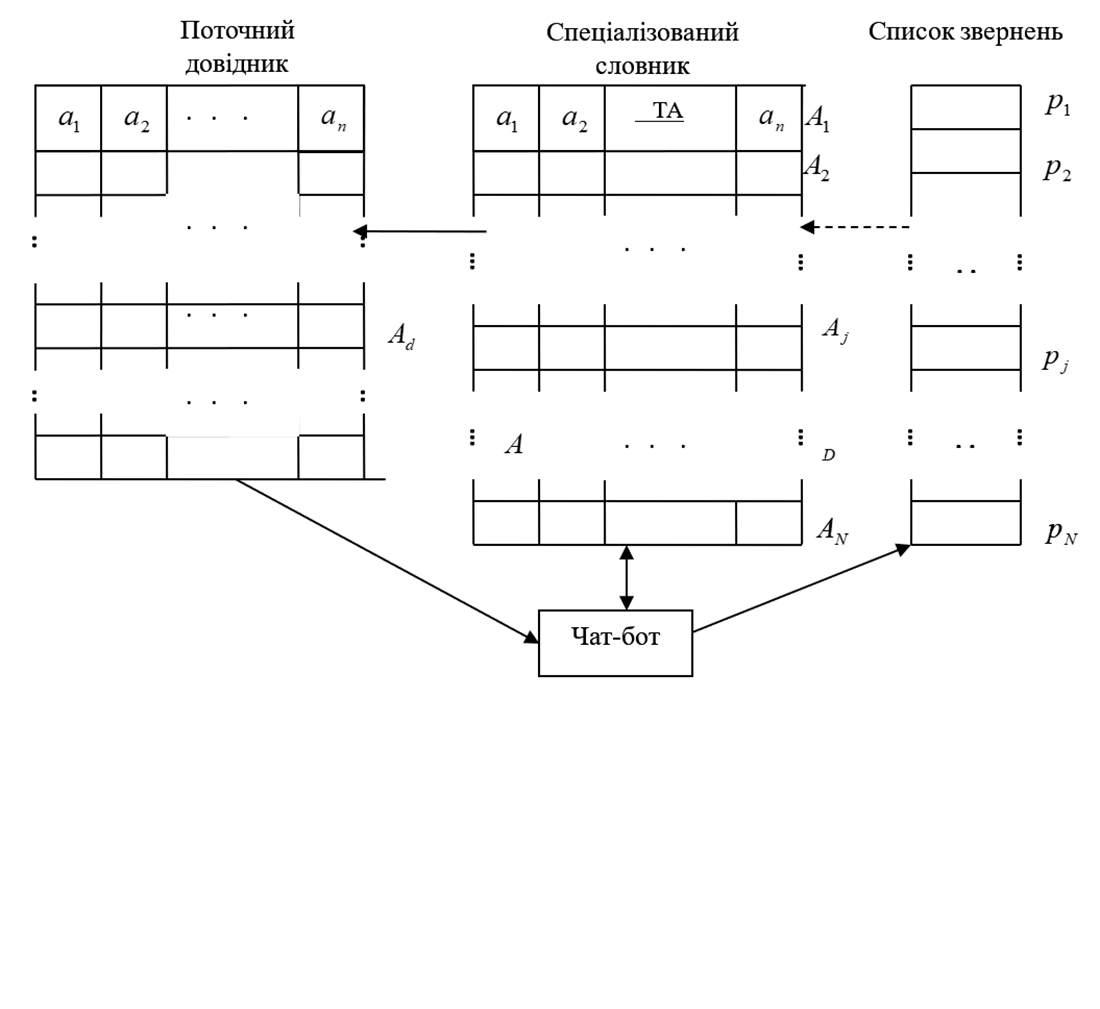
Об’єктом дослідження є процес формування предметно-специфічного навчального словника для тренування чат-боту з генеративним штучним інтелектом. В роботі вирішувалася проблема відтворення характерної для відповідної предметної області структурованості лексики з предметно-специфічних знань при взаємодії з чат-ботом. Результатом роботи є формування моделі процесу послідовної обробки незалежних користувацьких звернень. Модель дозволила оцінити математичне очікування номера етапу, на якому завершується обробка запиту чат-ботом. На основі побудованої математичної моделі запропоновані лінійна та логіко-ймовірнісна моделі формування спеціалізованого словника. За лінійною моделлю здійснюється пошук комбінації слів за послідовним перебором термінів. Підсумком такого підходу є зіставлення ключового слова запиту з відповідним терміном або словоформою зі словника. Логіко-ймовірнісна модель базується на осередку цілі – ймовірному слову із запита користувача. Це пояснюється можливістю визначення слова, що узгоджується з терміном XML-словника та має максимальну релевантність до користувацького запиту. Запропоновано методику та алгоритм побудови спеціалізованого словника. Проведені випробування дозволили отримати середньосигнатурні значення відповіді з похибкою 0,004% та забезпечити стабільність результатів. На практиці подібне може бути використане за умов формування ймовірнісного розподілу можливих словесних комбінацій для генерації відповіді.
Запропонований підхід може бути використаний у практичних задачах доменної адаптації чат-ботів, зокрема на порталах підтримки проєктів і в наукових бібліотеках, а також для вдосконалення інтелектуальних діалогових систем, орієнтованих на формування уточнених користувацьких запитів
Посилання
- Yang, C., Zhao, R., Liu, Y., Jiang, L. (2025). Survey of specialized large language model. arXiv. https://arxiv.org/abs/2508.19667
- Adavala, K. M., Adavala, O. (2025). Domain-specific knowledge and context in large language models: challenges, concerns, and solutions. IAES International Journal of Artificial Intelligence (IJ-AI), 14 (4), 2568. https://doi.org/10.11591/ijai.v14.i4.pp2568-2578
- Zhu, Y., Yuan, H., Wang, S., Liu, J., Liu, W., Deng, C. et al. (2025). Large Language Models for Information Retrieval: A Survey. ACM Transactions on Information Systems, 44 (1), 1–54. https://doi.org/10.1145/3748304
- Ai, Q., Bai, T., Cao, Z., Chang, Y., Chen, J., Chen, Z. et al. (2023). Information Retrieval meets Large Language Models: A strategic report from Chinese IR community. AI Open, 4, 80–90. https://doi.org/10.1016/j.aiopen.2023.08.001
- Sharma, K., Kumar, P., Li, Y. (2025). OG-RAG: Ontology-grounded retrieval-augmented generation for large language models. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 32950–32969. https://doi.org/10.18653/v1/2025.emnlp-main.1674
- Manda, P. (2025). Large Language Models in Bio-Ontology Research: A Review. Bioengineering, 12 (11), 1260. https://doi.org/10.3390/bioengineering12111260
- Barron, R. C., Grantcharov, V., Wanna, S., Eren, M. E., Bhattarai, M., Solovyev, N. et al. (2024). Domain-Specific Retrieval-Augmented Generation Using Vector Stores, Knowledge Graphs, and Tensor Factorization. 2024 International Conference on Machine Learning and Applications (ICMLA), 1669–1676. https://doi.org/10.1109/icmla61862.2024.00258
- Fareedi, A. A., Ismail, M., Ahmed, S., Gagnon, S., Ghazawneh, A., Arooj, Z., Nazir, H. (2025). Enriching Human–AI Collaboration: The Ontological Service Framework Leveraging Large Language Models for Value Creation in Conversational AI. Knowledge, 6 (1), 2. https://doi.org/10.3390/knowledge6010002
- Mukanova, A., Nazyrova, A., Zulkhazhav, A., Lamasheva, Z., Dauletkaliyeva, A. (2025). Development of an Intelligent Information Retrieval System Based on Ontology, Linguistic Algorithms and Large Language Models. Applied Sciences, 15 (22), 12271. https://doi.org/10.3390/app152212271
- Ahmad, J. M., Liu, Y., Kim, J.-D., Yao, X., Larmande, P., Xia, J. (2025). A curation system of rice trait ontology with reliable interoperation by LLM and PubAnnotation. Genomics & Informatics, 23 (1). https://doi.org/10.1186/s44342-025-00058-z
- Chen, L.-C., Pardeshi, M. S., Liao, Y.-X., Pai, K.-C. (2025). Application of retrieval-augmented generation for interactive industrial knowledge management via a large language model. Computer Standards & Interfaces, 94, 103995. https://doi.org/10.1016/j.csi.2025.103995
- Wen, J., Liu, D., Xie, Y., Ren, Y., Wang, J., Xia, Y., Zhu, P. (2025). AcuGPT-Agent: An LLM-powered intelligent system for acupuncture-based infertility treatment. Neurocomputing, 652, 131116. https://doi.org/10.1016/j.neucom.2025.131116
- Rodríguez-Muñoz-de-Baena, I., Coronado-Vaca, M., Vaquero-Lafuente, E. (2025). Fine-tuning transformer models for M&A target prediction in the U.S. ENERGY sector. Cogent Business & Management, 12 (1). https://doi.org/10.1080/23311975.2025.2487219
- Byrd, C., Kingsbury, C., Niell, B., Funaro, K., Bhatt, A., Weinfurtner, R. J., Ataya, D. (2025). Appropriateness of acute breast symptom recommendations provided by ChatGPT. Clinical Imaging, 125, 110549. https://doi.org/10.1016/j.clinimag.2025.110549
- Brown, E. D. L., Ward, M., Maity, A., Mittler, M. A., Larry Lo, S.-F., D’Amico, R. S. (2024). Enhancing Diagnostic Support for Chiari Malformation and Syringomyelia: A Comparative Study of Contextualized ChatGPT Models. World Neurosurgery, 189, e86–e107. https://doi.org/10.1016/j.wneu.2024.05.172
- Ni, W., Shen, Q., Liu, T., Zeng, Q., Xu, L. (2023). Generating textual emergency plans for unconventional emergencies – A natural language processing approach. Safety Science, 160, 106047. https://doi.org/10.1016/j.ssci.2022.106047
- Ganzinger, M., Kunz, N., Fuchs, P., Lyu, C. K., Loos, M., Dugas, M., Pausch, T. M. (2025). Automated generation of discharge summaries: leveraging large language models with clinical data. Scientific Reports, 15 (1). https://doi.org/10.1038/s41598-025-01618-7
- Xu, Y., Wang, T., Yuan, Y., Huang, Z., Chen, X., Zhang, B. et al. (2025). LLM-Enhanced Framework for Building Domain-Specific Lexicon for Urban Power Grid Design. Applied Sciences, 15 (8), 4134. https://doi.org/10.3390/app15084134
- Keng-Jung, P., Chin-Hung, K., Cheng-Yen, W., Peng, J.-W., Huang, C.-Y., Chen, J.-C. (2021). Analyze the subordination structure between domain-specific vocabulary and meaning with the Word2Vec training process. 2021 IEEE International Conference on Consumer Electronics-Taiwan (ICCE-TW), 1–2. https://doi.org/10.1109/icce-tw52618.2021.9602966
- Xu, K., Feng, Y., Li, Q., Dong, Z., Wei, J. (2025). Survey on terminology extraction from texts. Journal of Big Data, 12 (1). https://doi.org/10.1186/s40537-025-01077-x
- Lu, R.-S., Lin, C.-C., Tsao, H.-Y. (2024). Empowering Large Language Models to Leverage Domain-Specific Knowledge in E-Learning. Applied Sciences, 14 (12), 5264. https://doi.org/10.3390/app14125264
- Kryazhych, O., Ivanov, I., Iushchenko, K., Kupri, O., Vasenko, O., Riznyk, V., Ryzhkov, O. (2025). Devising an approach to preventing information chaos in chat bots using generative artificial intelligence. Eastern-European Journal of Enterprise Technologies, 2 (2 (134)), 84–95. https://doi.org/10.15587/1729-4061.2025.324957
##submission.downloads##
Опубліковано
Як цитувати
Номер
Розділ
Ліцензія
Авторське право (c) 2026 Olha Kryazhych, Viacheslav Riznyk, Vasyl Vasenko, Vasyl Yakuba, Kateryna Iushchenko, Oleksii Kuprin, Oleksandr Tsyrul

Ця робота ліцензується відповідно до Creative Commons Attribution 4.0 International License.
Закріплення та умови передачі авторських прав (ідентифікація авторства) здійснюється у Ліцензійному договорі. Зокрема, автори залишають за собою право на авторство свого рукопису та передають журналу право першої публікації цієї роботи на умовах ліцензії Creative Commons CC BY. При цьому вони мають право укладати самостійно додаткові угоди, що стосуються неексклюзивного поширення роботи у тому вигляді, в якому вона була опублікована цим журналом, але за умови збереження посилання на першу публікацію статті в цьому журналі.
Ліцензійний договір – це документ, в якому автор гарантує, що володіє усіма авторськими правами на твір (рукопис, статтю, тощо).
Автори, підписуючи Ліцензійний договір з ПП «ТЕХНОЛОГІЧНИЙ ЦЕНТР», мають усі права на подальше використання свого твору за умови посилання на наше видання, в якому твір опублікований. Відповідно до умов Ліцензійного договору, Видавець ПП «ТЕХНОЛОГІЧНИЙ ЦЕНТР» не забирає ваші авторські права та отримує від авторів дозвіл на використання та розповсюдження публікації через світові наукові ресурси (власні електронні ресурси, наукометричні бази даних, репозитарії, бібліотеки тощо).
За відсутності підписаного Ліцензійного договору або за відсутністю вказаних в цьому договорі ідентифікаторів, що дають змогу ідентифікувати особу автора, редакція не має права працювати з рукописом.
Важливо пам’ятати, що існує і інший тип угоди між авторами та видавцями – коли авторські права передаються від авторів до видавця. В такому разі автори втрачають права власності на свій твір та не можуть його використовувати в будь-який спосіб.






