Розширення запитів на основі аналізу контекстно-залежного настрою в базах даних з фільтрацією за доменом
DOI:
https://doi.org/10.15587/1729-4061.2025.322120Ключові слова:
розширення запитів, обробка природної мови, пошук інформації, семантичний аналіз, бази данихАнотація
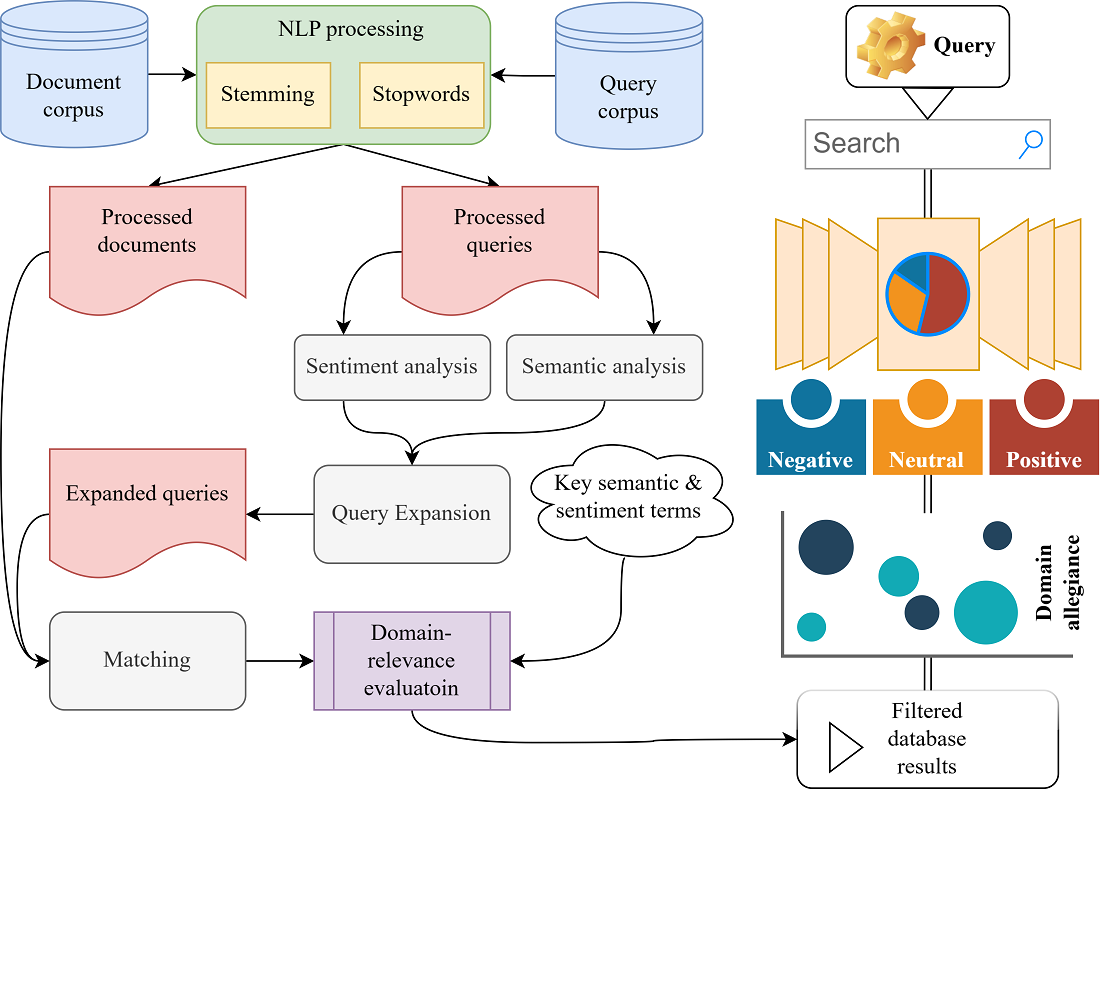
Об’єктом дослідження є процеси інформаційного пошуку у предметно-орієнтованих базах даних, які потребують адаптивного підходу для розширення запитів. Застосовуючи методи обробки природної мови (Natural Language Processing), зокрема контекстуальні вбудовування та архітектури трансформерів, дослідження акцентує увагу на адаптивному визначенні наміру користувача в межах поданого запиту. Це передбачає аналіз і застосування алгоритмів обробки тексту з доменною фільтрацією для підвищення точності та релевантності результатів пошуку. Удосконалений метод демонструє підвищення точності контекстно-чутливих моделей на 6% у порівнянні з базовими підходами. Агрегований показник F1-міри, який об’єднує точність, повноту та влучність, відображає релевантність побудованих моделей, показуючи приріст на 6-8%. Різниця між найменш і найбільш ефективними методами становить 16% у точності та 17% у релевантності. Вдосконалений метод долає обмеження статичних традиційних синонімічних і статистичних методів, динамічно інтерпретуючи взаємозв’язок між тональністю, контекстом і доменною специфікою контенту. Покращене семантичне розуміння дозволяє точніше узгоджувати розширені запити з цілями користувача. Це може бути ефективно застосованим на практиці в умовах, коли системи інформаційного пошуку працюють у межах доменно-специфічних баз даних. Також може стосуватися сценаріїв, у яких запити користувачів містять складні, емоційно забарвлені мовні конструкції, що потребують глибшого розуміння взаємозв’язків й тональності слів. Однак реалізація методу потребує навчання на високоякісних доменно-специфічних наборах даних із контекстуальними мітками, що могли б забезпечили ефективну та точну адаптацію
Посилання
- Cai, F., de Rijke, M. (2016). A Survey of Query Auto Completion in Information Retrieval. Foundations and Trends® in Information Retrieval, 10 (4), 273–363. https://doi.org/10.1561/1500000055
- Sparck Jones, K. (1972). A statistical interpretation of term specificity and its application in retrieval. Journal of Documentation, 28 (1), 11–21. https://doi.org/10.1108/eb026526
- Manning, C. D., Raghavan, P., Schütze, H. (2008). Introduction to Information Retrieval. Cambridge: Cambridge University Press. https://doi.org/10.1017/cbo9780511809071
- Hu, Z., Dychka, I., Potapova, K., Meliukh, V. (2024). Augmenting Sentiment Analysis Prediction in Binary Text Classification through Advanced Natural Language Processing Models and Classifiers. International Journal of Information Technology and Computer Science, 16 (2), 16–31. https://doi.org/10.5815/ijitcs.2024.02.02
- Mikolov, T., Chen, K., Corrado, G. Dean, J. (2013). Efficient estimation of word representations in vector space. arXiv. https://doi.org/10.48550/arXiv.1301.3781
- Yuan, J., Zhao, Y., Qin, B. (2022). Learning to share by masking the non-shared for multi-domain sentiment classification. International Journal of Machine Learning and Cybernetics, 13 (9), 2711–2724. https://doi.org/10.1007/s13042-022-01556-0
- Naseri, S., Dalton, J., Yates, A., Allan, J. (2022). CEQE to SQET: A study of contextualized embeddings for query expansion. Information Retrieval Journal, 25 (2), 184–208. https://doi.org/10.1007/s10791-022-09405-y
- Singh, J. (2017). Ranks Aggregation and Semantic Genetic Approach based Hybrid Model for Query Expansion. International Journal of Computational Intelligence Systems, 10 (1), 34. https://doi.org/10.2991/ijcis.2017.10.1.4
- Zheng, Z., Hui, K., He, B., Han, X., Sun, L., Yates, A. (2020). BERT-QE: Contextualized Query Expansion for Document Re-ranking. Findings of the Association for Computational Linguistics: EMNLP 2020. https://doi.org/10.18653/v1/2020.findings-emnlp.424
- Xu, B., Lin, H., Lin, Y., Yang, L., Xu, K. (2018). Improving Pseudo-Relevance Feedback With Neural Network-Based Word Representations. IEEE Access, 6, 62152–62165. https://doi.org/10.1109/access.2018.2876425
- Fang, F., Zhang, B.-W., Yin, X.-C. (2018). Semantic Sequential Query Expansion for Biomedical Article Search. IEEE Access, 6, 45448–45457. https://doi.org/10.1109/access.2018.2861869
- Wang, Y., Wang, N., Zhou, L. (2017). Keyword Query Expansion Paradigm Based on Recommendation and Interpretation in Relational Databases. Scientific Programming, 2017, 1–12. https://doi.org/10.1155/2017/7613026
- Parlar, T., Özel, S. A., Song, F. (2018). QER: a new feature selection method for sentiment analysis. Human-Centric Computing and Information Sciences, 8 (1). https://doi.org/10.1186/s13673-018-0135-8
##submission.downloads##
Опубліковано
Як цитувати
Номер
Розділ
Ліцензія
Авторське право (c) 2025 Vasyl Meliukh, Ekaterina Potapova, Mykola Nalyvaichuk, Andrii Dychka

Ця робота ліцензується відповідно до Creative Commons Attribution 4.0 International License.
Закріплення та умови передачі авторських прав (ідентифікація авторства) здійснюється у Ліцензійному договорі. Зокрема, автори залишають за собою право на авторство свого рукопису та передають журналу право першої публікації цієї роботи на умовах ліцензії Creative Commons CC BY. При цьому вони мають право укладати самостійно додаткові угоди, що стосуються неексклюзивного поширення роботи у тому вигляді, в якому вона була опублікована цим журналом, але за умови збереження посилання на першу публікацію статті в цьому журналі.
Ліцензійний договір – це документ, в якому автор гарантує, що володіє усіма авторськими правами на твір (рукопис, статтю, тощо).
Автори, підписуючи Ліцензійний договір з ПП «ТЕХНОЛОГІЧНИЙ ЦЕНТР», мають усі права на подальше використання свого твору за умови посилання на наше видання, в якому твір опублікований. Відповідно до умов Ліцензійного договору, Видавець ПП «ТЕХНОЛОГІЧНИЙ ЦЕНТР» не забирає ваші авторські права та отримує від авторів дозвіл на використання та розповсюдження публікації через світові наукові ресурси (власні електронні ресурси, наукометричні бази даних, репозитарії, бібліотеки тощо).
За відсутності підписаного Ліцензійного договору або за відсутністю вказаних в цьому договорі ідентифікаторів, що дають змогу ідентифікувати особу автора, редакція не має права працювати з рукописом.
Важливо пам’ятати, що існує і інший тип угоди між авторами та видавцями – коли авторські права передаються від авторів до видавця. В такому разі автори втрачають права власності на свій твір та не можуть його використовувати в будь-який спосіб.






