Improving the quality of object classification in images by ensemble classifiers with stacking
DOI:
https://doi.org/10.15587/1729-4061.2023.279372Keywords:
multilayer perceptron, neural network, ensemble classifier, weighting coefficients, classification of objects in imagesAbstract
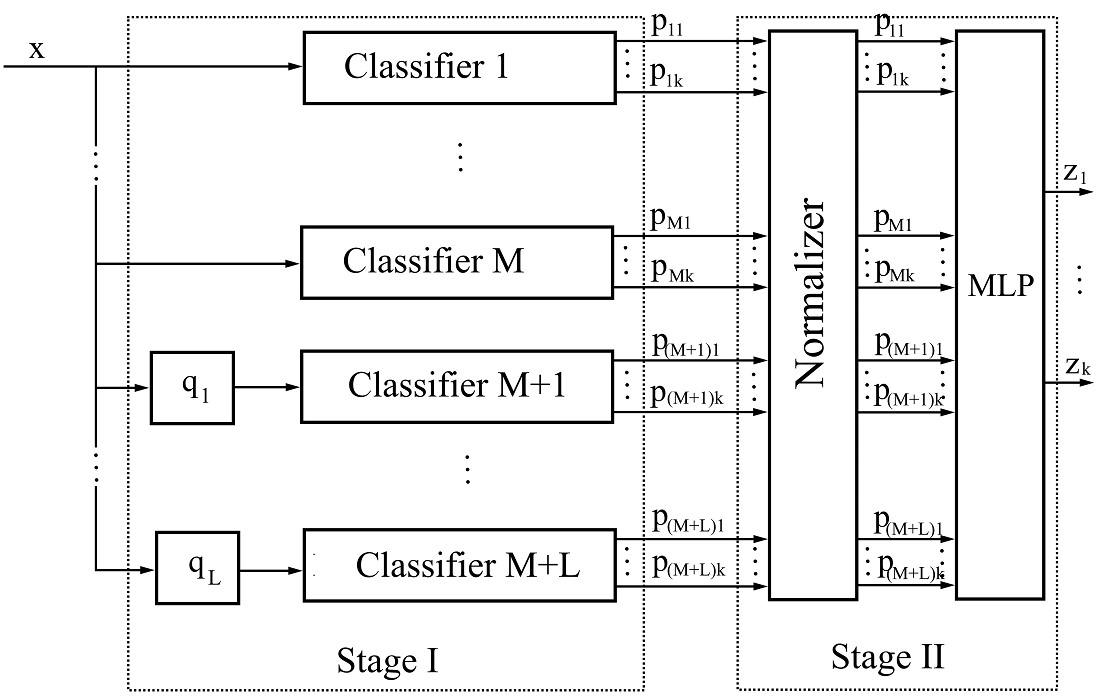
The object of research is the process of classifying objects in images. The quality of classification refers to the ratio of correctly recognized objects to the number of images. One of the options for improving the quality of classification is to increase the depth of neural networks used. The main difficulties along the way are the difficulty of training such neural networks and a large amount of computing that makes it difficult to use them on conventional computers in real time. An alternative way to improve the quality of classification is to increase the width of the neural networks used, by constructing ensemble classifiers with staking. However, they require the use of classifiers at the first stage with different structured processing of input images, characterized by high quality classification and relatively low volume of calculations. The number of known such architectures is limited. Therefore, the problem arises of increasing the number of classifiers at the first stage of the ensemble classifier by modifying known architectures. It is proposed to use blocks of rotation of images at different angles relative to the center of the image. It is shown that as a result of structured image processing by the starting classifier, processing of rotated image leads to redistribution of errors on image set. This effect makes it possible to increase the number of classifiers in the first stage of the ensemble classifier. Numerical experiments have shown that adding two analogs of the MLP-Mixer algorithm to known configurations of ensemble classifiers reduced the error from 1 to 11 % when working with the CIFAR-10 dataset. Similarly, for CCT, the error reduction was between 2.1 and 10 %. In addition, it has been shown that increasing the MLP-Mixer configuration in width gives better results than increasing in depth. A prerequisite for the success of using the proposed approach in practice is the structured image processing by the starting classifier
References
- Mary Shanthi Rani, M., Chitra, P., Lakshmanan, S., Kalpana Devi, M., Sangeetha, R., Nithya, S. (2022). DeepCompNet: A Novel Neural Net Model Compression Architecture. Computational Intelligence and Neuroscience, 2022, 1–13. doi: https://doi.org/10.1155/2022/2213273
- Han, S., Mao, H., Dally, W. J. (2015). Deep compression: compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv. doi: https://doi.org/10.48550/arXiv.1510.00149
- Galchonkov, O., Nevrev, A., Glava, M., Babych, M. (2020). Exploring the efficiency of the combined application of connection pruning and source data preprocessing when training a multilayer perceptron. Eastern-European Journal of Enterprise Technologies, 2 (9 (104)), 6–13. doi: https://doi.org/10.15587/1729-4061.2020.200819
- Iandola, F. N., Han, S., Moskewicz, M. W., Ashraf, K., Dally, W. J., Keutzer, K. (2016). SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size. arXiv. doi: https://doi.org/10.48550/arXiv.1602.07360
- Wu, K., Guo, Y., Zhang, C. (2020). Compressing Deep Neural Networks With Sparse Matrix Factorization. IEEE Transactions on Neural Networks and Learning Systems, 31 (10), 3828–3838. doi: https://doi.org/10.1109/tnnls.2019.2946636
- Cheng, X., Rao, Z., Chen, Y., Zhang, Q. (2020). Explaining Knowledge Distillation by Quantifying the Knowledge. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). doi: https://doi.org/10.1109/cvpr42600.2020.01294
- Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T. et al. (2021). An image is worth 16x16 words: transformers for image recognition at scale. arXiv. doi: https://doi.org/10.48550/arXiv.2010.11929
- Yuan, L., Chen, Y., Wang, T., Yu, W., Shi, Y., Jiang, Z. et al. (2021). Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet. 2021 IEEE/CVF International Conference on Computer Vision (ICCV). doi: https://doi.org/10.1109/iccv48922.2021.00060
- d’Ascoli, S., Touvron, H., Leavitt, M. L., Morcos, A. S., Biroli, G., Sagun, L. (2022). ConViT: improving vision transformers with soft convolutional inductive biases. Journal of Statistical Mechanics: Theory and Experiment, 2022 (11), 114005. doi: https://doi.org/10.1088/1742-5468/ac9830
- Yuan, K., Guo, S., Liu, Z., Zhou, A., Yu, F., Wu, W. (2021). Incorporating Convolution Designs into Visual Transformers. 2021 IEEE/CVF International Conference on Computer Vision (ICCV). doi: https://doi.org/10.1109/iccv48922.2021.00062
- Wu, H., Xiao, B., Codella, N., Liu, M., Dai, X., Yuan, L., Zhang, L. (2021). CvT: Introducing Convolutions to Vision Transformers. 2021 IEEE/CVF International Conference on Computer Vision (ICCV). doi: https://doi.org/10.1109/iccv48922.2021.00009
- Galchonkov, O., Babych, M., Zasidko, A., Poberezhnyi, S. (2022). Using a neural network in the second stage of the ensemble classifier to improve the quality of classification of objects in images. Eastern-European Journal of Enterprise Technologies, 3 (9 (117)), 15–21. doi: https://doi.org/10.15587/1729-4061.2022.258187
- Rokach, L. (2019). Ensemble Learning. Pattern Classification Using Ensemble Methods. World Scientific Publishing Co. doi: https://doi.org/10.1142/11325
- Hassani, A., Walton, S., Shah, N., Abuduweili, A., Li, J., Shi, H. (2021). Escaping the Big Data Paradigm with Compact Transformers. arXiv. doi: https://doi.org/10.48550/arXiv.2104.05704
- Guo, M.-H., Liu, Z.-N., Mu, T.-J., Hu, S.-M. (2022). Beyond Self-Attention: External Attention Using Two Linear Layers for Visual Tasks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1–13. doi: https://doi.org/10.1109/tpami.2022.3211006
- Lee-Thorp, J., Ainslie, J., Eckstein, I., Ontanon, S. (2022). FNet: Mixing Tokens with Fourier Transforms. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. doi: https://doi.org/10.18653/v1/2022.naacl-main.319
- Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z. et al. (2021). Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. 2021 IEEE/CVF International Conference on Computer Vision (ICCV). doi: https://doi.org/10.1109/iccv48922.2021.00986
- Tolstikhin, I., Houlsby, N., Kolesnikov, A., Beyer, L., Zhai, X., Unterthiner, T. et al. (2021). MLP-Mixer: An all-MLP Architecture for Vision. arXiv. doi: https://doi.org/10.48550/arXiv.2105.01601
- Liu, H., Dai, Z., So, D. R., Le, Q. V. (2021). Pay Attention to MLPs. arXiv. doi: https://doi.org/10.48550/arXiv.2105.08050
- Brownlee, J. (2019). Deep Learning for Computer Vision. Image Classification, Object Detection, and Face Recognition in Python. Available at: https://machinelearningmastery.com/deep-learning-for-computer-vision/
- Brownlee, J. (2019). Better Deep Learning. Train Faster, Reduce Overfitting, and Make Better Predictions. Available at: https://machinelearningmastery.com/better-deep-learning/
- Krizhevsky A. The CIFAR-10 dataset. Available at: https://www.cs.toronto.edu/~kriz/cifar.html
- Code examples / Computer vision. Keras. Available at: https://keras.io/examples/vision/
- Brownlee, J. (2021). Weight Initialization for Deep Learning Neural Networks. Available at: https://machinelearningmastery.com/weight-initialization-for-deep-learning-neural-networks/
- Colab. Available at: https://colab.research.google.com/notebooks/welcome.ipynb
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2023 Oleg Galchonkov, Oleksii Baranov, Mykola Babych, Varvara Kuvaieva, Yuliia Babych

This work is licensed under a Creative Commons Attribution 4.0 International License.
The consolidation and conditions for the transfer of copyright (identification of authorship) is carried out in the License Agreement. In particular, the authors reserve the right to the authorship of their manuscript and transfer the first publication of this work to the journal under the terms of the Creative Commons CC BY license. At the same time, they have the right to conclude on their own additional agreements concerning the non-exclusive distribution of the work in the form in which it was published by this journal, but provided that the link to the first publication of the article in this journal is preserved.
A license agreement is a document in which the author warrants that he/she owns all copyright for the work (manuscript, article, etc.).
The authors, signing the License Agreement with TECHNOLOGY CENTER PC, have all rights to the further use of their work, provided that they link to our edition in which the work was published.
According to the terms of the License Agreement, the Publisher TECHNOLOGY CENTER PC does not take away your copyrights and receives permission from the authors to use and dissemination of the publication through the world's scientific resources (own electronic resources, scientometric databases, repositories, libraries, etc.).
In the absence of a signed License Agreement or in the absence of this agreement of identifiers allowing to identify the identity of the author, the editors have no right to work with the manuscript.
It is important to remember that there is another type of agreement between authors and publishers – when copyright is transferred from the authors to the publisher. In this case, the authors lose ownership of their work and may not use it in any way.





