Development and increase of noise immunity of a model of biometric identification of a speaker based on metal-frequency cepstral coefficients and a convolutional neural network
DOI:
https://doi.org/10.15587/1729-4061.2025.347451Keywords:
speaker identification, voice biometrics, Kazakh speech, mel-frequency cepstral coefficients, noiseAbstract
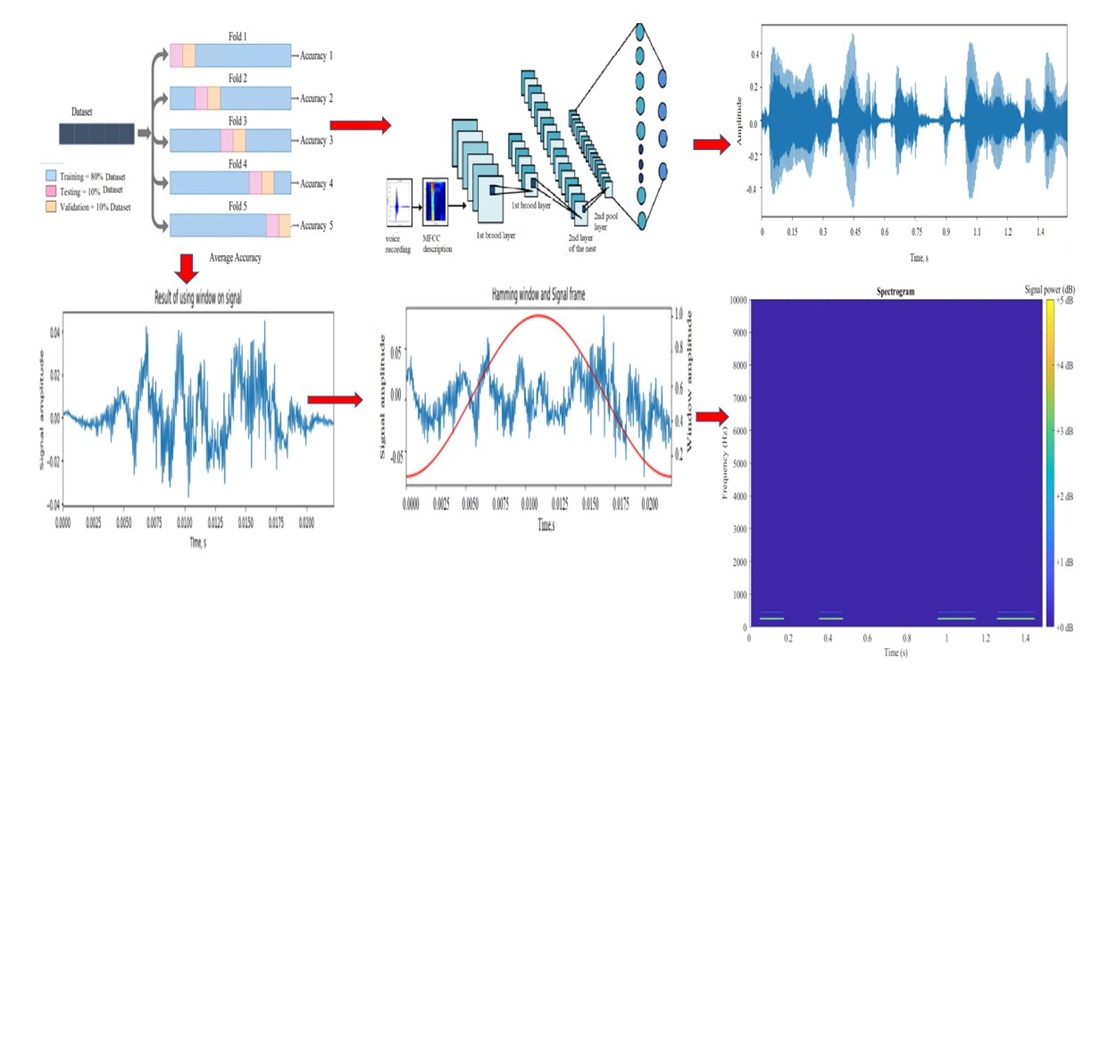
This study is focused on improving the noise robustness of a biometric speaker identification system based on mel-frequency cepstral coefficients (MFCC) and a convolutional neural network (CNN). The object of analysis is the acoustic structure of the Kazakh language under clean and noisy conditions. The experimental database consisted of 16 speakers, each represented by 12 audio recordings with a duration of approximately 1 s. The speech signals were corrupted by additive pink noise with different signal-to-noise ratio (SNR) levels.
Under clean signal conditions, the CNN-based classifier achieved a high recognition accuracy of approximately 96%, as confirmed by the confusion matrix with strong diagonal dominance. When exposed to noise, the classification accuracy decreased to about 69%, demonstrating the significant impact of acoustic interference on speaker identification performance. To improve noise immunity, noise augmentation was applied during training. After retraining on the augmented dataset, the classification accuracy under noisy conditions increased to approximately 89–90%.
The heatmaps of precision, recall, and F1-score demonstrate that after robustness enhancement, most speaker classes achieve stable metric values in the range of 0.85–1.00, while the averaged performance metrics reach accuracy ≈ 0.89–0.90, confirming consistent recognition across the entire dataset. The results show that MFCC features retain discriminative speaker-specific spectral characteristics even under noise and that CNN-based classification significantly outperforms traditional approaches in terms of robustness.
The proposed MFCC–CNN approach provides high identification accuracy in clean environments and maintains competitive performance under noise after data augmentation. The obtained results confirm the practical applicability of the developed system for reliable speaker verification in acoustically unstable environments, including remote biometric authentication, access control, and intelligent communication systems
References
- Ahmad, Kh. M., Zhirkov, V. F. (2007). Introduction to digital processing of speech signals. Vladimir State University Press.
- Beigi, H. (2011). Fundamentals of Speaker Recognition. Springer, 942. https://doi.org/10.1007/978-0-387-77592-0
- Chauhan, N., Isshiki, T., Li, D. (2024). Enhancing Speaker Recognition Models with Noise-Resilient Feature Optimization Strategies. Acoustics, 6 (2), 439–469. https://doi.org/10.3390/acoustics6020024
- Ming, J., Hazen, T. J., Glass, J. R., Reynolds, D. A. (2007). Robust Speaker Recognition in Noisy Conditions. IEEE Transactions on Audio, Speech and Language Processing, 15 (5), 1711–1723. https://doi.org/10.1109/tasl.2007.899278
- Ji, Z., Cheng, G., Lu, T., Shao, Z. (2024). Speaker recognition system based on MFCC feature extraction CNN architecture. Academic Journal of Computing & Information Science, 7 (7). https://doi.org/10.25236/ajcis.2024.070707
- From i-vectors to x-vectors – a generational change in speaker recognition illustrated on the NFI-FRIDA database (2019). Oxford Wave Research. Available at: https://oxfordwaveresearch.com/wp-content/uploads/2020/02/IAFPA19_xvectors_Kelly_et_al_presentation.pdf
- Peters, C. A. (2001). Statistics for Analysis of Experimental Data. Environmental Engineering Processes Laboratory Manual. Available at: https://www.researchgate.net/publication/280580217_Statistics_for_Analysis_of_Experimental_Data
- Singh, M. K. (2024). Speaker Identification Using MFCC Feature Extraction ANN Classification Technique. Wireless Personal Communications, 136 (1), 453–467. https://doi.org/10.1007/s11277-024-11282-1
- Snyder, D., Garcia-Romero, D., Sell, G., Povey, D., Khudanpur, S. (2018). X-Vectors: Robust DNN Embeddings for Speaker Recognition. 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 5329–5333. https://doi.org/10.1109/icassp.2018.8461375
- Sumithra, M. G., Thanuskodi, K., Archana, A. H. J. J. (2011). A new speaker recognition system with combined feature extraction techniques. Journal of Computer Science, 7(4), 459–465. https://doi.org/10.3844/jcssp.2011.459.465
- Uncini, A. (2022). Digital Audio Processing Fundamentals. Springer, 716. https://doi.org/10.1007/978-3-031-14228-4
- Zhumay, I., Tumanbayeva, K., Chezhimbayeva, K., Kalibek, K. (2025). Forecasting anomalies in network traffic. Eastern-European Journal of Enterprise Technologies, 2 (2 (134)), 96–111. https://doi.org/10.15587/1729-4061.2025.326779
- Chezhimbayeva, K., Konyrova, M., Kumyzbayeva, S., Kadylbekkyzy, E. (2021). Quality assessment of the contact center while implementation the IP IVR system by using teletraffic theory. Eastern-European Journal of Enterprise Technologies, 6 (3 (114)), 64–71. https://doi.org/10.15587/1729-4061.2021.244976
- Nurzhaubayeva, G., Haris, N., Chezhimbayeva, K. (2024). Design of the Wearable Microstrip Yagi-Uda Antenna for IoT Applications. International Journal on Communications Antenna and Propagation (IRECAP), 14 (1), 24. https://doi.org/10.15866/irecap.v14i1.24315
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2025 Muhabbat Khizirova, Katipa Chezhimbayeva, Аbdurazak Kassimov, Muratbek Yermekbaev, Assiya Iskakova, Zhaina Abilkaiyr

This work is licensed under a Creative Commons Attribution 4.0 International License.
The consolidation and conditions for the transfer of copyright (identification of authorship) is carried out in the License Agreement. In particular, the authors reserve the right to the authorship of their manuscript and transfer the first publication of this work to the journal under the terms of the Creative Commons CC BY license. At the same time, they have the right to conclude on their own additional agreements concerning the non-exclusive distribution of the work in the form in which it was published by this journal, but provided that the link to the first publication of the article in this journal is preserved.
A license agreement is a document in which the author warrants that he/she owns all copyright for the work (manuscript, article, etc.).
The authors, signing the License Agreement with TECHNOLOGY CENTER PC, have all rights to the further use of their work, provided that they link to our edition in which the work was published.
According to the terms of the License Agreement, the Publisher TECHNOLOGY CENTER PC does not take away your copyrights and receives permission from the authors to use and dissemination of the publication through the world's scientific resources (own electronic resources, scientometric databases, repositories, libraries, etc.).
In the absence of a signed License Agreement or in the absence of this agreement of identifiers allowing to identify the identity of the author, the editors have no right to work with the manuscript.
It is important to remember that there is another type of agreement between authors and publishers – when copyright is transferred from the authors to the publisher. In this case, the authors lose ownership of their work and may not use it in any way.






