Devising an approach to analyze and automatically reconfigure the structure of websites
DOI:
https://doi.org/10.15587/1729-4061.2026.357377Keywords:
DOM model, web graph clustering, page similarity, structure optimization, relinking, cosine distanceAbstract
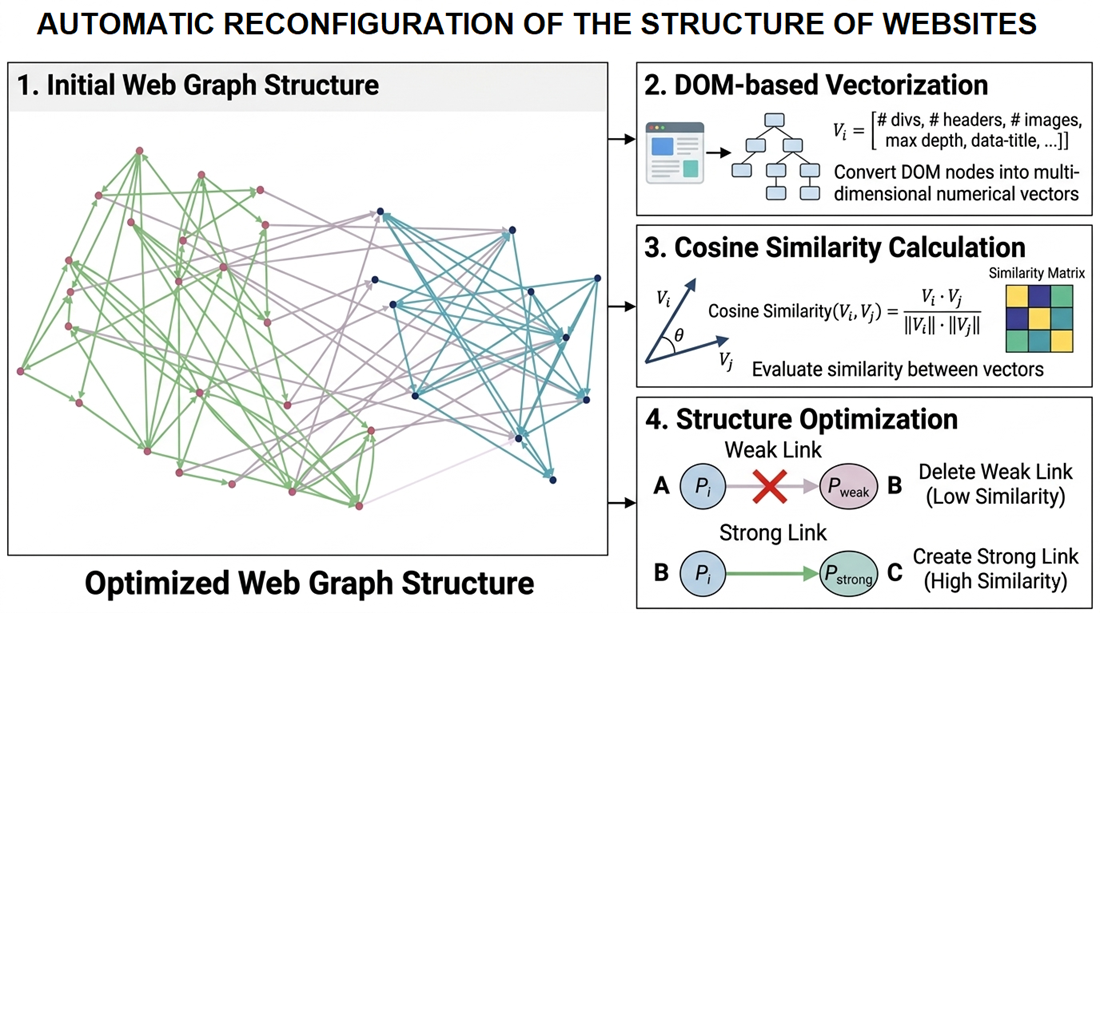
This study explores websites such as online stores, which are considered to be a set of interconnected web pages. The task addressed relates to the high computational complexity of manual analysis of the topology of modern websites, as well as the lack of formalized mechanisms that could make it possible to integrate the semantic features of web pages into the process of automated hyperlink reconstruction.
Within the framework of this study, a website is crawled in order to obtain complete HTML documents, from which the structural features of pages are extracted (the number of headings, depth of embedding, presence of <article>, number of incoming links, etc.). The resulting vectors make it possible to construct cosine similarity matrices to assess the mutual proximity of pages. An approach has been proposed to rebuilding the link structure of the website taking into account this similarity; a comparison of the initial and transformed website was carried out using the metric characteristics of modularity, clustering, diameter, and similarity distribution.
The results demonstrate that taking into account the DOM structure allows for the formation of a logical, reasonable distribution of pages between clusters. And the subsequent automatic procedure for setting hyperlinks makes it possible to improve structural integrity by establishing effective relationships between thematically close pages.
The practical significance of this work involves the possibility of using the proposed approach for automated optimization of internal links of static websites. As a result, the architecture of the web resource is improved, website navigation becomes transparent, and website indexing by search engines is increased
References
- Huk, N. A., Dykhanov, S. V., Matiushchenko, O. D. (2020). Algorithm for building a website model. Bulletin of V.N. Karazin Kharkiv National University, Series «Mathematical Modeling. Information Technology. Automated Control Systems», 47, 25–34. https://doi.org/10.26565/2304-6201-2020-47-03
- Dolotov, I. O., Guk, N. A. (2023). Clustering of a weighted webgraf with the usage of modularity. 2023: Problems of applied mathematics and mathematical modeling, 23, 25–32. https://doi.org/10.15421/322305
- Ma, W., Chen, X., Shang, W. (2012). Advanced Deep Web Crawler Based on Dom. 2012 Fifth International Joint Conference on Computational Sciences and Optimization, 605–609. https://doi.org/10.1109/cso.2012.138
- Dykhanov, S., Guk, N. (2022). Analysis of the structure of web resources using the object model. Eastern-European Journal of Enterprise Technologies, 5 (2 (119)), 6–13. https://doi.org/10.15587/1729-4061.2022.265961
- Kao, H.-Y., Ho, J.-M., Chen, M.-S. (2005) WISDOM: Web Intrapage Informative Structure Mining based on Document Object Model. IEEE Transactions on Knowledge and Data Engineering, 17 (5), 614–627. https://doi.org/10.1109/tkde.2005.84
- Ahmad Sabri, I. A., Man, M. (2018). Improving Performance of DOM in Semi-structured Data Extraction using WEIDJ Model. Indonesian Journal of Electrical Engineering and Computer Science, 9 (3), 752. https://doi.org/10.11591/ijeecs.v9.i3.pp752-763
- Huynh, H., Le, T., Nguyen, V., Nguyen, T. (2024). A DOM-structural Cohesion Analysis Approach for Segmentation of Modern Web Pages. https://doi.org/10.21203/rs.3.rs-4392630/v1
- Shin, K., Niiyama, T. (2018). The Mapping Distance – a Generalization of the Edit Distance – and its Application to Trees. Proceedings of the 10th International Conference on Agents and Artificial Intelligence, 266–275. https://doi.org/10.5220/0006721902660275
- Jalal, A. A., Jasim, A. A., Mahawish, A. A. (2022). A web content mining application for detecting relevant pages using Jaccard similarity. International Journal of Electrical and Computer Engineering (IJECE), 12 (6), 6461. https://doi.org/10.11591/ijece.v12i6.pp6461-6471
- Kumar, B. T. H., Vibha, L., Venugopal, K. R. (2016). Web page access prediction using hierarchical clustering based on modified levenshtein distance and higher order Markov model. 2016 IEEE Region 10 Symposium (TENSYMP), 1–6. https://doi.org/10.1109/tenconspring.2016.7519368
- Roul, R. K., Devanand, O. R., Sahay, S. K. (2014). Web Document Clustering and Ranking using Tf-Idf based Apriori Approach. IJCA Proceedings on ICACEA, 2, 34. https://doi.org/10.48550/arXiv.1406.5617
- Meleshko, Ye. (2019). Graph clustering methods in social networks for building recommendation systems. Control, Navigation and Communication Systems, 2 (54), 129–134. https://doi.org/10.26906/SUNZ.2019.2.129
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2026 Ivan Dolotov, Natalia Guk

This work is licensed under a Creative Commons Attribution 4.0 International License.
The consolidation and conditions for the transfer of copyright (identification of authorship) is carried out in the License Agreement. In particular, the authors reserve the right to the authorship of their manuscript and transfer the first publication of this work to the journal under the terms of the Creative Commons CC BY license. At the same time, they have the right to conclude on their own additional agreements concerning the non-exclusive distribution of the work in the form in which it was published by this journal, but provided that the link to the first publication of the article in this journal is preserved.
A license agreement is a document in which the author warrants that he/she owns all copyright for the work (manuscript, article, etc.).
The authors, signing the License Agreement with TECHNOLOGY CENTER PC, have all rights to the further use of their work, provided that they link to our edition in which the work was published.
According to the terms of the License Agreement, the Publisher TECHNOLOGY CENTER PC does not take away your copyrights and receives permission from the authors to use and dissemination of the publication through the world's scientific resources (own electronic resources, scientometric databases, repositories, libraries, etc.).
In the absence of a signed License Agreement or in the absence of this agreement of identifiers allowing to identify the identity of the author, the editors have no right to work with the manuscript.
It is important to remember that there is another type of agreement between authors and publishers – when copyright is transferred from the authors to the publisher. In this case, the authors lose ownership of their work and may not use it in any way.






