The approach development of data extraction from lambda terms
DOI:
https://doi.org/10.15587/1729-4061.2024.298991Keywords:
functional programming, Lambda Calculus, Large Language Model, unsupervised learning methodsAbstract
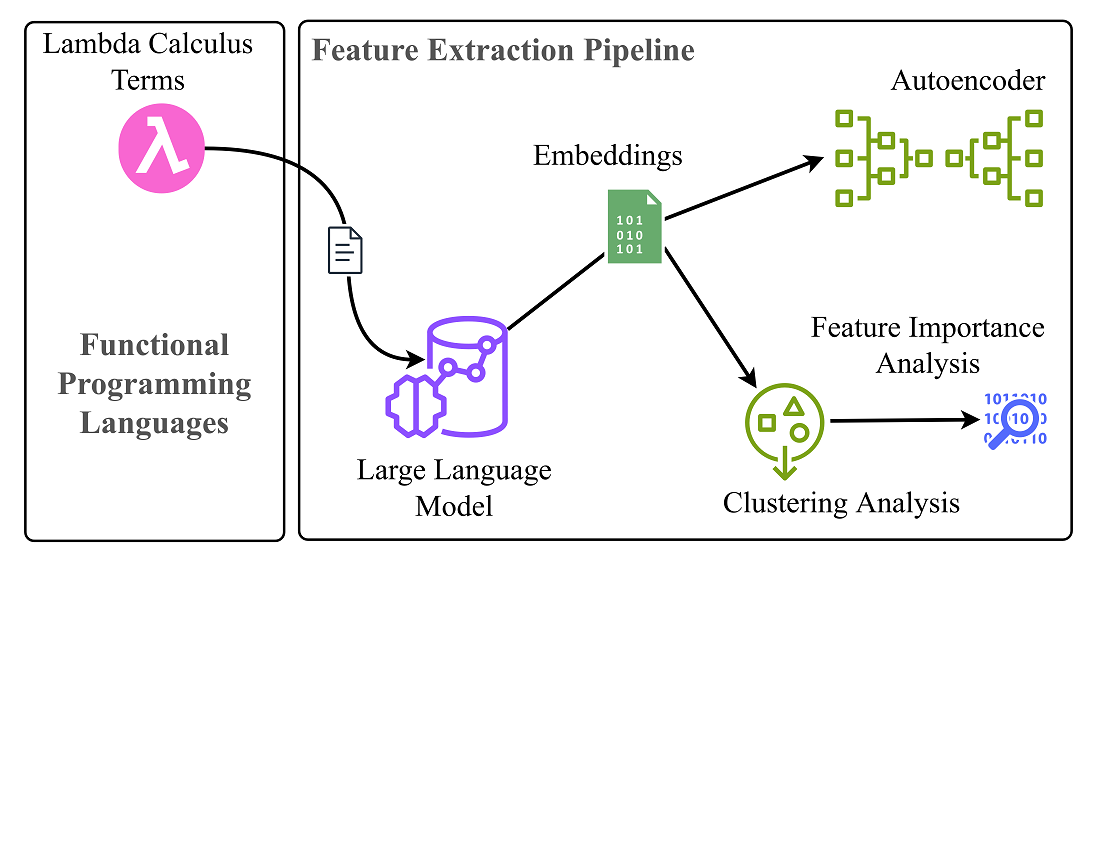
The study's object is the process of extracting the characteristics of lambda terms, which indicate the optimality of the reduction strategy and increase the productivity of compilers and interpreters. The solution to the problem of extracting specific strategy priority data from lambda terms using Machine Learning methods was considered.
Such data was extracted using the large language model Microsoft CodeBERT, which was trained to solve the problem of summarizing the software code. The resulting matrices of embeddings were used to obtain vectors of average embeddings of size 768 and a latent space of size 8 thousand. Further, vectors of average embeddings were used for cluster analysis using the DBSCAN and Hierarchical Agglomerative clustering methods. The most informative variables affecting clustering were determined. Next, the clustering results were compared with the priorities of reduction strategies, which showed the impossibility of separating terms with RI priority. A feature of the obtained results is using machine learning methods to obtain knowledge.
The clustering results showed many of the same informative variables, which is explained by the similar shape of the obtained clusters. The results of comparing the clustering values with the real priority are explained by the impossibility of clearly determining the priority and the use of the Microsoft CodeBERT model, which was not trained for the analysis of lambda terms.
The proposed approach can find application in the development of compilers and interpreters of functional programming languages, allowing to analyze the code and extract important data to optimize the execution of programs. The obtained data can be used to develop rules aimed at improving the efficiency of compilation and interpretation
References
- Pollak, D., Layka, V., Sacco, A. (2022). Functional Programming. Beginning Scala 3, 79–109. https://doi.org/10.1007/978-1-4842-7422-4_4
- Deineha, O., Donets, V., Zholtkevych, G. (2023). On Randomization of Reduction Strategies for Typeless Lambda Calculus. Communications in Computer and Information Science, 25–38. https://doi.org/10.1007/978-3-031-48325-7_3
- Deineha, O., Donets, V., Zholtkevych, G. (2023). Estimating Lambda-Term Reduction Complexity with Regression Methods. Information Technology and Implementation 2023. Available at: https://ceur-ws.org/Vol-3624/Paper_13.pdf
- Chen, J., Xu, N., Chen, P., Zhang, H. (2021). Efficient Compiler Autotuning via Bayesian Optimization. 2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE). https://doi.org/10.1109/icse43902.2021.00110
- Cummins, C., Wasti, B., Guo, J., Cui, B., Ansel, J., Gomez, S. et al. (2022). CompilerGym: Robust, Performant Compiler Optimization Environments for AI Research. 2022 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). https://doi.org/10.1109/cgo53902.2022.9741258
- Martins, L. G. A., Nobre, R., Cardoso, J. M. P., Delbem, A. C. B., Marques, E. (2016). Clustering-Based Selection for the Exploration of Compiler Optimization Sequences. ACM Transactions on Architecture and Code Optimization, 13 (1), 1–28. https://doi.org/10.1145/2883614
- Ashouri, A. H., Bignoli, A., Palermo, G., Silvano, C., Kulkarni, S., Cavazos, J. (2017). MiCOMP. ACM Transactions on Architecture and Code Optimization, 14 (3), 1–28. https://doi.org/10.1145/3124452
- de Souza Xavier, T. C., da Silva, A. F. (2018). Exploration of Compiler Optimization Sequences Using a Hybrid Approach. Computing and Informatics, 37 (1), 165–185. https://doi.org/10.4149/cai_2018_1_165
- Mammadli, R., Jannesari, A., Wolf, F. (2020). Static Neural Compiler Optimization via Deep Reinforcement Learning. 2020 IEEE/ACM 6th Workshop on the LLVM Compiler Infrastructure in HPC (LLVM-HPC) and Workshop on Hierarchical Parallelism for Exascale Computing (HiPar). https://doi.org/10.1109/llvmhpchipar51896.2020.00006
- Runciman, C., Wakeling, D. (1993). Heap Profiling of a Lazy Functional Compiler. Workshops in Computing, 203–214. https://doi.org/10.1007/978-1-4471-3215-8_18
- Chlipala, A. (2015). An optimizing compiler for a purely functional web-application language. Proceedings of the 20th ACM SIGPLAN International Conference on Functional Programming. https://doi.org/10.1145/2784731.2784741
- Deineha, O., Donets, V., Zholtkevych, G. (2023). Deep Learning Models for Estimating Number of Lambda-Term Reduction Steps. 3rd International Workshop of IT-professionals on Artificial Intelligence 2023. Available at: https://ceur-ws.org/Vol-3641/paper12.pdf
- Vaswani, A., Shazeer, N. M., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N. et al. (2017). Attention is All you Need. arXiv. https://doi.org/10.48550/arXiv.1706.03762
- Zhao, W. X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y. et al. (2023). A Survey of Large Language Models. arXiv. https://doi.org/10.48550/arXiv.2303.18223
- Ormerod, M., del Rincón, J. M., Devereux, B. (2024). How Is a “Kitchen Chair” like a “Farm Horse”? Exploring the Representation of Noun-Noun Compound Semantics in Transformer-based Language Models. Computational Linguistics, 50 (1), 49–81. https://doi.org/10.1162/coli_a_00495
- Rozière, B., Gehring, J., Gloeckle, F., Sootla, S., Gat, I., Tan, X. et al. (2023). Code Llama: Open Foundation Models for Code. arXiv. https://doi.org/10.48550/arXiv.2308.12950
- Replit. replit-code-V1-3B. Hugging Face. Available at: https://huggingface.co/replit/replit-code-v1-3b
- Elnaggar, A., Ding, W., Jones, L., Gibbs, T., Fehér, T. B., Angerer, C. et al. (2021). CodeTrans: Towards Cracking the Language of Silicon's Code Through Self-Supervised Deep Learning and High Performance Computing. arXiv. https://doi.org/10.48550/arXiv.2104.02443
- Feng, Z., Guo, D., Tang, D., Duan, N., Feng, X., Gong, M. et al. (2020). CodeBERT: A Pre-Trained Model for Programming and Natural Languages. Findings of the Association for Computational Linguistics: EMNLP 2020. https://doi.org/10.18653/v1/2020.findings-emnlp.139
- Wang, Y., Wang, W., Joty, S., Hoi, S. C. H. (2021). CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. https://doi.org/10.18653/v1/2021.emnlp-main.685
- Styawati, S., Nurkholis, A., Aldino, A. A., Samsugi, S., Suryati, E., Cahyono, R. P. (2022). Sentiment Analysis on Online Transportation Reviews Using Word2Vec Text Embedding Model Feature Extraction and Support Vector Machine (SVM) Algorithm. 2021 International Seminar on Machine Learning, Optimization, and Data Science (ISMODE). https://doi.org/10.1109/ismode53584.2022.9742906
- Dwivedi, V. P., Shrivastava, M. (2017). Beyond Word2Vec: Embedding Words and Phrases in Same Vector Space. ICON. Available at: https://aclanthology.org/W17-7526.pdf
- Hartigan, J. A., Wong, M. A. (1979). Algorithm AS 136: A K-Means Clustering Algorithm. Applied Statistics, 28 (1), 100. https://doi.org/10.2307/2346830
- Hahsler, M., Piekenbrock, M., Doran, D. (2019). dbscan: Fast Density-Based Clustering with R. Journal of Statistical Software, 91 (1). https://doi.org/10.18637/jss.v091.i01
- Zhang, Y., Li, M., Wang, S., Dai, S., Luo, L., Zhu, E. et al. (2021). Gaussian Mixture Model Clustering with Incomplete Data. ACM Transactions on Multimedia Computing, Communications, and Applications, 17 (1s), 1–14. https://doi.org/10.1145/3408318
- Monath, N., Dubey, K. A., Guruganesh, G., Zaheer, M., Ahmed, A., McCallum, A. et al. (2021). Scalable Hierarchical Agglomerative Clustering. Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. https://doi.org/10.1145/3447548.3467404
- Shahapure, K. R., Nicholas, C. (2020). Cluster Quality Analysis Using Silhouette Score. 2020 IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA). https://doi.org/10.1109/dsaa49011.2020.00096
- Ros, F., Riad, R., Guillaume, S. (2023). PDBI: A partitioning Davies-Bouldin index for clustering evaluation. Neurocomputing, 528, 178–199. https://doi.org/10.1016/j.neucom.2023.01.043
- Lima, S. P., Cruz, M. D. (2020). A genetic algorithm using Calinski-Harabasz index for automatic clustering problem. Revista Brasileira de Computação Aplicada, 12 (3), 97–106. https://doi.org/10.5335/rbca.v12i3.11117
- Li, X., Liang, W., Zhang, X., Qing, S., Chang, P.-C. (2019). A cluster validity evaluation method for dynamically determining the near-optimal number of clusters. Soft Computing, 24 (12), 9227–9241. https://doi.org/10.1007/s00500-019-04449-7
- Chung, H., Ko, H., Kang, W. S., Kim, K. W., Lee, H., Park, C. et al. (2021). Prediction and Feature Importance Analysis for Severity of COVID-19 in South Korea Using Artificial Intelligence: Model Development and Validation. Journal of Medical Internet Research, 23 (4), e27060. https://doi.org/10.2196/27060
- Pereira, J. P. B., Stroes, E. S. G., Zwinderman, A. H., Levin, E. (2022). Covered Information Disentanglement: Model Transparency via Unbiased Permutation Importance. Proceedings of the AAAI Conference on Artificial Intelligence, 36 (7), 7984–7992. https://doi.org/10.1609/aaai.v36i7.20769
- Chen, X., Ding, M., Wang, X., Xin, Y., Mo, S., Wang, Y. et al. (2023). Context Autoencoder for Self-supervised Representation Learning. International Journal of Computer Vision, 132 (1), 208–223. https://doi.org/10.1007/s11263-023-01852-4
- Yin, C., Zhang, S., Wang, J., Xiong, N. N. (2022). Anomaly Detection Based on Convolutional Recurrent Autoencoder for IoT Time Series. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 52 (1), 112–122. https://doi.org/10.1109/tsmc.2020.2968516
- Niedoba, T. (2014). Multi-parameter data visualization by means of principal component analysis (PCA) in qualitative evaluation of various coal types. Physicochemical Problems of Mineral Processing, 50 (2), 575–589. Available at: https://bibliotekanauki.pl/articles/109595
- Oliveira, F. H. M., Machado, A. R. P., Andrade, A. O. (2018). On the Use of t-Distributed Stochastic Neighbor Embedding for Data Visualization and Classification of Individuals with Parkinson’s Disease. Computational and Mathematical Methods in Medicine, 2018, 1–17. https://doi.org/10.1155/2018/8019232
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2024 Oleksandr Deineha, Volodymyr Donets, Grygoriy Zholtkevych

This work is licensed under a Creative Commons Attribution 4.0 International License.
The consolidation and conditions for the transfer of copyright (identification of authorship) is carried out in the License Agreement. In particular, the authors reserve the right to the authorship of their manuscript and transfer the first publication of this work to the journal under the terms of the Creative Commons CC BY license. At the same time, they have the right to conclude on their own additional agreements concerning the non-exclusive distribution of the work in the form in which it was published by this journal, but provided that the link to the first publication of the article in this journal is preserved.
A license agreement is a document in which the author warrants that he/she owns all copyright for the work (manuscript, article, etc.).
The authors, signing the License Agreement with TECHNOLOGY CENTER PC, have all rights to the further use of their work, provided that they link to our edition in which the work was published.
According to the terms of the License Agreement, the Publisher TECHNOLOGY CENTER PC does not take away your copyrights and receives permission from the authors to use and dissemination of the publication through the world's scientific resources (own electronic resources, scientometric databases, repositories, libraries, etc.).
In the absence of a signed License Agreement or in the absence of this agreement of identifiers allowing to identify the identity of the author, the editors have no right to work with the manuscript.
It is important to remember that there is another type of agreement between authors and publishers – when copyright is transferred from the authors to the publisher. In this case, the authors lose ownership of their work and may not use it in any way.





