Розробка класифікатора аудіокоманд на основі мікрофону з використанням згорткової нейронної мережі
DOI:
https://doi.org/10.15587/1729-4061.2023.273492Ключові слова:
аудіо, команди, спектрограма, класифікатор, глибоке навчання, ЗНМ, мережа, реальний часАнотація
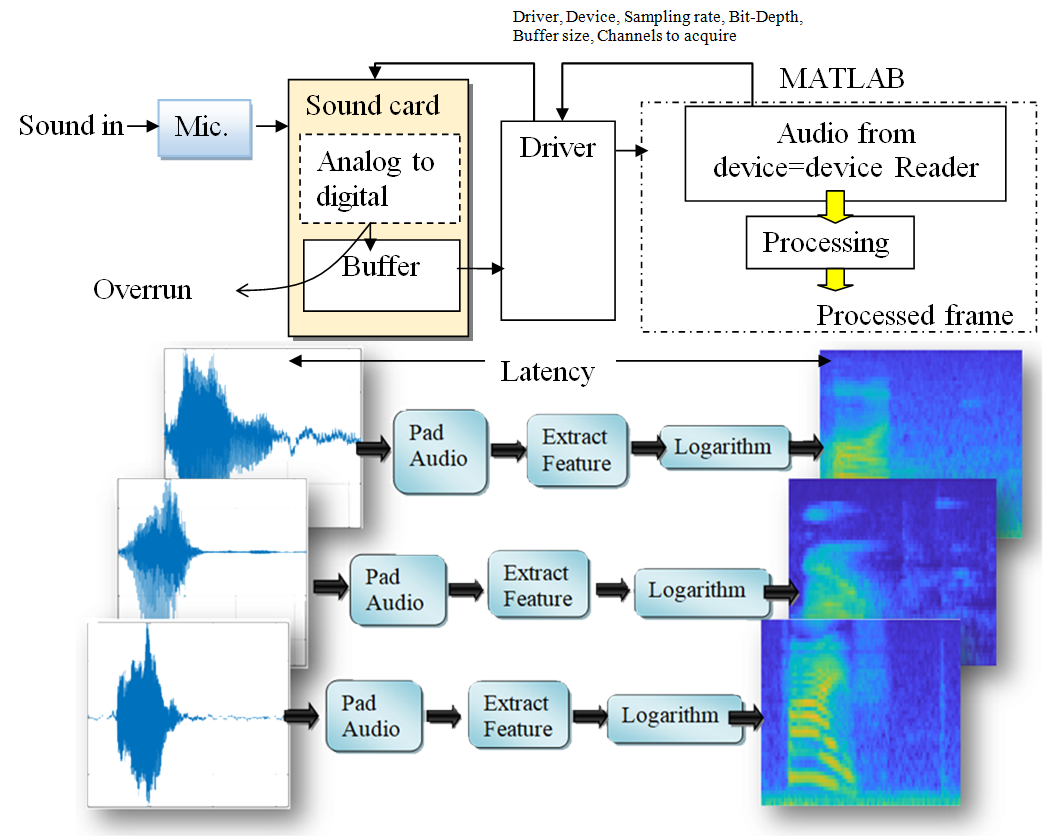
Методи розпізнавання звукових команд є важливими для виконання інструкцій користувача, особливо для людей з обмеженими можливостями. Попередні дослідження не змогли дослідити та класифікувати оптимізацію продуктивності до дванадцяти категорій аудіокоманд. Ця робота розробляє класифікатор звукових команд на основі мікрофона з використанням згорткової нейронної мережі (ЗНМ) з оптимізацією продуктивності для класифікації дванадцяти класів, включаючи фоновий шум і невідомі слова. Методологія в основному включає підготовку вхідних аудіокоманд для навчання, виділення функцій і візуалізацію слухових спектрограм. Потім розробляється класифікатор на основі ЗНМ і оцінюється навчена архітектура. У роботі розглядається мінімізація затримки шляхом оптимізації фази обробки шляхом компіляції коду MATLAB у код C, якщо фаза обробки алгоритмічно досягає піку. Крім того, метод зменшує розмір кадру та збільшує частоту дискретизації, що також сприяє мінімізації затримки та максимізації продуктивності обробки вхідних аудіоданих. До вхідних даних остаточного повністю підключеного рівня додається невеликий викид, щоб зменшити ймовірність того, що мережа запам’ятає певні елементи навчальних даних. Ми досліджували можливість розширення глибини мережі за допомогою згорткових ідентичних елементів, ReLu та шарів пакетної нормалізації для підвищення точності мережі. Прогрес навчання продемонстрував, як швидко зростає точність мережі, досягнувши приблизно 98,1 %, що пояснює здатність мережі перевищувати дані навчання. Ця робота є важливою для розпізнавання мовлення та мовців, таких як розумні будинки та розумні інвалідні візки, особливо для людей з обмеженими можливостями
Спонсор дослідження
- The authors would like to express their deepest gratitude to the Al-Nahrain University Baghdad-Iraq for their support to complete this research.
Посилання
- Suadaa Irfana, M. (2018). The Use Of Voice in Opac Using Google API Voice Recognition & Speech Synthesis and Fullproof Algorithm as Faster Searching Device. International Journal of Engineering & Technology, 7 (3.7), 274. doi: https://doi.org/10.14419/ijet.v7i3.7.16390
- Ali, M. Y., Naeem, S. B., Bhatti, R. (2020). Artificial intelligence tools and perspectives of university librarians: An overview. Business Information Review, 37 (3), 116–124. doi: https://doi.org/10.1177/0266382120952016
- Yossy, E. H., Suparta, W., Trisetyarso, A., Abbas, B. S., Kang, C. H. (2019). Measurement of Usability for Speech Recognition on Ok Google. Studies in Computational Intelligence, 83–94. doi: https://doi.org/10.1007/978-3-030-14132-5_7
- Sprengholz, P., Betsch, C. (2021). Ok Google: Using virtual assistants for data collection in psychological and behavioral research. Behavior Research Methods, 54 (3), 1227–1239. doi: https://doi.org/10.3758/s13428-021-01629-y
- Choi, T. R., Drumwright, M. E. (2021). “OK, Google, why do I use you?” Motivations, post-consumption evaluations, and perceptions of voice AI assistants. Telematics and Informatics, 62, 101628. doi: https://doi.org/10.1016/j.tele.2021.101628
- Adaimi, R., Yong, H., Thomaz, E. (2021). Ok Google, What Am I Doing? Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 5 (1), 1–24. doi: https://doi.org/10.1145/3448090
- Kaur, G., Srivastava, M., Kumar, A. (2018). Integrated Speaker and Speech Recognition for Wheel Chair Movement Using Artificial Intelligence. Informatica, 42 (4). doi: https://doi.org/10.31449/inf.v42i4.2003
- Vafeiadis, A., Votis, K., Giakoumis, D., Tzovaras, D., Chen, L., Hamzaoui, R. (2020). Audio content analysis for unobtrusive event detection in smart homes. Engineering Applications of Artificial Intelligence, 89, 103226. doi: https://doi.org/10.1016/j.engappai.2019.08.020
- Moon, J. M., Chun, C. J., Kim, J. H., Kim, H. K., Kim, T. W. (2019). Multi-Channel Audio Source Separation Using Azimuth-Frequency Analysis and Convolutional Neural Network. 2019 International Conference on Artificial Intelligence in Information and Communication (ICAIIC). doi: https://doi.org/10.1109/icaiic.2019.8668841
- Jwaid, W. M., Al-Husseini, Z. S. M., Sabry, A. H. (2021). Development of brain tumor segmentation of magnetic resonance imaging (MRI) using U-Net deep learning. Eastern-European Journal of Enterprise Technologies, 4 (9 (112)), 23–31. doi: https://doi.org/10.15587/1729-4061.2021.238957
- Hamza, A. H., Hussein, S. A., Ismaeel, G. A., Abbas, S. Q., Zahra, M. M. A., Sabry, A. H. (2022). Developing three dimensional localization system using deep learning and pre-trained architectures for IEEE 802.11 Wi-Fi. Eastern-European Journal of Enterprise Technologies, 4 (9 (118)), 41–47. doi: https://doi.org/10.15587/1729-4061.2022.263185
- Mohite, R. B., Lamba, O. S. (2021). Classifier Comparison for Blind Source Separation. 2021 International Conference on Smart Generation Computing, Communication and Networking (SMART GENCON). doi: https://doi.org/10.1109/smartgencon51891.2021.9645821
- Yosrita, E., Heryadi, Y., Budiharto, W. (2020). Words classifier of imagined speech based on EEG for patients with disabilities. ICIC Express Letters, 14 (1), 37–41. doi: https://doi.org/10.24507/icicel.14.01.37
- Nanni, L., Costa, Y. M. G., Aguiar, R. L., Mangolin, R. B., Brahnam, S., Silla, C. N. (2020). Ensemble of convolutional neural networks to improve animal audio classification. EURASIP Journal on Audio, Speech, and Music Processing, 2020 (1). doi: https://doi.org/10.1186/s13636-020-00175-3
- Xu, G., Wu, Y., Li, M. (2020). The Study of Influence of Sound on Visual ERP-Based Brain Computer Interface. Sensors, 20 (4), 1203. doi: https://doi.org/10.3390/s20041203
- Sharma, S. (2021). Emotion Recognition from Speech using Artificial Neural Networks and Recurrent Neural Networks. 2021 11th International Conference on Cloud Computing, Data Science & Engineering (Confluence). doi: https://doi.org/10.1109/confluence51648.2021.9377192
- Speech datasets for conversational AI, ASR and IVR. Available at: https://stagezero.ai/off-the-shelf-speech-datasets/?gclid=CjwKCAiAy_CcBhBeEiwAcoMRHI58ioKouVJ_nLmGJGX9cqOpu6tRUwfmjMQGCHuvBfKN9u4lB6AjhxoC-BYQAvD_BwE
- Esmaeilpour, M., Cardinal, P., Lameiras Koerich, A. (2020). Unsupervised feature learning for environmental sound classification using Weighted Cycle-Consistent Generative Adversarial Network. Applied Soft Computing, 86, 105912. doi: https://doi.org/10.1016/j.asoc.2019.105912
- Shashidhar, R., Patilkulkarni, S. (2021). Visual speech recognition for small scale dataset using VGG16 convolution neural network. Multimedia Tools and Applications, 80 (19), 28941–28952. doi: https://doi.org/10.1007/s11042-021-11119-0
- Sinha, H., Awasthi, V., Ajmera, P. K. (2020). Audio classification using braided convolutional neural networks. IET Signal Processing, 14 (7), 448–454. doi: https://doi.org/10.1049/iet-spr.2019.0381
##submission.downloads##
Опубліковано
Як цитувати
Номер
Розділ
Ліцензія
Авторське право (c) 2023 Shakir Mahmood Mahdi, Sabreen Ali Hussein, Hayder Mahmood Salman, Alyaa Hamel Sfayyih, Nasri Bin Sulaiman

Ця робота ліцензується відповідно до Creative Commons Attribution 4.0 International License.
Закріплення та умови передачі авторських прав (ідентифікація авторства) здійснюється у Ліцензійному договорі. Зокрема, автори залишають за собою право на авторство свого рукопису та передають журналу право першої публікації цієї роботи на умовах ліцензії Creative Commons CC BY. При цьому вони мають право укладати самостійно додаткові угоди, що стосуються неексклюзивного поширення роботи у тому вигляді, в якому вона була опублікована цим журналом, але за умови збереження посилання на першу публікацію статті в цьому журналі.
Ліцензійний договір – це документ, в якому автор гарантує, що володіє усіма авторськими правами на твір (рукопис, статтю, тощо).
Автори, підписуючи Ліцензійний договір з ПП «ТЕХНОЛОГІЧНИЙ ЦЕНТР», мають усі права на подальше використання свого твору за умови посилання на наше видання, в якому твір опублікований. Відповідно до умов Ліцензійного договору, Видавець ПП «ТЕХНОЛОГІЧНИЙ ЦЕНТР» не забирає ваші авторські права та отримує від авторів дозвіл на використання та розповсюдження публікації через світові наукові ресурси (власні електронні ресурси, наукометричні бази даних, репозитарії, бібліотеки тощо).
За відсутності підписаного Ліцензійного договору або за відсутністю вказаних в цьому договорі ідентифікаторів, що дають змогу ідентифікувати особу автора, редакція не має права працювати з рукописом.
Важливо пам’ятати, що існує і інший тип угоди між авторами та видавцями – коли авторські права передаються від авторів до видавця. В такому разі автори втрачають права власності на свій твір та не можуть його використовувати в будь-який спосіб.







