Моделювання кредитного шахрайства при незбалансованих даних на основі бегінгу та байєсівської оптимізації
DOI:
https://doi.org/10.15587/1729-4061.2023.279936Ключові слова:
незбалансовані дані, байєсівська оптимізація, випадковий ліс, класи більшості та меншостіАнотація
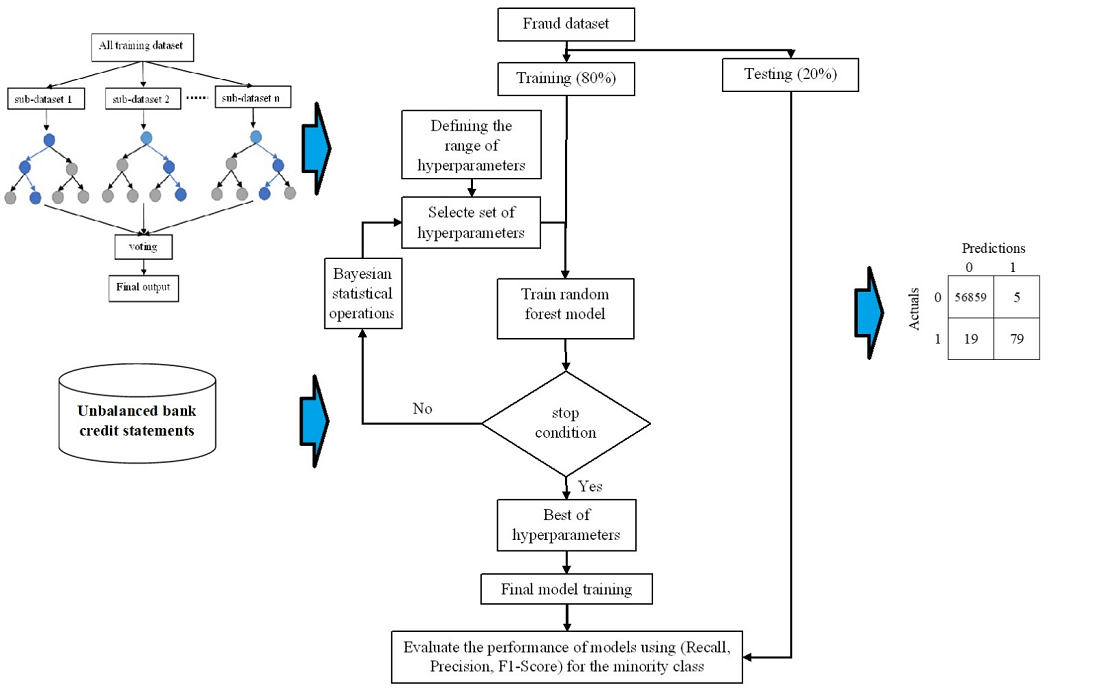
Моделювання кредитного шахрайства є важливою областю досліджень, що має велике значення для сфери кредитування. Ефективне управління ризиками є ключовим фактором у наданні якісних кредитних послуг і безпосередньо впливає на рентабельність та коефіцієнт безнадійної заборгованості провідних організацій у даному секторі. Однак, при сильно незбалансованому розподілі даних про кредитне шахрайство можуть виникати шумові похибки, викликані спотворенням інформації, періодичними статистичними помилками та зміщеннями моделі під час навчання. Це може призвести до неправильних результатів для класу меншості (цільового класу) та збільшити ризик перенавчання. У той час як традиційні методи балансування даних дозволяють зменшити зміщення моделей у бік класу більшості при відносно незбалансованих даних, вони можуть виявитися неефективними у випадках сильно незбалансованих. Для вирішення цієї проблеми в роботі пропонується використовувати алгоритми бегінгу, такі як випадковий ліс та бегінг, для моделювання сильно незбалансованих даних про кредитне шахрайство. Байєсівська оптимізація використовується для пошуку гіперпараметрів та визначення точності класу меншості як функції оптимізації для моделі, що тестується на реальних даних про шахрайство з кредитними картками в Європі. Результати запропонованих алгоритмів пакетування порівнюються з традиційними методами балансування даних, такими як збалансований бегінг та збалансований випадковий ліс. Дослідження показало, що традиційні методи балансування даних можуть бути несумісними з надмірно незбалансованими даними, тоді як алгоритми бегінгу є перспективним рішенням для моделювання таких даних. Запропонований метод знаходження гіперпараметрів ефективний при сильно незбалансованих даних. Він дозволив досягти точності, повноти та F1-міри для категорії меншості 0,94, 0,81 і 0,87 відповідно. Дослідження підкреслює важливість вирішення задач, пов’язаних з незбалансованими даними про кредитне шахрайство, для підвищення точності та об’єктивності моделей кредитного шахрайства
Спонсор дослідження
- The authors acknowledge University of Al-Hamdaniya for making laboratories and experimental materials available for this research project.
Посилання
- Patil, Dr. A. (2018). Digital Transformation in Financial Services and Challenges and Opportunities. International Journal of Trend in Scientific Research and Development, Special Issue (Special Issue-ICDEBI2018), 10–12. doi: https://doi.org/10.31142/ijtsrd18661
- McNulty, D., Milne, A. (2021). Bigger Fish to Fry: FinTech and the Digital Transformation of Financial Services. Disruptive Technology in Banking and Finance, 263–281. doi: https://doi.org/10.1007/978-3-030-81835-7_10
- Lokanan, M. E., Sharma, K. (2022). Fraud prediction using machine learning: The case of investment advisors in Canada. Machine Learning with Applications, 8, 100269. doi: https://doi.org/10.1016/j.mlwa.2022.100269
- Roberts, P. (2022). Risk Management Systems. Simplifying Risk Management, 43–66. doi: https://doi.org/10.4324/9781003225157-3
- Meng, C., Zhou, L., Liu, B. (2020). A Case Study in Credit Fraud Detection With SMOTE and XGBoost. Journal of Physics: Conference Series, 1601 (5), 052016. doi: https://doi.org/10.1088/1742-6596/1601/5/052016
- Lin, T.-H., Jiang, J.-R. (2021). Credit Card Fraud Detection with Autoencoder and Probabilistic Random Forest. Mathematics, 9 (21), 2683. doi: https://doi.org/10.3390/math9212683
- Shamsudin, H., Yusof, U. K., Jayalakshmi, A., Akmal Khalid, M. N. (2020). Combining oversampling and undersampling techniques for imbalanced classification: A comparative study using credit card fraudulent transaction dataset. 2020 IEEE 16th International Conference on Control & Automation (ICCA). doi: https://doi.org/10.1109/icca51439.2020.9264517
- Ahammad, J., Hossain, N., Alam, M. S. (2020). Credit Card Fraud Detection using Data Pre-processing on Imbalanced Data - both Oversampling and Undersampling. Proceedings of the International Conference on Computing Advancements. doi: https://doi.org/10.1145/3377049.3377113
- Praveen Mahesh, K., Ashar Afrouz, S., Shaju Areeckal, A. (2022). Detection of fraudulent credit card transactions: A comparative analysis of data sampling and classification techniques. Journal of Physics: Conference Series, 2161 (1), 012072. doi: https://doi.org/10.1088/1742-6596/2161/1/012072
- Wang, S., Dai, Y., Shen, J., Xuan, J. (2021). Research on expansion and classification of imbalanced data based on SMOTE algorithm. Scientific Reports, 11 (1). doi: https://doi.org/10.1038/s41598-021-03430-5
- Klikowski, J Woźniak, M. (2022). Deterministic Sampling Classifier with weighted Bagging for drifted imbalanced data stream classification. Applied Soft Computing, 122, 108855. doi: https://doi.org/10.1016/j.asoc.2022.108855
- Kim, M., Hwang, K.-B. (2022). An empirical evaluation of sampling methods for the classification of imbalanced data. PLOS ONE, 17 (7), e0271260. doi: https://doi.org/10.1371/journal.pone.0271260
- Liu, Z., Cao, W., Gao, Z., Bian, J., Chen, H., Chang, Y., Liu, T.-Y. (2020). Self-paced Ensemble for Highly Imbalanced Massive Data Classification. 2020 IEEE 36th International Conference on Data Engineering (ICDE). doi: https://doi.org/10.1109/icde48307.2020.00078
- Park, S., Lee, H.-W., Im, J. (2022). Resampling-Based Relabeling & Raking Algorithm to One-Class Classification. doi: https://doi.org/10.36227/techrxiv.17712122.v2
- Juez-Gil, M., Arnaiz-González, Á., Rodríguez, J. J., García-Osorio, C. (2021). Experimental evaluation of ensemble classifiers for imbalance in Big Data. Applied Soft Computing, 108, 107447. doi: https://doi.org/10.1016/j.asoc.2021.107447
- Wang, Q., Luo, Z., Huang, J., Feng, Y., Liu, Z. (2017). A Novel Ensemble Method for Imbalanced Data Learning: Bagging of Extrapolation-SMOTE SVM. Computational Intelligence and Neuroscience, 2017, 1–11. doi: https://doi.org/10.1155/2017/1827016
- Singh, G., Chu, L., Wang, L., Pei, J., Tian, Q., Zhang, Y. (2022). Mining Minority-Class Examples with Uncertainty Estimates. Lecture Notes in Computer Science, 258–271. doi: https://doi.org/10.1007/978-3-030-98358-1_21
- Rayhan, F., Ahmed, S., Mahbub, A., Jani, Md. R., Shatabda, S., Farid, D. Md., Rahman, C. M. (2017). MEBoost: Mixing estimators with boosting for imbalanced data classification. 2017 11th International Conference on Software, Knowledge, Information Management and Applications (SKIMA). doi: https://doi.org/10.1109/skima.2017.8294128
- Meng, Q. (2022). Credit Card Fraud Detection Using Feature Fusion-based Machine Learning Model. Highlights in Science, Engineering and Technology, 23, 111–116. doi: https://doi.org/10.54097/hset.v23i.3208
- Zhou, Z.-H. (2020). Ensemble Learning: Foundations and Algorithms. Beijing: Electronic Industry Press.
- Chen, Z., Duan, J., Kang, L., Qiu, G. (2021). A hybrid data-level ensemble to enable learning from highly imbalanced dataset. Information Sciences, 554, 157–176. doi: https://doi.org/10.1016/j.ins.2020.12.023
- Bader-El-Den, M., Teitei, E., Perry, T. (2019). Biased Random Forest For Dealing With the Class Imbalance Problem. IEEE Transactions on Neural Networks and Learning Systems, 30 (7), 2163–2172. doi: https://doi.org/10.1109/tnnls.2018.2878400
- Borah, P., Gupta, D. (2021). Robust twin bounded support vector machines for outliers and imbalanced data. Applied Intelligence, 51 (8), 5314–5343. doi: https://doi.org/10.1007/s10489-020-01847-5
- Gupta, D., Richhariya, B. (2018). Entropy based fuzzy least squares twin support vector machine for class imbalance learning. Applied Intelligence, 48 (11), 4212–4231. doi: https://doi.org/10.1007/s10489-018-1204-4
- Husejinovic, A. (2020). Credit card fraud detection using naive Bayesian and C4.5 decision tree classifiers. Periodicals of Engineering and Natural Sciences, 8 (1), 1–5.
- Kalid, S. N., Ng, K.-H., Tong, G.-K., Khor, K.-C. (2020). A Multiple Classifiers System for Anomaly Detection in Credit Card Data With Unbalanced and Overlapped Classes. IEEE Access, 8, 28210–28221. doi: https://doi.org/10.1109/access.2020.2972009
- Lee, T.-H., Ullah, A., Wang, R. (2019). Bootstrap Aggregating and Random Forest. Advanced Studies in Theoretical and Applied Econometrics, 389–429. doi: https://doi.org/10.1007/978-3-030-31150-6_13
- Denuit, M., Hainaut, D., Trufin, J. (2020). Bagging Trees and Random Forests. Effective Statistical Learning Methods for Actuaries II, 107–130. doi: https://doi.org/10.1007/978-3-030-57556-4_4
- Genuer, R., Poggi, J.-M. (2020). Random Forests. Random Forests with R, 33–55. doi: https://doi.org/10.1007/978-3-030-56485-8_3
- Syam, N., Kaul, R. (2021). Random Forest, Bagging, and Boosting of Decision Trees. Machine Learning and Artificial Intelligence in Marketing and Sales, 139–182. doi: https://doi.org/10.1108/978-1-80043-880-420211006
- Breiman, L. (2001). Random Forests. Machine Learning, 45, 5–32. doi: https://doi.org/10.1023/a:1010933404324
- Hatwell, J., Gaber, M. M., Azad, R. M. A. (2020). CHIRPS: Explaining random forest classification. Artificial Intelligence Review, 53 (8), 5747–5788. doi: https://doi.org/10.1007/s10462-020-09833-6
- Lin, W., Gao, J., Wang, B., Hong, Q. (2021). An Improved Random Forest Classifier for Imbalanced Learning. 2021 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA). doi: https://doi.org/10.1109/icaica52286.2021.9497933
- Sudha, C., Akila, D. (2021). Credit Card Fraud Detection System based on Operational & Transaction features using SVM and Random Forest Classifiers. 2021 2nd International Conference on Computation, Automation and Knowledge Management (ICCAKM). doi: https://doi.org/10.1109/iccakm50778.2021.9357709
- Aung, M. H., Seluka, P. T., Fuata, J. T. R., Tikoisuva, M. J., Cabealawa, M. S., Nand, R. (2020). Random Forest Classifier for Detecting Credit Card Fraud based on Performance Metrics. 2020 IEEE Asia-Pacific Conference on Computer Science and Data Engineering (CSDE). doi: https://doi.org/10.1109/csde50874.2020.9411563
- Credit Card Fraud Detection. Available at: https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud
- Carrington, A. M., Manuel, D. G., Fieguth, P. W., Ramsay, T., Osmani, V., Wernly, B. et al. (2023). Deep ROC Analysis and AUC as Balanced Average Accuracy, for Improved Classifier Selection, Audit and Explanation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45 (1), 329–341. doi: https://doi.org/10.1109/tpami.2022.3145392
- Kamble, S., Desai, A., Vartak, P. (2014). Evaluation and Performance Analysis of Machine Learning Algorithms. International Journal of Engineering Sciences & Research Technology, 3 (5), 789–794.
- Glisic, S. G., Lorenzo, B. (2022). Machine Learning Algorithms. Artificial Intelligence and Quantum Computing for Advanced Wireless Networks, 17–54. doi: https://doi.org/10.1002/9781119790327.ch2
- Piegorsch, W. W. (2020). Confusion Matrix. Wiley StatsRef: Statistics Reference Online, 1–4. doi: https://doi.org/10.1002/9781118445112.stat08244
##submission.downloads##
Опубліковано
Як цитувати
Номер
Розділ
Ліцензія
Авторське право (c) 2023 Mohammed Alaaalden Kashmoola, Samah Fakhri Aziz, Hasan Mudhafar Qays, Naors Y. Anad Alsaleem

Ця робота ліцензується відповідно до Creative Commons Attribution 4.0 International License.
Закріплення та умови передачі авторських прав (ідентифікація авторства) здійснюється у Ліцензійному договорі. Зокрема, автори залишають за собою право на авторство свого рукопису та передають журналу право першої публікації цієї роботи на умовах ліцензії Creative Commons CC BY. При цьому вони мають право укладати самостійно додаткові угоди, що стосуються неексклюзивного поширення роботи у тому вигляді, в якому вона була опублікована цим журналом, але за умови збереження посилання на першу публікацію статті в цьому журналі.
Ліцензійний договір – це документ, в якому автор гарантує, що володіє усіма авторськими правами на твір (рукопис, статтю, тощо).
Автори, підписуючи Ліцензійний договір з ПП «ТЕХНОЛОГІЧНИЙ ЦЕНТР», мають усі права на подальше використання свого твору за умови посилання на наше видання, в якому твір опублікований. Відповідно до умов Ліцензійного договору, Видавець ПП «ТЕХНОЛОГІЧНИЙ ЦЕНТР» не забирає ваші авторські права та отримує від авторів дозвіл на використання та розповсюдження публікації через світові наукові ресурси (власні електронні ресурси, наукометричні бази даних, репозитарії, бібліотеки тощо).
За відсутності підписаного Ліцензійного договору або за відсутністю вказаних в цьому договорі ідентифікаторів, що дають змогу ідентифікувати особу автора, редакція не має права працювати з рукописом.
Важливо пам’ятати, що існує і інший тип угоди між авторами та видавцями – коли авторські права передаються від авторів до видавця. В такому разі автори втрачають права власності на свій твір та не можуть його використовувати в будь-який спосіб.






