Покращення перетворення мовлення на текст для індонезійської мови за допомогою модифікованого трансформатора
DOI:
https://doi.org/10.15587/1729-4061.2026.350949Ключові слова:
АРМ, модифікований трансформатор, SentencePiece, індонезійський набір даних, глибоке навчанняАнотація
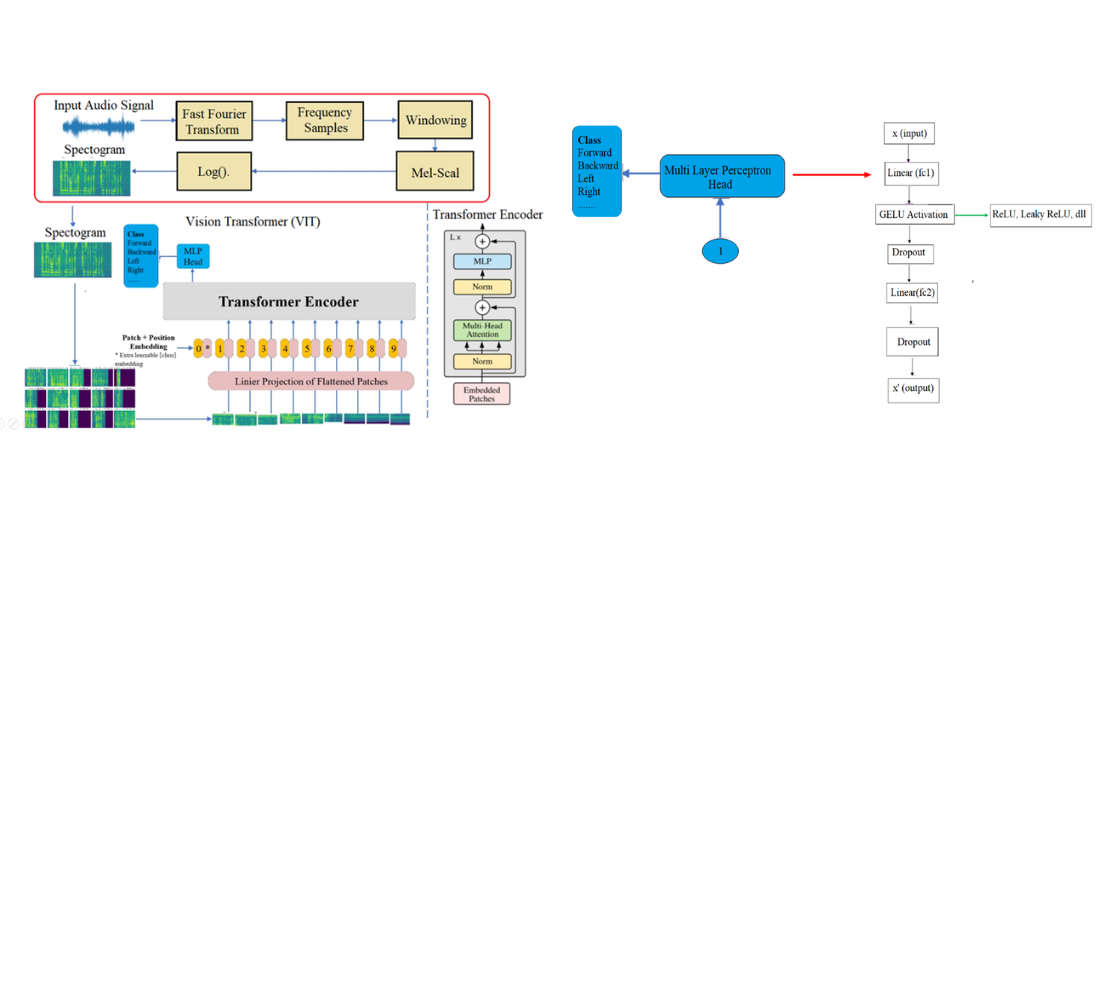
Об'єктом цього дослідження є архітектура автоматичного розпізнавання мовлення (АРМ) на основі трансформатора, навчена з використанням набору даних індонезійської мови, що складається з аудіозаписів та відповідних транскриптів. У цьому дослідженні розглядається розробка системи АРМ для індонезійської мови, яка досі класифікується як мова з низьким рівнем ресурсів, особливо з точки зору доступності набору даних та продуктивності моделі. Проблема, що розглядається в цьому дослідженні, полягає в обмеженій продуктивності стандартної моделі трансформатора в точному розпізнаванні індонезійської мови. Щоб подолати це обмеження, було запропоновано модифікацію кодера, що інтегрує блоки згорткового та візуального трансформатора (ВТ), та порівняно з базовою моделлю. Дані були попередньо оброблені шляхом перетворення монофонічного аудіо 16 кГц, сегментації паузи, фільтрації передвиборчого акценту, вилучення логарифмічної спектрограми Mel, нормалізації та токенізації підслів за допомогою SentencePiece з байтовим парним кодуванням. Набір даних був розділений на навчальний, валідаційний та тестовий набори у співвідношенні 80:10:10, що складалися з 63 952, 7 994 та 7 994 зразків відповідно. Узагальнення моделі було покращено за допомогою методу доповнення даних SpecAugment. Експериментальні результати показують, що стандартна модель досягає коефіцієнта помилок слів 0,162 та коефіцієнта помилок символів 0,121, тоді як модифікована модель зменшує коефіцієнт помилок слів до 0,158, а коефіцієнт помилок символів до 0,118. Значення цього відкриття полягає в покращеному представленні ознак, що створюється модифікованим кодером, де згортковий блок фіксує локальні акустичні патерни, а блок ВТ покращує моделювання глобального контексту на спектрограмі. Цей додатковий механізм пояснює зменшення помилок на рівні слів, що є вирішальним для надійної системи перетворення мовлення в текст. Отже, запропоновану модель можна застосовувати для двостороннього зв'язку в реальному часі в сервісних роботах
Посилання
- Loubser, A., De Villiers, P., De Freitas, A. (2024). End-to-end automated speech recognition using a character based small scale transformer architecture. Expert Systems with Applications, 252, 124119. https://doi.org/10.1016/j.eswa.2024.124119
- Ro, J. H., Stahlberg, F., Wu, K., Kumar, S. (2022). Transformer-based Models of Text Normalization for Speech Applications. arXiv. https://doi.org/10.48550/arXiv.2202.00153
- Alastruey, B., Gállego, G. I., Costa-jussà, M. R. (2021). Efficient Transformer for Direct Speech Translation. arXiv. https://doi.org/10.48550/arXiv.2107.03069
- KHu, K., Pang, R., Sainath, T. N., Strohman, T. (2021). Transformer Based Deliberation for Two-Pass Speech Recognition. 2021 IEEE Spoken Language Technology Workshop (SLT), 68–74. https://doi.org/10.1109/slt48900.2021.9383497
- Le, P.-H., Gong, H., Wang, C., Pino, J., Lecouteux, B., Schwab, D. (2023). Pre-training for Speech Translation: CTC Meets Optimal Transport. arXiv. https://doi.org/10.48550/arXiv.2301.11716
- Ahmadian, H., Abidin, T. F., Riza, H., Muchtar, K. (2023). Transformer-Based Indonesian Language Model for Emotion Classification and Sentiment Analysis. 2023 International Conference on Information Technology and Computing (ICITCOM), 209–214. https://doi.org/10.1109/icitcom60176.2023.10442970
- Heryadi, Y., Wijanarko, B. D., Fitria Murad, D., Tho, C., Hashimoto, K. (2022). The Effect of Encoder and Decoder Stack Depth of Transformer Model to Performance of Machine Translator for Low-resource Languages. Proceedings of the International Conference on Industrial Engineering and Operations Management, 2766–2776. https://doi.org/10.46254/ap03.20220479
- Heryadi, Y., Wijanarko, B. D., Fitria Murad, D., Tho, C., Hashimoto, K. (2023). Revalidating the Encoder-Decoder Depths and Activation Function to Find Optimum Vanilla Transformer Model. 2023 International Conference on Computer Science, Information Technology and Engineering (ICCoSITE), 162–167. https://doi.org/10.1109/iccosite57641.2023.10127790
- Sonata, I., Heryadi, Y., Tho, C. (2023). Topic Segmentation using Transformer Model for Indonesian Text. Procedia Computer Science, 227, 159–167. https://doi.org/10.1016/j.procs.2023.10.513
- Suyanto, S., Arifianto, A., Sirwan, A., Rizaendra, A. P. (2020). End-to-End Speech Recognition Models for a Low-Resourced Indonesian Language. 2020 8th International Conference on Information and Communication Technology (ICoICT), 1–6. https://doi.org/10.1109/icoict49345.2020.9166346
- Sonata, I. (2023). Automatic Speech Recognition in Indonesian Using the Transformer Model. 2023 International Conference on Informatics, Multimedia, Cyber and Informations System (ICIMCIS), 263–266. https://doi.org/10.1109/icimcis60089.2023.10349042
- Wijanarko, B. D., Fitria Murad, D., Heryadi, Y., Tho, C., Hashimoto, K. (2023). Exploring the Effect of Activation Function on Transformer Model Performance for Official Announcement Translator from Indonesian to Sundanese Languages. 2023 International Conference on Computer Science, Information Technology and Engineering (ICCoSITE), 827–831. https://doi.org/10.1109/iccosite57641.2023.10127770
- Wongso, W., Setiawan, D. S., Suhartono, D. (2021). Causal and Masked Language Modeling of Javanese Language using Transformer-based Architectures. 2021 International Conference on Advanced Computer Science and Information Systems (ICACSIS), 1–7. https://doi.org/10.1109/icacsis53237.2021.9631331
- Fuadi, M., Wibawa, A. D., Sumpeno, S. (2023). idT5: Indonesian Version of Multilingual T5 Transformer. arXiv. https://doi.org/10.48550/arXiv.2302.00856
- Musyafa, A., Gao, Y., Solyman, A., Wu, C., Khan, S. (2022). Automatic Correction of Indonesian Grammatical Errors Based on Transformer. Applied Sciences, 12 (20), 10380. https://doi.org/10.3390/app122010380
- Fudholi, D. H., Nayoan, R. A. N. (2022). The Role of Transformer-based Image Captioning for Indoor Environment Visual Understanding. International Journal of Computing and Digital Systems, 12 (3), 479–488. https://doi.org/10.12785/ijcds/120138
- Aditya Rachman, A., Suyanto, S., Rachmawati, E. (2021). Leveraging CNN and Bi-LSTM in Indonesian G2P Using Transformer. 2021 13th International Conference on Machine Learning and Computing, 161–165. https://doi.org/10.1145/3457682.3457706
- Sirwan, A., Thama, K. A., Suyanto, S. (2022). Indonesian Automatic Speech Recognition Based on End-to-end Deep Learning Model. 2022 IEEE International Conference on Cybernetics and Computational Intelligence (CyberneticsCom), 410–415. https://doi.org/10.1109/cyberneticscom55287.2022.9865253
- Warto, Muljono, Purwanto, Noersasongko, E. (2023). Improving Named Entity Recognition in Bahasa Indonesia with Transformer-Word2Vec-CNN-Attention Model. International Journal of Intelligent Engineering and Systems, 16 (4), 655–668. https://doi.org/10.22266/ijies2023.0831.53
- Hutama, L. B., Suhartono, D. (2022). Indonesian Hoax News Classification with Multilingual Transformer Model and BERTopic. Informatica, 46 (8). https://doi.org/10.31449/inf.v46i8.4336
- Lin, T., Wang, Y., Liu, X., Qiu, X. (2022). A survey of transformers. AI Open, 3, 111–132. https://doi.org/10.1016/j.aiopen.2022.10.001
- Xu, P., Zhu, X., Clifton, D. A. (2023). Multimodal Learning With Transformers: A Survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45 (10), 12113–12132. https://doi.org/10.1109/tpami.2023.3275156
##submission.downloads##
Опубліковано
Як цитувати
Номер
Розділ
Ліцензія
Авторське право (c) 2026 Ratna Atika, Suci Dwijayanti, Bhakti Yudho Suprapto

Ця робота ліцензується відповідно до Creative Commons Attribution 4.0 International License.
Закріплення та умови передачі авторських прав (ідентифікація авторства) здійснюється у Ліцензійному договорі. Зокрема, автори залишають за собою право на авторство свого рукопису та передають журналу право першої публікації цієї роботи на умовах ліцензії Creative Commons CC BY. При цьому вони мають право укладати самостійно додаткові угоди, що стосуються неексклюзивного поширення роботи у тому вигляді, в якому вона була опублікована цим журналом, але за умови збереження посилання на першу публікацію статті в цьому журналі.
Ліцензійний договір – це документ, в якому автор гарантує, що володіє усіма авторськими правами на твір (рукопис, статтю, тощо).
Автори, підписуючи Ліцензійний договір з ПП «ТЕХНОЛОГІЧНИЙ ЦЕНТР», мають усі права на подальше використання свого твору за умови посилання на наше видання, в якому твір опублікований. Відповідно до умов Ліцензійного договору, Видавець ПП «ТЕХНОЛОГІЧНИЙ ЦЕНТР» не забирає ваші авторські права та отримує від авторів дозвіл на використання та розповсюдження публікації через світові наукові ресурси (власні електронні ресурси, наукометричні бази даних, репозитарії, бібліотеки тощо).
За відсутності підписаного Ліцензійного договору або за відсутністю вказаних в цьому договорі ідентифікаторів, що дають змогу ідентифікувати особу автора, редакція не має права працювати з рукописом.
Важливо пам’ятати, що існує і інший тип угоди між авторами та видавцями – коли авторські права передаються від авторів до видавця. В такому разі автори втрачають права власності на свій твір та не можуть його використовувати в будь-який спосіб.






