Developing microphone-based audio commands classifier using convolutional neural network
DOI:
https://doi.org/10.15587/1729-4061.2023.273492Keywords:
audio, commands, spectrogram, classifier, deep-learning, CNN, network, real-timeAbstract
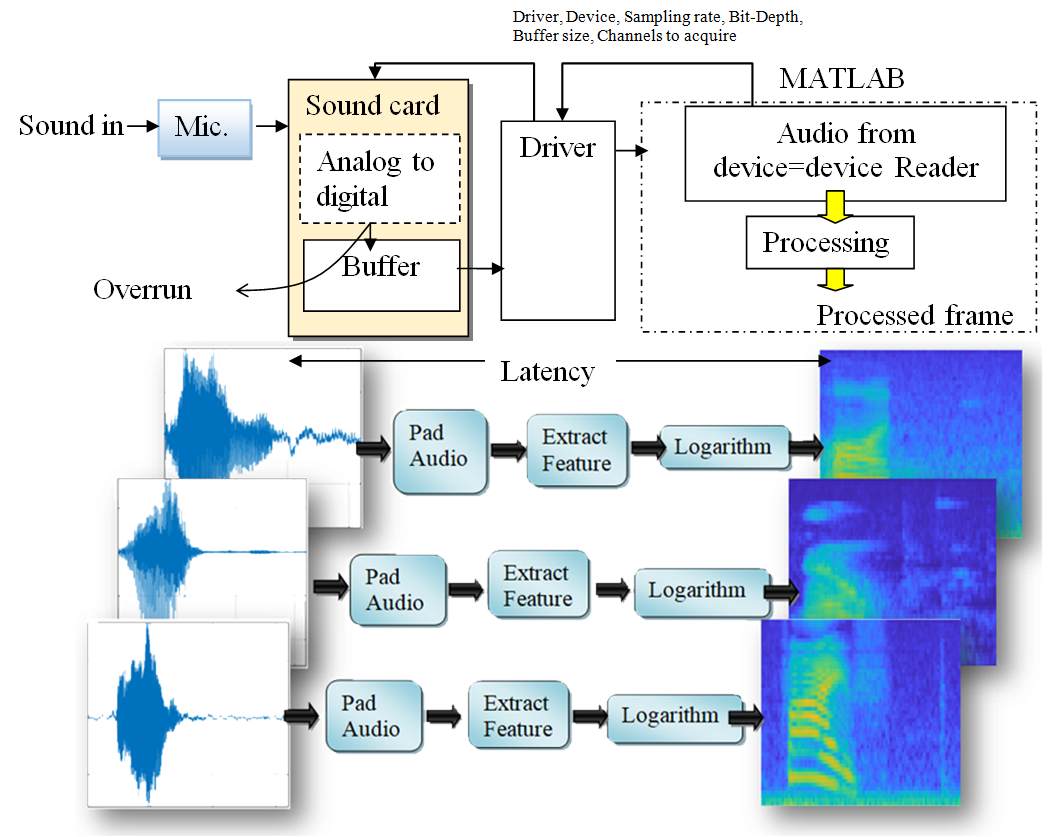
Audio command recognition methods are essential to be recognized for performing user instructions, especially for people with disabilities. Previous studies couldn’t examine and classify the performance optimization of up to twelve audio commands categories. This work develops a microphone-based audio commands classifier using a convolutional neural network (CNN) with performance optimization to categorize twelve classes including background noise and unknown words. The methodology mainly includes preparing the input audio commands for training, extracting features, and visualizing auditory spectrograms. Then a CNN-based classifier is developed and the trained architecture is evaluated. The work considers minimizing latency by optimizing the processing phase by compiling MATLAB code into C code if the processing phase reaches a peak algorithmically. In addition, the method conducts decreasing the frame size and increases the sample rate that is also contributed to minimizing latency and maximizing the performance of processing audio input data. A modest bit of dropout to the input to the final fully connected layer is added to lessen the likelihood that the network will memorize particular elements of the training data. We explored expanding the network depth by including convolutional identical elements, ReLu, and batch normalization layers to improve the network's accuracy. The training progress demonstrated how fast the accuracy of the network is increasing to reach about 98.1 %, which interprets the ability of the network to over-fit the data of training. This work is essential to serve speech and speaker recognition such as smart homes and smart wheelchairs, especially for people with disabilities
Supporting Agency
- The authors would like to express their deepest gratitude to the Al-Nahrain University Baghdad-Iraq for their support to complete this research.
References
- Suadaa Irfana, M. (2018). The Use Of Voice in Opac Using Google API Voice Recognition & Speech Synthesis and Fullproof Algorithm as Faster Searching Device. International Journal of Engineering & Technology, 7 (3.7), 274. doi: https://doi.org/10.14419/ijet.v7i3.7.16390
- Ali, M. Y., Naeem, S. B., Bhatti, R. (2020). Artificial intelligence tools and perspectives of university librarians: An overview. Business Information Review, 37 (3), 116–124. doi: https://doi.org/10.1177/0266382120952016
- Yossy, E. H., Suparta, W., Trisetyarso, A., Abbas, B. S., Kang, C. H. (2019). Measurement of Usability for Speech Recognition on Ok Google. Studies in Computational Intelligence, 83–94. doi: https://doi.org/10.1007/978-3-030-14132-5_7
- Sprengholz, P., Betsch, C. (2021). Ok Google: Using virtual assistants for data collection in psychological and behavioral research. Behavior Research Methods, 54 (3), 1227–1239. doi: https://doi.org/10.3758/s13428-021-01629-y
- Choi, T. R., Drumwright, M. E. (2021). “OK, Google, why do I use you?” Motivations, post-consumption evaluations, and perceptions of voice AI assistants. Telematics and Informatics, 62, 101628. doi: https://doi.org/10.1016/j.tele.2021.101628
- Adaimi, R., Yong, H., Thomaz, E. (2021). Ok Google, What Am I Doing? Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 5 (1), 1–24. doi: https://doi.org/10.1145/3448090
- Kaur, G., Srivastava, M., Kumar, A. (2018). Integrated Speaker and Speech Recognition for Wheel Chair Movement Using Artificial Intelligence. Informatica, 42 (4). doi: https://doi.org/10.31449/inf.v42i4.2003
- Vafeiadis, A., Votis, K., Giakoumis, D., Tzovaras, D., Chen, L., Hamzaoui, R. (2020). Audio content analysis for unobtrusive event detection in smart homes. Engineering Applications of Artificial Intelligence, 89, 103226. doi: https://doi.org/10.1016/j.engappai.2019.08.020
- Moon, J. M., Chun, C. J., Kim, J. H., Kim, H. K., Kim, T. W. (2019). Multi-Channel Audio Source Separation Using Azimuth-Frequency Analysis and Convolutional Neural Network. 2019 International Conference on Artificial Intelligence in Information and Communication (ICAIIC). doi: https://doi.org/10.1109/icaiic.2019.8668841
- Jwaid, W. M., Al-Husseini, Z. S. M., Sabry, A. H. (2021). Development of brain tumor segmentation of magnetic resonance imaging (MRI) using U-Net deep learning. Eastern-European Journal of Enterprise Technologies, 4 (9 (112)), 23–31. doi: https://doi.org/10.15587/1729-4061.2021.238957
- Hamza, A. H., Hussein, S. A., Ismaeel, G. A., Abbas, S. Q., Zahra, M. M. A., Sabry, A. H. (2022). Developing three dimensional localization system using deep learning and pre-trained architectures for IEEE 802.11 Wi-Fi. Eastern-European Journal of Enterprise Technologies, 4 (9 (118)), 41–47. doi: https://doi.org/10.15587/1729-4061.2022.263185
- Mohite, R. B., Lamba, O. S. (2021). Classifier Comparison for Blind Source Separation. 2021 International Conference on Smart Generation Computing, Communication and Networking (SMART GENCON). doi: https://doi.org/10.1109/smartgencon51891.2021.9645821
- Yosrita, E., Heryadi, Y., Budiharto, W. (2020). Words classifier of imagined speech based on EEG for patients with disabilities. ICIC Express Letters, 14 (1), 37–41. doi: https://doi.org/10.24507/icicel.14.01.37
- Nanni, L., Costa, Y. M. G., Aguiar, R. L., Mangolin, R. B., Brahnam, S., Silla, C. N. (2020). Ensemble of convolutional neural networks to improve animal audio classification. EURASIP Journal on Audio, Speech, and Music Processing, 2020 (1). doi: https://doi.org/10.1186/s13636-020-00175-3
- Xu, G., Wu, Y., Li, M. (2020). The Study of Influence of Sound on Visual ERP-Based Brain Computer Interface. Sensors, 20 (4), 1203. doi: https://doi.org/10.3390/s20041203
- Sharma, S. (2021). Emotion Recognition from Speech using Artificial Neural Networks and Recurrent Neural Networks. 2021 11th International Conference on Cloud Computing, Data Science & Engineering (Confluence). doi: https://doi.org/10.1109/confluence51648.2021.9377192
- Speech datasets for conversational AI, ASR and IVR. Available at: https://stagezero.ai/off-the-shelf-speech-datasets/?gclid=CjwKCAiAy_CcBhBeEiwAcoMRHI58ioKouVJ_nLmGJGX9cqOpu6tRUwfmjMQGCHuvBfKN9u4lB6AjhxoC-BYQAvD_BwE
- Esmaeilpour, M., Cardinal, P., Lameiras Koerich, A. (2020). Unsupervised feature learning for environmental sound classification using Weighted Cycle-Consistent Generative Adversarial Network. Applied Soft Computing, 86, 105912. doi: https://doi.org/10.1016/j.asoc.2019.105912
- Shashidhar, R., Patilkulkarni, S. (2021). Visual speech recognition for small scale dataset using VGG16 convolution neural network. Multimedia Tools and Applications, 80 (19), 28941–28952. doi: https://doi.org/10.1007/s11042-021-11119-0
- Sinha, H., Awasthi, V., Ajmera, P. K. (2020). Audio classification using braided convolutional neural networks. IET Signal Processing, 14 (7), 448–454. doi: https://doi.org/10.1049/iet-spr.2019.0381
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2023 Shakir Mahmood Mahdi, Sabreen Ali Hussein, Hayder Mahmood Salman, Alyaa Hamel Sfayyih, Nasri Bin Sulaiman

This work is licensed under a Creative Commons Attribution 4.0 International License.
The consolidation and conditions for the transfer of copyright (identification of authorship) is carried out in the License Agreement. In particular, the authors reserve the right to the authorship of their manuscript and transfer the first publication of this work to the journal under the terms of the Creative Commons CC BY license. At the same time, they have the right to conclude on their own additional agreements concerning the non-exclusive distribution of the work in the form in which it was published by this journal, but provided that the link to the first publication of the article in this journal is preserved.
A license agreement is a document in which the author warrants that he/she owns all copyright for the work (manuscript, article, etc.).
The authors, signing the License Agreement with TECHNOLOGY CENTER PC, have all rights to the further use of their work, provided that they link to our edition in which the work was published.
According to the terms of the License Agreement, the Publisher TECHNOLOGY CENTER PC does not take away your copyrights and receives permission from the authors to use and dissemination of the publication through the world's scientific resources (own electronic resources, scientometric databases, repositories, libraries, etc.).
In the absence of a signed License Agreement or in the absence of this agreement of identifiers allowing to identify the identity of the author, the editors have no right to work with the manuscript.
It is important to remember that there is another type of agreement between authors and publishers – when copyright is transferred from the authors to the publisher. In this case, the authors lose ownership of their work and may not use it in any way.






