Accelerating the process of text data corpora generation by the deterministic method
DOI:
https://doi.org/10.15587/1729-4061.2024.298670Keywords:
natural language processing, CorDeGen method, text data corpora, corpora generationAbstract
The object of research is the process of generating text data corpora using the CorDeGen method. The problem solved in this study is the insufficient efficiency of generating corpora of text data by the CorDeGen method according to the speed criterion.
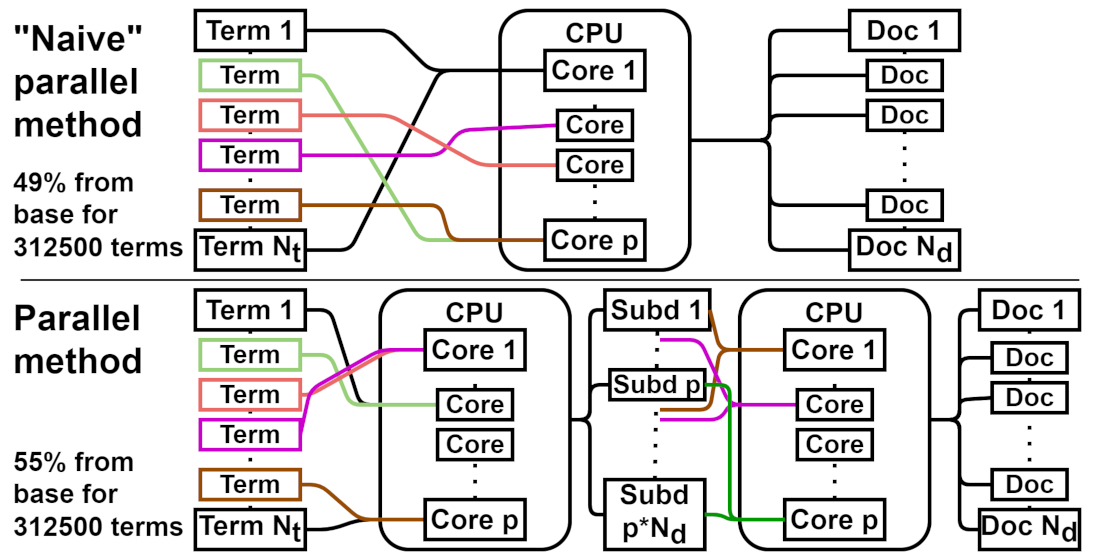
Based on the analysis of the abstract CorDeGen method – the steps it consists of, the algorithm that implements it – the possibilities of its parallelization have been determined. As a result, two new modified methods of the base CorDeGen method were developed: “naive” parallel and parallel. These methods differ from each other in whether they preserve the order of terms in the generated texts compared to the texts generated by the base method (“naive” parallel does not preserve, parallel does). Using the .NET platform and the C# programming language, the software implementation of both proposed methods was performed in this work; a property-based testing methodology was used to validate both implementations.
The results of efficiency testing showed that for corpora of sufficiently large sizes, the use of parallel CorDeGen methods speeds up the generation time by 2 times, compared to the base method. The acceleration effect is explained precisely by the parallelization of the process of generating the next term – its creation, calculation of the number of occurrences of texts, and recording – which takes most of the time in the base method. This means that if it is necessary to generate sufficiently large corpora in a limited time, in practice it is reasonable to use the developed parallel methods of CorDeGen instead of the base one. The choice of a particular parallel method (naive or conventional) for a practical application depends on whether or not the ability to predict the order of terms in the generated texts is important
References
- Dash, N. S., Arulmozi, S. (2018). Definition of ‘Corpus.’ History, Features, and Typology of Language Corpora, 1–15. https://doi.org/10.1007/978-981-10-7458-5_1
- Boujelbane, R., Ellouze Khemekhem, M., Belguith, L. (2013). Mapping Rules for Building a Tunisian Dialect Lexicon and Generating Corpora. Proceedings of the Sixth International Joint Conference on Natural Language Processing. Nagoya, 419–428. Available at: https://aclanthology.org/I13-1048
- Javed, N., Muralidhara, B. L.(2015). Automating Corpora Generation with Semantic Cleaning and Tagging of Tweets for Multi-dimensional Social Media Analytics. International Journal of Computer Applications, 127 (12), 11–16. https://doi.org/10.5120/ijca2015906548
- Alberti, C., Andor, D., Pitler, E., Devlin, J., Collins, M. (2019). Synthetic QA Corpora Generation with Roundtrip Consistency. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. https://doi.org/10.18653/v1/p19-1620
- Lichtarge, J., Alberti, C., Kumar, S., Shazeer, N., Parmar, N., Tong, S. (2019). Corpora Generation for Grammatical Error Correction. Proceedings of the 2019 Conference of the North. https://doi.org/10.18653/v1/n19-1333
- Al-Thwaib, E., Hammo, B. H., Yagi, S. (2020). An academic Arabic corpus for plagiarism detection: design, construction and experimentation. International Journal of Educational Technology in Higher Education, 17 (1). https://doi.org/10.1186/s41239-019-0174-x
- Tanaka, K., Chu, C., Kajiwara, T., Nakashima, Y., Takemura, N., Nagahara, H., Fujikawa, T. (2022). Corpus Construction for Historical Newspapers: A Case Study on Public Meeting Corpus Construction Using OCR Error Correction. SN Computer Science, 3 (6). https://doi.org/10.1007/s42979-022-01393-6
- Yusyn, Y. O., Zabolotnia, T. M. (2021). Text data corpora generation on the basis of the deterministic method. KPI Science News, 3, 38–45. Available at: http://scinews.kpi.ua/article/view/240780
- Yusyn, Ya. O. (2022). Metody ta prohramni zasoby metamorfichnoho testuvannia prohramnykh system avtomatychnoi klasteryzatsiyi pryrodnomovnykh tekstovykh danykh. Kyiv, 357. Available at: https://ela.kpi.ua/handle/123456789/52417
- Parallel programming in .NET: A guide to the documentation (2022). Microsoft Learn. Available at: https://learn.microsoft.com/en-us/dotnet/standard/parallel-programming/
- Claessen, K., Hughes, J. (2000). QuickCheck. Proceedings of the Fifth ACM SIGPLAN International Conference on Functional Programming. https://doi.org/10.1145/351240.351266
- Aichernig, B. K., Schumi, R. (2016). Property-Based Testing with FsCheck by Deriving Properties from Business Rule Models. 2016 IEEE Ninth International Conference on Software Testing, Verification and Validation Workshops (ICSTW). https://doi.org/10.1109/icstw.2016.24
- Overview | BenchmarkDotNet. .NET Foundation and contributors. BenchmarkDotNet. Available at: https://benchmarkdotnet.org/articles/overview.html
- Akinshin, A. (2019). Pro .NET Benchmarking. Apress. https://doi.org/10.1007/978-1-4842-4941-3
- Soukhanov, A. H. (1992). The American Heritage Dictionary of the English Language. Houghton Mifflin.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2024 Yakiv Yusyn, Tetiana Zabolotnia

This work is licensed under a Creative Commons Attribution 4.0 International License.
The consolidation and conditions for the transfer of copyright (identification of authorship) is carried out in the License Agreement. In particular, the authors reserve the right to the authorship of their manuscript and transfer the first publication of this work to the journal under the terms of the Creative Commons CC BY license. At the same time, they have the right to conclude on their own additional agreements concerning the non-exclusive distribution of the work in the form in which it was published by this journal, but provided that the link to the first publication of the article in this journal is preserved.
A license agreement is a document in which the author warrants that he/she owns all copyright for the work (manuscript, article, etc.).
The authors, signing the License Agreement with TECHNOLOGY CENTER PC, have all rights to the further use of their work, provided that they link to our edition in which the work was published.
According to the terms of the License Agreement, the Publisher TECHNOLOGY CENTER PC does not take away your copyrights and receives permission from the authors to use and dissemination of the publication through the world's scientific resources (own electronic resources, scientometric databases, repositories, libraries, etc.).
In the absence of a signed License Agreement or in the absence of this agreement of identifiers allowing to identify the identity of the author, the editors have no right to work with the manuscript.
It is important to remember that there is another type of agreement between authors and publishers – when copyright is transferred from the authors to the publisher. In this case, the authors lose ownership of their work and may not use it in any way.






