Прискорення процесу генерування корпусів текстових даних детермінованим методом
DOI:
https://doi.org/10.15587/1729-4061.2024.298670Ключові слова:
оброблення природної мови, метод CorDeGen, корпуси текстових даних, генерування корпусівАнотація
Об’єктом даного дослідження є процес генерування корпусів текстових даних методом CorDeGen. Проблемою, що вирішується у даному дослідженні, є недостатня ефективність генерування корпусів текстових даних методом CorDeGen за критерієм швидкості.
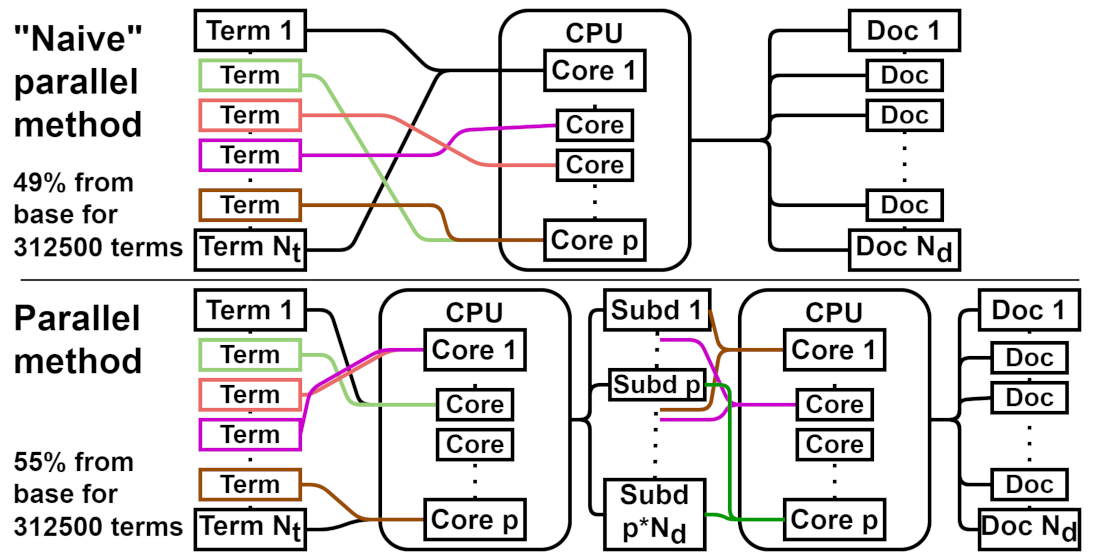
На основі проведеного аналізу базового методу CorDeGen – кроків, з яких він складається, алгоритму, що його реалізовує – визначено можливості його паралелізації. В результаті розроблено два нових методи-модифікації базового методу CorDeGen: «наївний» паралельний та паралельний. Методи відрізняються один від одного тим, чи зберігають вони порядок термів у генерованих текстах в порівнянні з текстами, що генеровані базовим методом («наївний» паралельний не зберігає, паралельний зберігає). Використовуючи платформу .NET та мову програмування C#, у даній роботі виконана програмна реалізація обох запропонованих методів-модифікацій; для валідації обох реалізацій використана методологія тестування на основі властивостей.
Отримані результати тестування ефективності обох паралельних методів показали, що для корпусів достатньо великих розмірів використання паралельних методів CorDeGen прискорює час генерування в 2 рази, порівняно з базовим методом. Ефект прискорення пояснюється саме паралелізацією процесу генерування чергового терму – його створення, визначення кількості входжень до текстів та запису – який займає більшість часу у базовому методі. Це означає, що за необхідності генерувати достатньо великі корпуси за обмежений час, на практиці є доцільним використання саме розроблених паралельних методів CorDeGen замість базового. Вибір конкретного паралельного методу («наївного» чи звичайного) для практичного застосування залежить від того, чи є важливою можливість передбачити порядок термів у генерованих текстах, чи ні
Посилання
- Dash, N. S., Arulmozi, S. (2018). Definition of ‘Corpus.’ History, Features, and Typology of Language Corpora, 1–15. https://doi.org/10.1007/978-981-10-7458-5_1
- Boujelbane, R., Ellouze Khemekhem, M., Belguith, L. (2013). Mapping Rules for Building a Tunisian Dialect Lexicon and Generating Corpora. Proceedings of the Sixth International Joint Conference on Natural Language Processing. Nagoya, 419–428. Available at: https://aclanthology.org/I13-1048
- Javed, N., Muralidhara, B. L.(2015). Automating Corpora Generation with Semantic Cleaning and Tagging of Tweets for Multi-dimensional Social Media Analytics. International Journal of Computer Applications, 127 (12), 11–16. https://doi.org/10.5120/ijca2015906548
- Alberti, C., Andor, D., Pitler, E., Devlin, J., Collins, M. (2019). Synthetic QA Corpora Generation with Roundtrip Consistency. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. https://doi.org/10.18653/v1/p19-1620
- Lichtarge, J., Alberti, C., Kumar, S., Shazeer, N., Parmar, N., Tong, S. (2019). Corpora Generation for Grammatical Error Correction. Proceedings of the 2019 Conference of the North. https://doi.org/10.18653/v1/n19-1333
- Al-Thwaib, E., Hammo, B. H., Yagi, S. (2020). An academic Arabic corpus for plagiarism detection: design, construction and experimentation. International Journal of Educational Technology in Higher Education, 17 (1). https://doi.org/10.1186/s41239-019-0174-x
- Tanaka, K., Chu, C., Kajiwara, T., Nakashima, Y., Takemura, N., Nagahara, H., Fujikawa, T. (2022). Corpus Construction for Historical Newspapers: A Case Study on Public Meeting Corpus Construction Using OCR Error Correction. SN Computer Science, 3 (6). https://doi.org/10.1007/s42979-022-01393-6
- Yusyn, Y. O., Zabolotnia, T. M. (2021). Text data corpora generation on the basis of the deterministic method. KPI Science News, 3, 38–45. Available at: http://scinews.kpi.ua/article/view/240780
- Yusyn, Ya. O. (2022). Metody ta prohramni zasoby metamorfichnoho testuvannia prohramnykh system avtomatychnoi klasteryzatsiyi pryrodnomovnykh tekstovykh danykh. Kyiv, 357. Available at: https://ela.kpi.ua/handle/123456789/52417
- Parallel programming in .NET: A guide to the documentation (2022). Microsoft Learn. Available at: https://learn.microsoft.com/en-us/dotnet/standard/parallel-programming/
- Claessen, K., Hughes, J. (2000). QuickCheck. Proceedings of the Fifth ACM SIGPLAN International Conference on Functional Programming. https://doi.org/10.1145/351240.351266
- Aichernig, B. K., Schumi, R. (2016). Property-Based Testing with FsCheck by Deriving Properties from Business Rule Models. 2016 IEEE Ninth International Conference on Software Testing, Verification and Validation Workshops (ICSTW). https://doi.org/10.1109/icstw.2016.24
- Overview | BenchmarkDotNet. .NET Foundation and contributors. BenchmarkDotNet. Available at: https://benchmarkdotnet.org/articles/overview.html
- Akinshin, A. (2019). Pro .NET Benchmarking. Apress. https://doi.org/10.1007/978-1-4842-4941-3
- Soukhanov, A. H. (1992). The American Heritage Dictionary of the English Language. Houghton Mifflin.
##submission.downloads##
Опубліковано
Як цитувати
Номер
Розділ
Ліцензія
Авторське право (c) 2024 Yakiv Yusyn, Tetiana Zabolotnia

Ця робота ліцензується відповідно до Creative Commons Attribution 4.0 International License.
Закріплення та умови передачі авторських прав (ідентифікація авторства) здійснюється у Ліцензійному договорі. Зокрема, автори залишають за собою право на авторство свого рукопису та передають журналу право першої публікації цієї роботи на умовах ліцензії Creative Commons CC BY. При цьому вони мають право укладати самостійно додаткові угоди, що стосуються неексклюзивного поширення роботи у тому вигляді, в якому вона була опублікована цим журналом, але за умови збереження посилання на першу публікацію статті в цьому журналі.
Ліцензійний договір – це документ, в якому автор гарантує, що володіє усіма авторськими правами на твір (рукопис, статтю, тощо).
Автори, підписуючи Ліцензійний договір з ПП «ТЕХНОЛОГІЧНИЙ ЦЕНТР», мають усі права на подальше використання свого твору за умови посилання на наше видання, в якому твір опублікований. Відповідно до умов Ліцензійного договору, Видавець ПП «ТЕХНОЛОГІЧНИЙ ЦЕНТР» не забирає ваші авторські права та отримує від авторів дозвіл на використання та розповсюдження публікації через світові наукові ресурси (власні електронні ресурси, наукометричні бази даних, репозитарії, бібліотеки тощо).
За відсутності підписаного Ліцензійного договору або за відсутністю вказаних в цьому договорі ідентифікаторів, що дають змогу ідентифікувати особу автора, редакція не має права працювати з рукописом.
Важливо пам’ятати, що існує і інший тип угоди між авторами та видавцями – коли авторські права передаються від авторів до видавця. В такому разі автори втрачають права власності на свій твір та не можуть його використовувати в будь-який спосіб.






