Semantic text splitting method development for rag systems with controlled threshold and sliding window size
DOI:
https://doi.org/10.15587/1729-4061.2025.326177Keywords:
RAG, sliding-window, semantic, chunking, embeddings, binary search, evaluation, tuning, AI, LLMAbstract
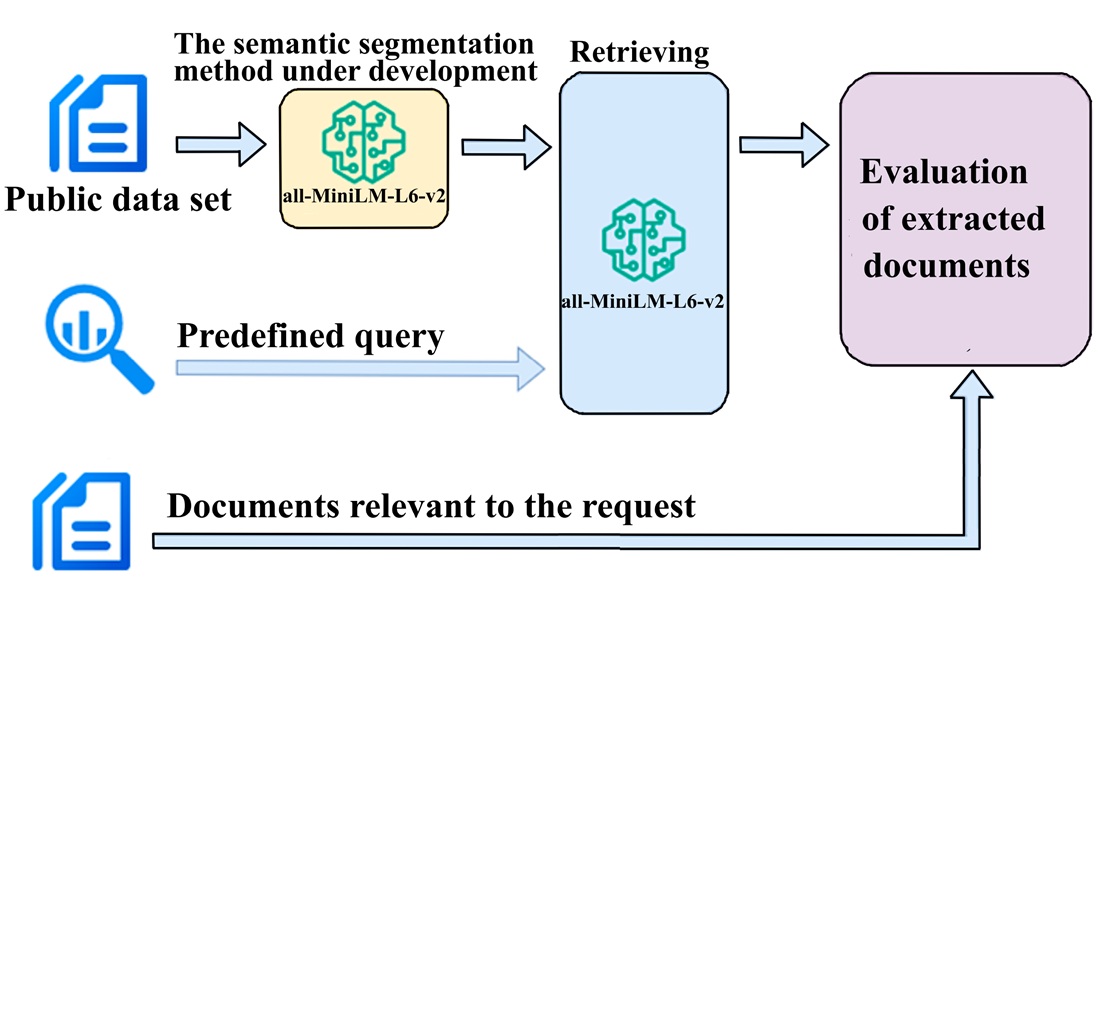
The object of this study is Retrieval-Augmented Generation (RAG) systems used to improve the quality of responses by large language models (LLMs). The task addressed is to improve the efficiency of the semantic text segmentation stage in such systems, which directly affects the accuracy of extracting relevant fragments.
The work reports a method of semantic text segmentation for RAG systems, based on the sliding window technique with a dynamically changing size. The method devised uses embedding models and makes it possible to take into account the semantic context of the text. The adjustable value of the cosine similarity threshold used in semantic splitting makes it possible to additionally increase the relevance of query formation to LLM. The developed algorithm for setting this threshold value makes it possible to more fully take into account the specificity of the query subject. Compared to advanced methods of semantic text segmentation, the method devised provides the following gains depending on the maximum document size parameter: IoU from 0.2 % to 2.8 %, precision from 0.4 % to 3.1 %, omega precision from 1.4 % to 14.8 %. The gains are primarily associated with text processing at the level of semantically complete units in the form of sentences, rather than tokens. In addition, the dynamic sliding window technique allowed for better adaptation to the text structure. The results are valid within the framework of the used evaluation, which covers heterogeneous text datasets, and could be applied in practice when building RAG systems in industries with high requirements for preserving the semantic integrity of the text, for example, in law, science, or technology. The algorithms that implement the proposed method are posted on GitHub as Python libraries
References
- Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H. et al. (2025). A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions. ACM Transactions on Information Systems, 43 (2), 1–55. https://doi.org/10.1145/3703155
- Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., Liang, P. (2024). Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics, 12, 157–173. https://doi.org/10.1162/tacl_a_00638
- Hosseini, P., Castro, I., Ghinassi, I., Purver, M. (2025). Efficient Solutions For An Intriguing Failure of LLMs: Long Context Window Does Not Mean LLMs Can Analyze Long Sequences Flawlessly. arXiv. https://doi.org/10.48550/arXiv.2408.01866
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N. et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv. https://doi.org/10.48550/arXiv.2005.11401
- Ma, X., Gong, Y., He, P., Zhao, H., Duan, N. (2023). Query Rewriting in Retrieval-Augmented Large Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. https://doi.org/10.18653/v1/2023.emnlp-main.322
- Gao, L., Ma, X., Lin, J., Callan, J. (2023). Precise Zero-Shot Dense Retrieval without Relevance Labels. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). https://doi.org/10.18653/v1/2023.acl-long.99
- Chen, T., Wang, H., Chen, S., Yu, W., Ma, K., Zhao, X. et al. (2024). Dense X Retrieval: What Retrieval Granularity Should We Use? Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 15159–15177. https://doi.org/10.18653/v1/2024.emnlp-main.845
- Jiang, Z., Xu, F., Gao, L., Sun, Z., Liu, Q., Dwivedi-Yu, J. et al. (2023). Active Retrieval Augmented Generation. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. https://doi.org/10.18653/v1/2023.emnlp-main.495
- Procko, T. T., Ochoa, O. (2024). Graph Retrieval-Augmented Generation for Large Language Models: A Survey. 2024 Conference on AI, Science, Engineering, and Technology (AIxSET), 166–169. https://doi.org/10.1109/aixset62544.2024.00030
- Kalinowski, A., An, Y. (2021). Exploring Sentence Embedding Structures for Semantic Relation Extraction. 2021 International Joint Conference on Neural Networks (IJCNN), 1–7. https://doi.org/10.1109/ijcnn52387.2021.9534215
- Gao, T., Yao, X., Chen, D. (2021). SimCSE: Simple Contrastive Learning of Sentence Embeddings. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. https://doi.org/10.18653/v1/2021.emnlp-main.552
- Limkonchotiwat, P., Ponwitayarat, W., Lowphansirikul, L., Udomcharoenchaikit, C., Chuangsuwanich, E., Nutanong, S. (2023). An Efficient Self-Supervised Cross-View Training For Sentence Embedding. Transactions of the Association for Computational Linguistics, 11, 1572–1587. https://doi.org/10.1162/tacl_a_00620
- Miao, Z., Wu, Q., Zhao, K., Wu, Z., Tsuruoka, Y. (2024). Enhancing Cross-lingual Sentence Embedding for Low-resource Languages with Word Alignment. Findings of the Association for Computational Linguistics: NAACL 2024, 3225–3236. https://doi.org/10.18653/v1/2024.findings-naacl.204
- Kshirsagar, A. (2024). Enhancing RAG Performance Through Chunking and Text Splitting Techniques. International Journal of Scientific Research in Computer Science, Engineering and Information Technology, 10 (5), 151–158. https://doi.org/10.32628/cseit2410593
- Semchunk. Available at: https://github.com/isaacus-dev/semchunk
- Vector embeddings. Available at: https://platform.openai.com/docs/guides/embeddings
- Kamradt, G. 5 Levels of text splitting. Available at: https://github.com/FullStackRetrieval-com/RetrievalTutorials/blob/main/tutorials/LevelsOfTextSplitting/5_Levels_Of_Text_Splitting.ipynb
- Smith, B., Troynikov, A. (2024). Evaluating Chunking Strategies for Retrieval. Chroma Technical Report. Available at: https://research.trychroma.com/evaluating-chunking
- Research Chunking Strategies. Available at: https://github.com/nesbyte/ResearchChunkingStrategies/blob/main/main.ipynb
- Corpora. Available at: https://github.com/brandonstarxel/chunking_evaluation/tree/main/chunking_evaluation/evaluation_framework/general_evaluation_data/corpora
- Questions. Available at: https://github.com/brandonstarxel/chunking_evaluation/blob/main/chunking_evaluation/evaluation_framework/general_evaluation_data/questions_df.csv
- all-MiniLM-L6-v2. Available at: https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
- MiniLM-L6-H384-uncased. Available at: https://huggingface.co/nreimers/MiniLM-L6-H384-uncased
- Berrier, J. (2021). Move along. Dynamic-Size Sliding Window Pattern/Technique. Available at: https://jamie-berrier.medium.com/move-along-c09d59bea473
- Cosine similarity. Available at: https://en.wikipedia.org/wiki/Cosine_similarity
- Horchunk. Available at: https://github.com/panalexeu/horchunk.git
- Binary search. Available at: https://en.wikipedia.org/wiki/Binary_search
- Recursive character text splitter. Langchain documentation. Available at: https://api.python.langchain.com/en/latest/character/langchain_text_splitters.character.RecursiveCharacterTextSplitter.html
- Token text splitter. Langchain documentation. Available at: https://python.langchain.com/api_reference/text_splitters/base/langchain_text_splitters.base.TokenTextSplitter.html
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2025 Oleg Galchonkov, Oleksii Horchynskyi, Svetlana Antoshchuk, Volodymyr Nareznoy

This work is licensed under a Creative Commons Attribution 4.0 International License.
The consolidation and conditions for the transfer of copyright (identification of authorship) is carried out in the License Agreement. In particular, the authors reserve the right to the authorship of their manuscript and transfer the first publication of this work to the journal under the terms of the Creative Commons CC BY license. At the same time, they have the right to conclude on their own additional agreements concerning the non-exclusive distribution of the work in the form in which it was published by this journal, but provided that the link to the first publication of the article in this journal is preserved.
A license agreement is a document in which the author warrants that he/she owns all copyright for the work (manuscript, article, etc.).
The authors, signing the License Agreement with TECHNOLOGY CENTER PC, have all rights to the further use of their work, provided that they link to our edition in which the work was published.
According to the terms of the License Agreement, the Publisher TECHNOLOGY CENTER PC does not take away your copyrights and receives permission from the authors to use and dissemination of the publication through the world's scientific resources (own electronic resources, scientometric databases, repositories, libraries, etc.).
In the absence of a signed License Agreement or in the absence of this agreement of identifiers allowing to identify the identity of the author, the editors have no right to work with the manuscript.
It is important to remember that there is another type of agreement between authors and publishers – when copyright is transferred from the authors to the publisher. In this case, the authors lose ownership of their work and may not use it in any way.






