Розробка семантичного метода поділу тексту для RAG систем, з керованим порогом та розміром ковзного вікна
DOI:
https://doi.org/10.15587/1729-4061.2025.326177Ключові слова:
RAG, sliding-window, semantic, chunking, embeddings, binary search, evaluation, tuning, AI, LLMАнотація
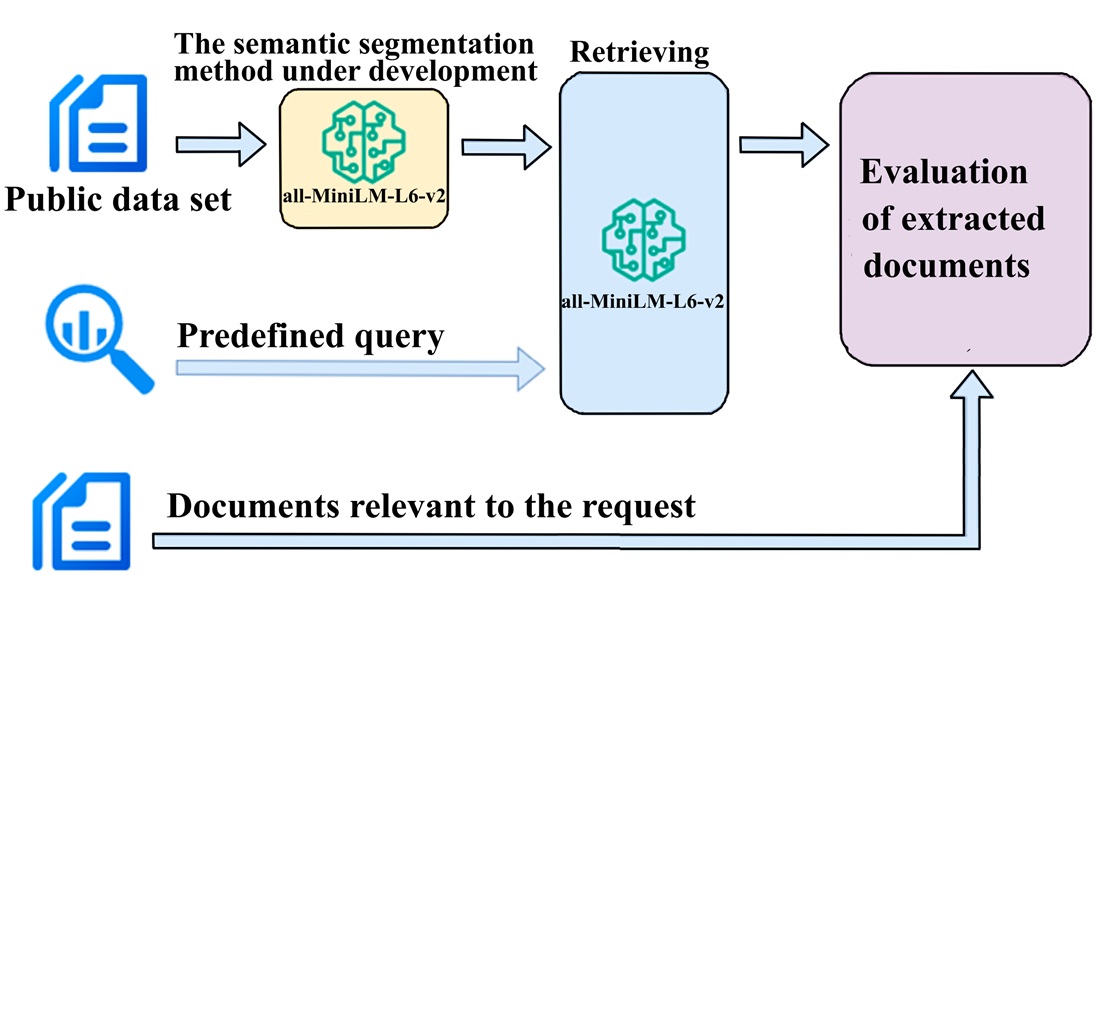
Об’єктом дослідження є системи Retrieval-Augmented Generation (RAG), що використовуються для покращення якості відповідей великих мовних моделей (LLM). Проблема, що вирішується в роботі, полягає у підвищенні ефективності етапу семантичного поділу тексту в таких системах, що безпосередньо впливає на точність витягування релевантних фрагментів.
У роботі представлений метод семантичного поділу тексту для RAG-систем, заснований на техніці ковзного вікна з розміром, що динамічно змінюється. Розроблений метод використовує embedding-моделі та дозволяє враховувати семантичний контекст тексту. Додатково збільшити релевантність формування запитів до LLM дозволяє настроюване значення порога косинусної подібності, що використовується при семантичному розподілі. Розроблений алгоритм налаштування цього порогового значення дозволяє більш повно врахувати специфіку тематики запиту. У порівнянні з передовими методами семантичного поділу тексту розроблений метод дає наступний приріст залежно від параметра максимального розміру документа: IoU від 0.2 % до 2.8 %, точність від 0.4 % до 3.1 %, точність омега від 1.4 % до 14.8 %. Приріст передусім пов’зано з обробкою тексту на рівні семантично повних одиниць у вигляді речень, а не токенів. Крім того, техніка динамічного ковзного вікна дозволила ліпше адаптуватися до структури тексту. Отримані результати є валідними в межах використаного фреймворку оцінки, що охоплює різнорідні текстові датасети, і можуть бути застосовані на практиці при побудові RAG-систем у галузях з високими вимогами до збереження семантичної цілісності тексту, наприклад, у праві, науці чи техніці. Алгоритми, що реализуют запропонований метод, розміщені у GitHub як бібліотеки на Python
Посилання
- Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H. et al. (2025). A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions. ACM Transactions on Information Systems, 43 (2), 1–55. https://doi.org/10.1145/3703155
- Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., Liang, P. (2024). Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics, 12, 157–173. https://doi.org/10.1162/tacl_a_00638
- Hosseini, P., Castro, I., Ghinassi, I., Purver, M. (2025). Efficient Solutions For An Intriguing Failure of LLMs: Long Context Window Does Not Mean LLMs Can Analyze Long Sequences Flawlessly. arXiv. https://doi.org/10.48550/arXiv.2408.01866
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N. et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv. https://doi.org/10.48550/arXiv.2005.11401
- Ma, X., Gong, Y., He, P., Zhao, H., Duan, N. (2023). Query Rewriting in Retrieval-Augmented Large Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. https://doi.org/10.18653/v1/2023.emnlp-main.322
- Gao, L., Ma, X., Lin, J., Callan, J. (2023). Precise Zero-Shot Dense Retrieval without Relevance Labels. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). https://doi.org/10.18653/v1/2023.acl-long.99
- Chen, T., Wang, H., Chen, S., Yu, W., Ma, K., Zhao, X. et al. (2024). Dense X Retrieval: What Retrieval Granularity Should We Use? Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 15159–15177. https://doi.org/10.18653/v1/2024.emnlp-main.845
- Jiang, Z., Xu, F., Gao, L., Sun, Z., Liu, Q., Dwivedi-Yu, J. et al. (2023). Active Retrieval Augmented Generation. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. https://doi.org/10.18653/v1/2023.emnlp-main.495
- Procko, T. T., Ochoa, O. (2024). Graph Retrieval-Augmented Generation for Large Language Models: A Survey. 2024 Conference on AI, Science, Engineering, and Technology (AIxSET), 166–169. https://doi.org/10.1109/aixset62544.2024.00030
- Kalinowski, A., An, Y. (2021). Exploring Sentence Embedding Structures for Semantic Relation Extraction. 2021 International Joint Conference on Neural Networks (IJCNN), 1–7. https://doi.org/10.1109/ijcnn52387.2021.9534215
- Gao, T., Yao, X., Chen, D. (2021). SimCSE: Simple Contrastive Learning of Sentence Embeddings. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. https://doi.org/10.18653/v1/2021.emnlp-main.552
- Limkonchotiwat, P., Ponwitayarat, W., Lowphansirikul, L., Udomcharoenchaikit, C., Chuangsuwanich, E., Nutanong, S. (2023). An Efficient Self-Supervised Cross-View Training For Sentence Embedding. Transactions of the Association for Computational Linguistics, 11, 1572–1587. https://doi.org/10.1162/tacl_a_00620
- Miao, Z., Wu, Q., Zhao, K., Wu, Z., Tsuruoka, Y. (2024). Enhancing Cross-lingual Sentence Embedding for Low-resource Languages with Word Alignment. Findings of the Association for Computational Linguistics: NAACL 2024, 3225–3236. https://doi.org/10.18653/v1/2024.findings-naacl.204
- Kshirsagar, A. (2024). Enhancing RAG Performance Through Chunking and Text Splitting Techniques. International Journal of Scientific Research in Computer Science, Engineering and Information Technology, 10 (5), 151–158. https://doi.org/10.32628/cseit2410593
- Semchunk. Available at: https://github.com/isaacus-dev/semchunk
- Vector embeddings. Available at: https://platform.openai.com/docs/guides/embeddings
- Kamradt, G. 5 Levels of text splitting. Available at: https://github.com/FullStackRetrieval-com/RetrievalTutorials/blob/main/tutorials/LevelsOfTextSplitting/5_Levels_Of_Text_Splitting.ipynb
- Smith, B., Troynikov, A. (2024). Evaluating Chunking Strategies for Retrieval. Chroma Technical Report. Available at: https://research.trychroma.com/evaluating-chunking
- Research Chunking Strategies. Available at: https://github.com/nesbyte/ResearchChunkingStrategies/blob/main/main.ipynb
- Corpora. Available at: https://github.com/brandonstarxel/chunking_evaluation/tree/main/chunking_evaluation/evaluation_framework/general_evaluation_data/corpora
- Questions. Available at: https://github.com/brandonstarxel/chunking_evaluation/blob/main/chunking_evaluation/evaluation_framework/general_evaluation_data/questions_df.csv
- all-MiniLM-L6-v2. Available at: https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
- MiniLM-L6-H384-uncased. Available at: https://huggingface.co/nreimers/MiniLM-L6-H384-uncased
- Berrier, J. (2021). Move along. Dynamic-Size Sliding Window Pattern/Technique. Available at: https://jamie-berrier.medium.com/move-along-c09d59bea473
- Cosine similarity. Available at: https://en.wikipedia.org/wiki/Cosine_similarity
- Horchunk. Available at: https://github.com/panalexeu/horchunk.git
- Binary search. Available at: https://en.wikipedia.org/wiki/Binary_search
- Recursive character text splitter. Langchain documentation. Available at: https://api.python.langchain.com/en/latest/character/langchain_text_splitters.character.RecursiveCharacterTextSplitter.html
- Token text splitter. Langchain documentation. Available at: https://python.langchain.com/api_reference/text_splitters/base/langchain_text_splitters.base.TokenTextSplitter.html
##submission.downloads##
Опубліковано
Як цитувати
Номер
Розділ
Ліцензія
Авторське право (c) 2025 Oleg Galchonkov, Oleksii Horchynskyi, Svetlana Antoshchuk, Volodymyr Nareznoy

Ця робота ліцензується відповідно до Creative Commons Attribution 4.0 International License.
Закріплення та умови передачі авторських прав (ідентифікація авторства) здійснюється у Ліцензійному договорі. Зокрема, автори залишають за собою право на авторство свого рукопису та передають журналу право першої публікації цієї роботи на умовах ліцензії Creative Commons CC BY. При цьому вони мають право укладати самостійно додаткові угоди, що стосуються неексклюзивного поширення роботи у тому вигляді, в якому вона була опублікована цим журналом, але за умови збереження посилання на першу публікацію статті в цьому журналі.
Ліцензійний договір – це документ, в якому автор гарантує, що володіє усіма авторськими правами на твір (рукопис, статтю, тощо).
Автори, підписуючи Ліцензійний договір з ПП «ТЕХНОЛОГІЧНИЙ ЦЕНТР», мають усі права на подальше використання свого твору за умови посилання на наше видання, в якому твір опублікований. Відповідно до умов Ліцензійного договору, Видавець ПП «ТЕХНОЛОГІЧНИЙ ЦЕНТР» не забирає ваші авторські права та отримує від авторів дозвіл на використання та розповсюдження публікації через світові наукові ресурси (власні електронні ресурси, наукометричні бази даних, репозитарії, бібліотеки тощо).
За відсутності підписаного Ліцензійного договору або за відсутністю вказаних в цьому договорі ідентифікаторів, що дають змогу ідентифікувати особу автора, редакція не має права працювати з рукописом.
Важливо пам’ятати, що існує і інший тип угоди між авторами та видавцями – коли авторські права передаються від авторів до видавця. В такому разі автори втрачають права власності на свій твір та не можуть його використовувати в будь-який спосіб.






