Аналіз структури веб-ресурсів з використанням об’єктної моделі
DOI:
https://doi.org/10.15587/1729-4061.2022.265961Ключові слова:
веб-ресурс, DOM дерево, відстань редагування дерев, схожість за структурою та стилемАнотація
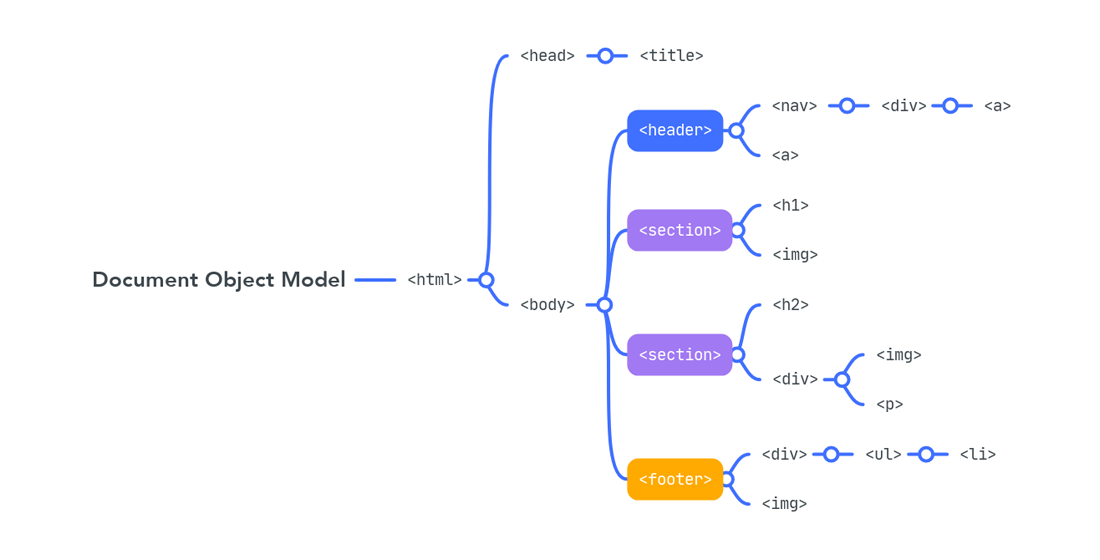
Запропоновано методику аналізу структури веб-ресурсу із застосуванням об’єктної моделі, що будується з опису сторінки мовою HTML та із застосуванням таблиць стилів оформлення. Об’єктом дослідження є сторінка веб-ресурсу, модель якої зображено у вигляді DOM дерева. Данні про структурні елементи дерева доповнюються інформацією про стилі оформлення сторінок. Для визначення схожості сторінок пропонується застосовувати критерій, який враховує структурну та стильову подібність сторінок з відповідними коефіцієнтами. Для порівняння моделей сторінок між собою застосується метод вирівнювання дерев. В якості метрики застосовується відстань редагування, а в якості операцій редагування – операції перейменування, видалення та додавання вузла дерева. Для визначення схожості за стилями застосовується метрика Жаккара. Для кластерізації веб-сторінок застосується метод k-means с косинусної мірою відстані. Внутрикластерний аналіз здійснюється за допомогою модифікації алгоритму Zhang-Shasha. Запропонований підхід реалізовано у вигляді алгоритму та програмного забезпечення з використанням мови програмування Python та відповідних бібліотек. Обчислювальний експеримент виконано для аналізу структури окремих існуючих у мережі Інтернет веб-сайтів, а також для групування сторінок з різних веб-ресурсів. Проаналізовано структуру утворених кластерів, обчислено середньоквадратичну схожість елементів в середині кластерів. Для оцінки якості розробленого підходу для розглянутих задач побудовано експертне розбиття, обчислено значення метрик точності та повноти. Результати аналізу структури веб-ресурсу можна застосовувати для покращення будови компонентів веб-ресурсу, для зрозумілості навігації користувачів на сайті, для проведення реінжинірингу веб-ресурсу
Посилання
- Jain, A., Gupta, B. B. (2017). Phishing Detection: Analysis of Visual Similarity Based Approaches. Security and Communication Networks. doi: https://doi.org/10.1155/2017/5421046
- Vdovin, I. V., Ovchinnikova, R. Y. (2018). Data extraction from the internet network with the use of structural-semantic clustering of web pages. Dynamics of Systems, Mechanisms and Machines (Dynamics), 6 (4), 106–113. doi: https://doi.org/10.25206/2310-9793-2018-6-4-106-113
- Feng, J., Qiao, Y., Ye, O., Zhang, Y. (2022). Detecting phishing webpages via homology analysis of webpage structure. PeerJ Computer Science, 8, e868. doi: https://doi.org/10.7717/peerj-cs.868
- Grigera, J., Gardey, J., Garrido, A., Rossi, G. (2021). A Scoring Map Algorithm for Automatically Detecting Structural Similarity of DOM Elements. Proceedings of the 17th International Conference on Web Information Systems and Technologies. doi: https://doi.org/10.5220/0010716300003058
- Wu, H., Yuan, N. (2018). An Improved TF-IDF algorithm based on word frequency distribution information and category distribution information. Proceedings of the 3rd International Conference on Intelligent Information Processing. doi: https://doi.org/10.1145/3232116.3232152
- Bozkir, A., Sezer, E. (2018). Layout-based computation of web page similarity ranks. International Journal of Human-Computer Studies, 110, 95–114. doi: https://doi.org/10.1016/j.ijhcs.2017.10.008
- Moreno, V., Génova, G., Alejandres, M., Fraga, A. (2020). Automatic Classification of Web Images as UML Static Diagrams Using Machine Learning Techniques. Applied Sciences, 10 (7), 2406. doi: https://doi.org/10.3390/app10072406
- Shin, K., Ishikawa, T., Liu, Y.-L., Shepard, D. L. (2021). Learning DOM Trees of Web Pages by Subpath Kernel and Detecting Fake e-Commerce Sites. Machine Learning and Knowledge Extraction, 3 (1), 95–122. doi: https://doi.org/10.3390/make3010006
- Gowda, T., Mattmann, C. A. (2016). Clustering Web Pages Based on Structure and Style Similarity (Application Paper). IEEE 17th International Conference on Information Reuse and Integration (IRI). doi: https://doi.org/10.1109/IRI.2016.30
- Zhang, K., Shasha, D. (1989). Simple fast algorithms for the editing distance between trees and related problems. SIAM Journal on Computing, 18 (6), 1245–1262. doi: https://doi.org/10.1137/0218082
##submission.downloads##
Опубліковано
Як цитувати
Номер
Розділ
Ліцензія
Авторське право (c) 2022 Stanyslav Dykhanov, Natalia Guk

Ця робота ліцензується відповідно до Creative Commons Attribution 4.0 International License.
Закріплення та умови передачі авторських прав (ідентифікація авторства) здійснюється у Ліцензійному договорі. Зокрема, автори залишають за собою право на авторство свого рукопису та передають журналу право першої публікації цієї роботи на умовах ліцензії Creative Commons CC BY. При цьому вони мають право укладати самостійно додаткові угоди, що стосуються неексклюзивного поширення роботи у тому вигляді, в якому вона була опублікована цим журналом, але за умови збереження посилання на першу публікацію статті в цьому журналі.
Ліцензійний договір – це документ, в якому автор гарантує, що володіє усіма авторськими правами на твір (рукопис, статтю, тощо).
Автори, підписуючи Ліцензійний договір з ПП «ТЕХНОЛОГІЧНИЙ ЦЕНТР», мають усі права на подальше використання свого твору за умови посилання на наше видання, в якому твір опублікований. Відповідно до умов Ліцензійного договору, Видавець ПП «ТЕХНОЛОГІЧНИЙ ЦЕНТР» не забирає ваші авторські права та отримує від авторів дозвіл на використання та розповсюдження публікації через світові наукові ресурси (власні електронні ресурси, наукометричні бази даних, репозитарії, бібліотеки тощо).
За відсутності підписаного Ліцензійного договору або за відсутністю вказаних в цьому договорі ідентифікаторів, що дають змогу ідентифікувати особу автора, редакція не має права працювати з рукописом.
Важливо пам’ятати, що існує і інший тип угоди між авторами та видавцями – коли авторські права передаються від авторів до видавця. В такому разі автори втрачають права власності на свій твір та не можуть його використовувати в будь-який спосіб.






