Analysis of the structure of web resources using the object model
DOI:
https://doi.org/10.15587/1729-4061.2022.265961Keywords:
web resource, DOM tree, tree editing distance, similarity in structure and styleAbstract
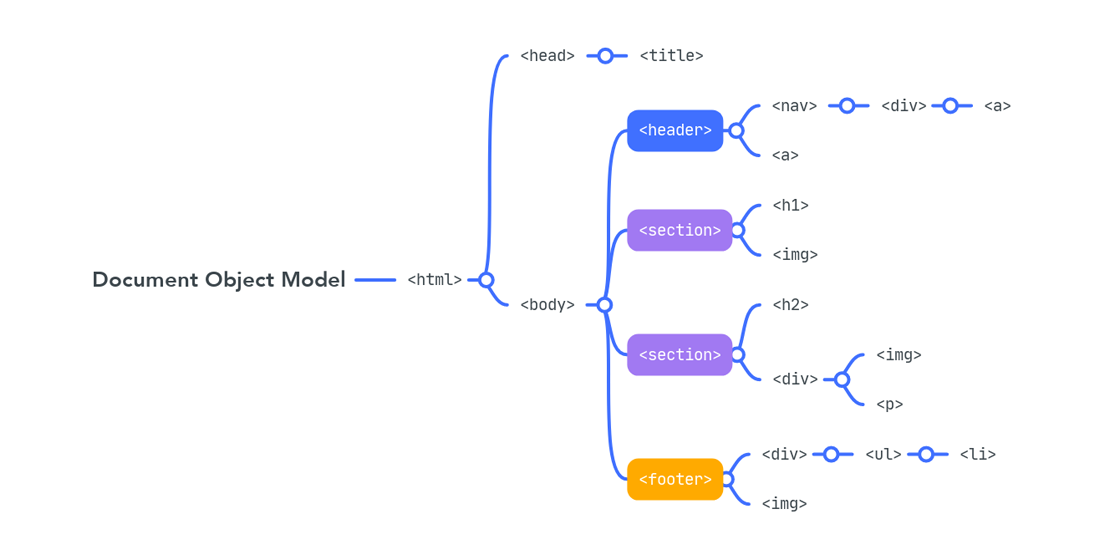
The methodology for analyzing the structure of a web resource using an object model, which is based on the description of the page in HTML and using style sheets, has been proposed. The object of research is a web resource page, the model of which is depicted as a DOM tree. Data on the structural elements of the tree are supplemented with information about the styles of the design of the pages. To determine the similarity of pages, it is proposed to apply a criterion that takes into account the structural and stylistic similarity of pages with the corresponding coefficients. To compare page models with each other, the method of aligning trees will be used. Editing distance is used as a metric, and renaming operations, deleting, and adding a tree node is used as editing operations. To determine the similarity in styles, the Jaccard metric is used. To cluster web pages, the k-means method with a cosine distance measure is applied. Intracluster analysis is carried out using a modification of the Zhang-Shasha algorithm. The proposed approach is implemented in the form of an algorithm and software using Python programming language and related libraries. The computational experiment was performed to analyze the structure of individual websites existing on the Internet, as well as to group pages from different web resources. The structure of the formed clusters was analyzed, the RMS similarity of elements in the middle of the clusters was calculated. To assess the quality of the developed approach for the tasks under consideration, expert partitioning was built, the values of accuracy and completeness metrics were calculated. The results of the analysis of the structure of the web resource can be used to improve the structure of the components of the web resource, to understand the navigation of users on the site, to reengineer the web resource
References
- Jain, A., Gupta, B. B. (2017). Phishing Detection: Analysis of Visual Similarity Based Approaches. Security and Communication Networks. doi: https://doi.org/10.1155/2017/5421046
- Vdovin, I. V., Ovchinnikova, R. Y. (2018). Data extraction from the internet network with the use of structural-semantic clustering of web pages. Dynamics of Systems, Mechanisms and Machines (Dynamics), 6 (4), 106–113. doi: https://doi.org/10.25206/2310-9793-2018-6-4-106-113
- Feng, J., Qiao, Y., Ye, O., Zhang, Y. (2022). Detecting phishing webpages via homology analysis of webpage structure. PeerJ Computer Science, 8, e868. doi: https://doi.org/10.7717/peerj-cs.868
- Grigera, J., Gardey, J., Garrido, A., Rossi, G. (2021). A Scoring Map Algorithm for Automatically Detecting Structural Similarity of DOM Elements. Proceedings of the 17th International Conference on Web Information Systems and Technologies. doi: https://doi.org/10.5220/0010716300003058
- Wu, H., Yuan, N. (2018). An Improved TF-IDF algorithm based on word frequency distribution information and category distribution information. Proceedings of the 3rd International Conference on Intelligent Information Processing. doi: https://doi.org/10.1145/3232116.3232152
- Bozkir, A., Sezer, E. (2018). Layout-based computation of web page similarity ranks. International Journal of Human-Computer Studies, 110, 95–114. doi: https://doi.org/10.1016/j.ijhcs.2017.10.008
- Moreno, V., Génova, G., Alejandres, M., Fraga, A. (2020). Automatic Classification of Web Images as UML Static Diagrams Using Machine Learning Techniques. Applied Sciences, 10 (7), 2406. doi: https://doi.org/10.3390/app10072406
- Shin, K., Ishikawa, T., Liu, Y.-L., Shepard, D. L. (2021). Learning DOM Trees of Web Pages by Subpath Kernel and Detecting Fake e-Commerce Sites. Machine Learning and Knowledge Extraction, 3 (1), 95–122. doi: https://doi.org/10.3390/make3010006
- Gowda, T., Mattmann, C. A. (2016). Clustering Web Pages Based on Structure and Style Similarity (Application Paper). IEEE 17th International Conference on Information Reuse and Integration (IRI). doi: https://doi.org/10.1109/IRI.2016.30
- Zhang, K., Shasha, D. (1989). Simple fast algorithms for the editing distance between trees and related problems. SIAM Journal on Computing, 18 (6), 1245–1262. doi: https://doi.org/10.1137/0218082
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2022 Stanyslav Dykhanov, Natalia Guk

This work is licensed under a Creative Commons Attribution 4.0 International License.
The consolidation and conditions for the transfer of copyright (identification of authorship) is carried out in the License Agreement. In particular, the authors reserve the right to the authorship of their manuscript and transfer the first publication of this work to the journal under the terms of the Creative Commons CC BY license. At the same time, they have the right to conclude on their own additional agreements concerning the non-exclusive distribution of the work in the form in which it was published by this journal, but provided that the link to the first publication of the article in this journal is preserved.
A license agreement is a document in which the author warrants that he/she owns all copyright for the work (manuscript, article, etc.).
The authors, signing the License Agreement with TECHNOLOGY CENTER PC, have all rights to the further use of their work, provided that they link to our edition in which the work was published.
According to the terms of the License Agreement, the Publisher TECHNOLOGY CENTER PC does not take away your copyrights and receives permission from the authors to use and dissemination of the publication through the world's scientific resources (own electronic resources, scientometric databases, repositories, libraries, etc.).
In the absence of a signed License Agreement or in the absence of this agreement of identifiers allowing to identify the identity of the author, the editors have no right to work with the manuscript.
It is important to remember that there is another type of agreement between authors and publishers – when copyright is transferred from the authors to the publisher. In this case, the authors lose ownership of their work and may not use it in any way.





