Recognizing fake news based on natural language processing using the BM25 algorithm with fine-tuned parameters
DOI:
https://doi.org/10.15587/1729-4061.2023.293513Keywords:
BestMatch25, term frequency – inverse document frequency, natural language processing, fake newsAbstract
The object of the research is the method of natural language processing (NLP) with balanced parameters of the BestMatch25 (ВМ25) algorithm to recognize and classify fake news based on natural language processing (NLP). The unsatisfactory accuracy and speed of existing methods for detecting fake news in unstructured input data demanded the development of a new approach for their effective detection.
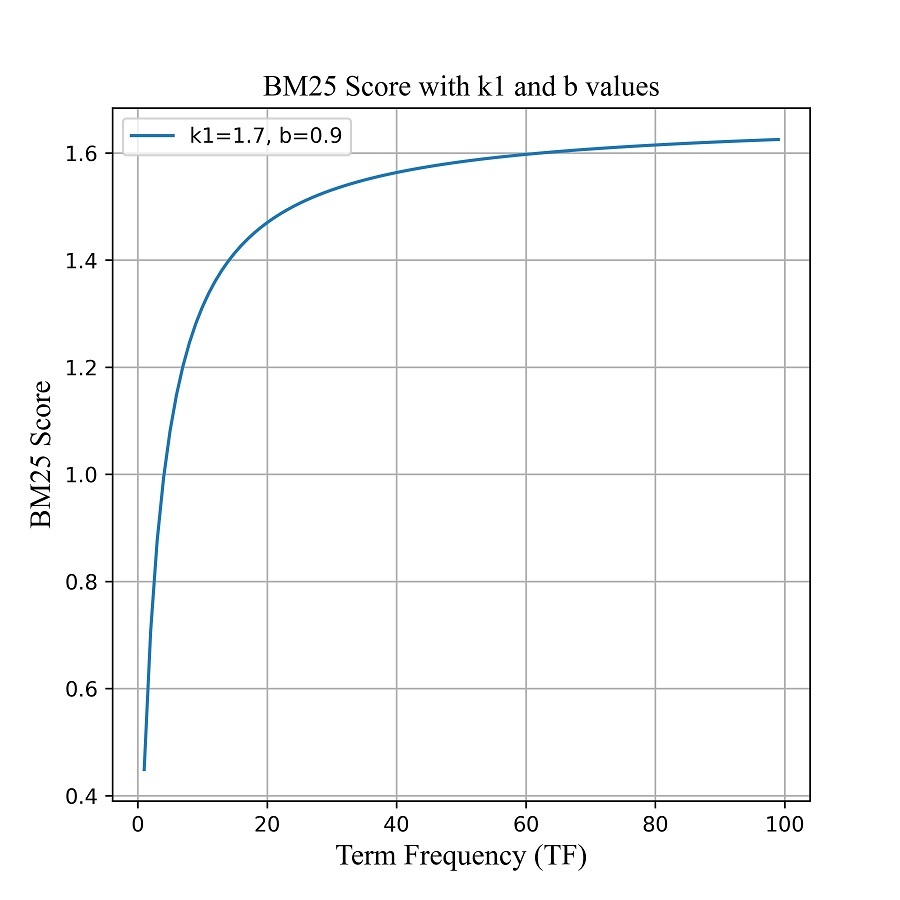
The study investigated the BM25 algorithm, methods for selecting parameters k1 and b, and their impact on the algorithm's effectiveness in detecting fake news. It was established that precise and detailed adjustment of these parameters is crucial in achieving optimal accuracy and data processing speed.
The results showed that the successful selection of BM25 parameters improves the model's accuracy by up to 14 % compared to standard term frequency – inverse document frequency (TF-IDF) calculations. These results were made possible by experimentally tuning different combinations of k1 and b parameters, in which the algorithm shows the best speed indicator or the most accurate estimate of the importance of a term in a document. Balanced values of k1 and b parameters were identified, leading to the algorithm's optimal speed and accuracy in assessing word importance considering the input data's peculiarities.
The balanced setting of the BM25 algorithm parameters explains the obtained results. They can be used for automated recognition and analysis of news and information on social media based on natural language processing. However, in practice, the effectiveness of the set of parameters depends on linguistic variations, content, and the theme within new input data sets
References
- Sharifani, K., Amini, M., Akbari, Y., Aghajanzadeh Godarzi, J. (2022). Operating Machine Learning across Natural Language Processing Techniques for Improvement of Fabricated News Model. International Journal of Science and Information System Research, 12 (9), 20–44. Available at: https://ssrn.com/abstract=4251017
- Yoo, J.-Y., Yang, D. (2015). Classification Scheme of Unstructured Text Document using TF-IDF and Naive Bayes Classifier. Advanced Science and Technology Letters. doi: https://doi.org/10.14257/astl.2015.111.50
- Fan, H., Qin, Y. (2018). Research on Text Classification Based on Improved TF-IDF Algorithm. Proceedings of the 2018 International Conference on Network, Communication, Computer Engineering (NCCE 2018). doi: https://doi.org/10.2991/ncce-18.2018.79
- Dai, W. (2018). Improvement and Implementation of Feature Weighting Algorithm TF-IDF in Text Classification. Proceedings of the 2018 International Conference on Network, Communication, Computer Engineering (NCCE 2018). doi: https://doi.org/10.2991/ncce-18.2018.94
- Izzah, I. K., Girsang, A. S. (2021). Modified TF-Assoc term weighting method for text classification on news dataset from twitter. IAENG International Journal of Computer Science, 48 (1), 142–151. Available at: http://www.iaeng.org/IJCS/issues_v48/issue_1/IJCS_48_1_15.pdf
- Wang, S., Jiang, L., Li, C. (2014). Adapting naive Bayes tree for text classification. Knowledge and Information Systems, 44 (1), 77–89. doi: https://doi.org/10.1007/s10115-014-0746-y
- Alammary, A. S. (2021). Arabic Questions Classification Using Modified TF-IDF. IEEE Access, 9, 95109–95122. doi: https://doi.org/10.1109/access.2021.3094115
- Dogan, T., Uysal, A. K. (2019). On Term Frequency Factor in Supervised Term Weighting Schemes for Text Classification. Arabian Journal for Science and Engineering, 44 (11), 9545–9560. doi: https://doi.org/10.1007/s13369-019-03920-9
- Ketola, T., Roelleke, T. (2023). Automatic and Analytical Field Weighting for Structured Document Retrieval. Advances in Information Retrieval, 489–503. doi: https://doi.org/10.1007/978-3-031-28244-7_31
- Liu, T., Xiong, Q., Zhang, S. (2023). When to Use Large Language Model: Upper Bound Analysis of BM25 Algorithms in Reading Comprehension Task. 2023 5th International Conference on Natural Language Processing (ICNLP). doi: https://doi.org/10.1109/icnlp58431.2023.00049
- Mishchenko, L., Klymenko, I. (2023). Method for detecting fake news based on natural language processing. The VI International Scientific and Practical Conference «Modern ways of solving the problems of science in the world», Warsaw, 375–378. Available at: https://eu-conf.com/ua/events/modern-ways-of-solving-the-problems-of-science-in-the-world/
- Introduction to Information Retrieval BM25, BM25F, and User Behavior Chris Manning and Pandu Nayak. Available at: https://web.stanford.edu/class/cs276/handouts/lecture12-bm25etc.pdf
- Lv, Y., Zhai, C. (2012). A Log-Logistic Model-Based Interpretation of TF Normalization of BM25. Advances in Information Retrieval, 244–255. doi: https://doi.org/10.1007/978-3-642-28997-2_21
- Vo, N., Lee, K. (2020). Where Are the Facts? Searching for Fact-checked Information to Alleviate the Spread of Fake News. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). doi: https://doi.org/10.18653/v1/2020.emnlp-main.621
- Seitz, R. (2020). UNDERSTANDING TF-IDF AND BM-25. Available at: https://kmwllc.com/index.php/2020/03/20/understanding-tf-idf-and-bm-25
- Liu, C., Sheng, Y., Wei, Z., Yang, Y.-Q. (2018). Research of Text Classification Based on Improved TF-IDF Algorithm. 2018 IEEE International Conference of Intelligent Robotic and Control Engineering (IRCE). doi: https://doi.org/10.1109/irce.2018.8492945
- Liu, T., Zhang, S., Xiong, Q. (2023). Separated Model for Stopping Point Prediction of Autoregressive Sequence. 2023 IEEE 12th Data Driven Control and Learning Systems Conference (DDCLS). doi: https://doi.org/10.1109/ddcls58216.2023.10167110
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2023 Liudmyla Mishchenko, Iryna Klymenko

This work is licensed under a Creative Commons Attribution 4.0 International License.
The consolidation and conditions for the transfer of copyright (identification of authorship) is carried out in the License Agreement. In particular, the authors reserve the right to the authorship of their manuscript and transfer the first publication of this work to the journal under the terms of the Creative Commons CC BY license. At the same time, they have the right to conclude on their own additional agreements concerning the non-exclusive distribution of the work in the form in which it was published by this journal, but provided that the link to the first publication of the article in this journal is preserved.
A license agreement is a document in which the author warrants that he/she owns all copyright for the work (manuscript, article, etc.).
The authors, signing the License Agreement with TECHNOLOGY CENTER PC, have all rights to the further use of their work, provided that they link to our edition in which the work was published.
According to the terms of the License Agreement, the Publisher TECHNOLOGY CENTER PC does not take away your copyrights and receives permission from the authors to use and dissemination of the publication through the world's scientific resources (own electronic resources, scientometric databases, repositories, libraries, etc.).
In the absence of a signed License Agreement or in the absence of this agreement of identifiers allowing to identify the identity of the author, the editors have no right to work with the manuscript.
It is important to remember that there is another type of agreement between authors and publishers – when copyright is transferred from the authors to the publisher. In this case, the authors lose ownership of their work and may not use it in any way.






