Розпізнавання фейкових новин на основі обробки природної мови за допомогою алгоритму BM25 зі збалансованими параметрами
DOI:
https://doi.org/10.15587/1729-4061.2023.293513Ключові слова:
BestMatch25, частота терміну – зворотна частота документа, обробка природної мови, фейкиАнотація
Обʼєктом дослідження є метод обробки природної мови (NLP) зі збалансованими параметрами алгоритму BestMatch25 (ВМ25) для розпізнавання та класифікації фейкових новин на основі обробки природної мови (NLP). Незадовільний рівень точності та швидкості наявних методів розпізнавання фейкових новин для неструктурованих вхідних даних вимагав розробки нового підходу для їх ефективного виявлення.
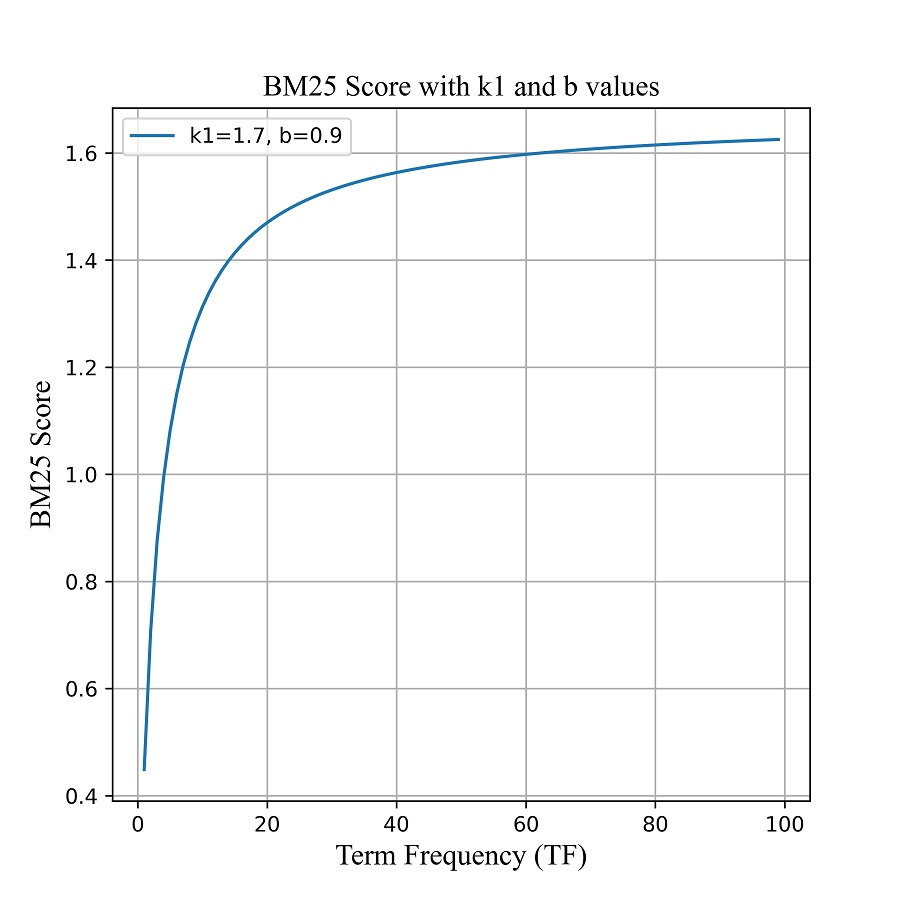
У ході роботи досліджено алгоритм BM25 та способи підбору параметрів k1 та b, а також їх впливу на ефективність алгоритму у виявленні фейкових новин. Встановлено, що точне та детальне коригування цих параметрів відіграє важливу роль у досягненні оптимальних показників точності та швидкості обробки вхідних даних.
Результати показали, що вдалий підбір параметрів ВМ25 дозволяє покращити точність моделі до 14 %, порівняно із стандартним обрахунком значення частота терміну – зворотна частота документа (TF-IDF). Ці результати стали можливими завдяки експериментальному налаштуванню різних комбінацій параметрів k1 і b, при яких алгоритм показує найкращий показник швидкості або найбільш точну оцінку важливості терміну в документі. Також вдалося підібрати такі збалансовані значення параметрів k1 і b, з якими результати роботи алгоритму набувають найоптимальніших показників швидкості та точності оцінки важливості слів із урахуванням особливостей вхідних даних.
Отримані результати пояснюються збалансованим налаштуванням параметрів алгоритму ВМ25. Вони можуть бути використані для автоматизованого розпізнавання й аналізу новин, інформації в соціальних мережах, базуючись на обробці природної мови. Проте, на практиці ефективність набору параметрів залежить від заміни мовних особливостей, лінгвістичного наповнення та тематики у нових вхідних даних
Посилання
- Sharifani, K., Amini, M., Akbari, Y., Aghajanzadeh Godarzi, J. (2022). Operating Machine Learning across Natural Language Processing Techniques for Improvement of Fabricated News Model. International Journal of Science and Information System Research, 12 (9), 20–44. Available at: https://ssrn.com/abstract=4251017
- Yoo, J.-Y., Yang, D. (2015). Classification Scheme of Unstructured Text Document using TF-IDF and Naive Bayes Classifier. Advanced Science and Technology Letters. doi: https://doi.org/10.14257/astl.2015.111.50
- Fan, H., Qin, Y. (2018). Research on Text Classification Based on Improved TF-IDF Algorithm. Proceedings of the 2018 International Conference on Network, Communication, Computer Engineering (NCCE 2018). doi: https://doi.org/10.2991/ncce-18.2018.79
- Dai, W. (2018). Improvement and Implementation of Feature Weighting Algorithm TF-IDF in Text Classification. Proceedings of the 2018 International Conference on Network, Communication, Computer Engineering (NCCE 2018). doi: https://doi.org/10.2991/ncce-18.2018.94
- Izzah, I. K., Girsang, A. S. (2021). Modified TF-Assoc term weighting method for text classification on news dataset from twitter. IAENG International Journal of Computer Science, 48 (1), 142–151. Available at: http://www.iaeng.org/IJCS/issues_v48/issue_1/IJCS_48_1_15.pdf
- Wang, S., Jiang, L., Li, C. (2014). Adapting naive Bayes tree for text classification. Knowledge and Information Systems, 44 (1), 77–89. doi: https://doi.org/10.1007/s10115-014-0746-y
- Alammary, A. S. (2021). Arabic Questions Classification Using Modified TF-IDF. IEEE Access, 9, 95109–95122. doi: https://doi.org/10.1109/access.2021.3094115
- Dogan, T., Uysal, A. K. (2019). On Term Frequency Factor in Supervised Term Weighting Schemes for Text Classification. Arabian Journal for Science and Engineering, 44 (11), 9545–9560. doi: https://doi.org/10.1007/s13369-019-03920-9
- Ketola, T., Roelleke, T. (2023). Automatic and Analytical Field Weighting for Structured Document Retrieval. Advances in Information Retrieval, 489–503. doi: https://doi.org/10.1007/978-3-031-28244-7_31
- Liu, T., Xiong, Q., Zhang, S. (2023). When to Use Large Language Model: Upper Bound Analysis of BM25 Algorithms in Reading Comprehension Task. 2023 5th International Conference on Natural Language Processing (ICNLP). doi: https://doi.org/10.1109/icnlp58431.2023.00049
- Mishchenko, L., Klymenko, I. (2023). Method for detecting fake news based on natural language processing. The VI International Scientific and Practical Conference «Modern ways of solving the problems of science in the world», Warsaw, 375–378. Available at: https://eu-conf.com/ua/events/modern-ways-of-solving-the-problems-of-science-in-the-world/
- Introduction to Information Retrieval BM25, BM25F, and User Behavior Chris Manning and Pandu Nayak. Available at: https://web.stanford.edu/class/cs276/handouts/lecture12-bm25etc.pdf
- Lv, Y., Zhai, C. (2012). A Log-Logistic Model-Based Interpretation of TF Normalization of BM25. Advances in Information Retrieval, 244–255. doi: https://doi.org/10.1007/978-3-642-28997-2_21
- Vo, N., Lee, K. (2020). Where Are the Facts? Searching for Fact-checked Information to Alleviate the Spread of Fake News. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). doi: https://doi.org/10.18653/v1/2020.emnlp-main.621
- Seitz, R. (2020). UNDERSTANDING TF-IDF AND BM-25. Available at: https://kmwllc.com/index.php/2020/03/20/understanding-tf-idf-and-bm-25
- Liu, C., Sheng, Y., Wei, Z., Yang, Y.-Q. (2018). Research of Text Classification Based on Improved TF-IDF Algorithm. 2018 IEEE International Conference of Intelligent Robotic and Control Engineering (IRCE). doi: https://doi.org/10.1109/irce.2018.8492945
- Liu, T., Zhang, S., Xiong, Q. (2023). Separated Model for Stopping Point Prediction of Autoregressive Sequence. 2023 IEEE 12th Data Driven Control and Learning Systems Conference (DDCLS). doi: https://doi.org/10.1109/ddcls58216.2023.10167110
##submission.downloads##
Опубліковано
Як цитувати
Номер
Розділ
Ліцензія
Авторське право (c) 2023 Liudmyla Mishchenko, Iryna Klymenko

Ця робота ліцензується відповідно до Creative Commons Attribution 4.0 International License.
Закріплення та умови передачі авторських прав (ідентифікація авторства) здійснюється у Ліцензійному договорі. Зокрема, автори залишають за собою право на авторство свого рукопису та передають журналу право першої публікації цієї роботи на умовах ліцензії Creative Commons CC BY. При цьому вони мають право укладати самостійно додаткові угоди, що стосуються неексклюзивного поширення роботи у тому вигляді, в якому вона була опублікована цим журналом, але за умови збереження посилання на першу публікацію статті в цьому журналі.
Ліцензійний договір – це документ, в якому автор гарантує, що володіє усіма авторськими правами на твір (рукопис, статтю, тощо).
Автори, підписуючи Ліцензійний договір з ПП «ТЕХНОЛОГІЧНИЙ ЦЕНТР», мають усі права на подальше використання свого твору за умови посилання на наше видання, в якому твір опублікований. Відповідно до умов Ліцензійного договору, Видавець ПП «ТЕХНОЛОГІЧНИЙ ЦЕНТР» не забирає ваші авторські права та отримує від авторів дозвіл на використання та розповсюдження публікації через світові наукові ресурси (власні електронні ресурси, наукометричні бази даних, репозитарії, бібліотеки тощо).
За відсутності підписаного Ліцензійного договору або за відсутністю вказаних в цьому договорі ідентифікаторів, що дають змогу ідентифікувати особу автора, редакція не має права працювати з рукописом.
Важливо пам’ятати, що існує і інший тип угоди між авторами та видавцями – коли авторські права передаються від авторів до видавця. В такому разі автори втрачають права власності на свій твір та не можуть його використовувати в будь-який спосіб.







