Розробка нейронної мережі із шаром навчаємих функцій активації для другого ступеня ансамбльового класифікатора із стекінгом
DOI:
https://doi.org/10.15587/1729-4061.2024.311778Ключові слова:
багатошаровий персептрон, нейронна мережа, ансамблевий класифікатор, вагові коефіцієнти, класифікація об'єктів на зображенняхАнотація
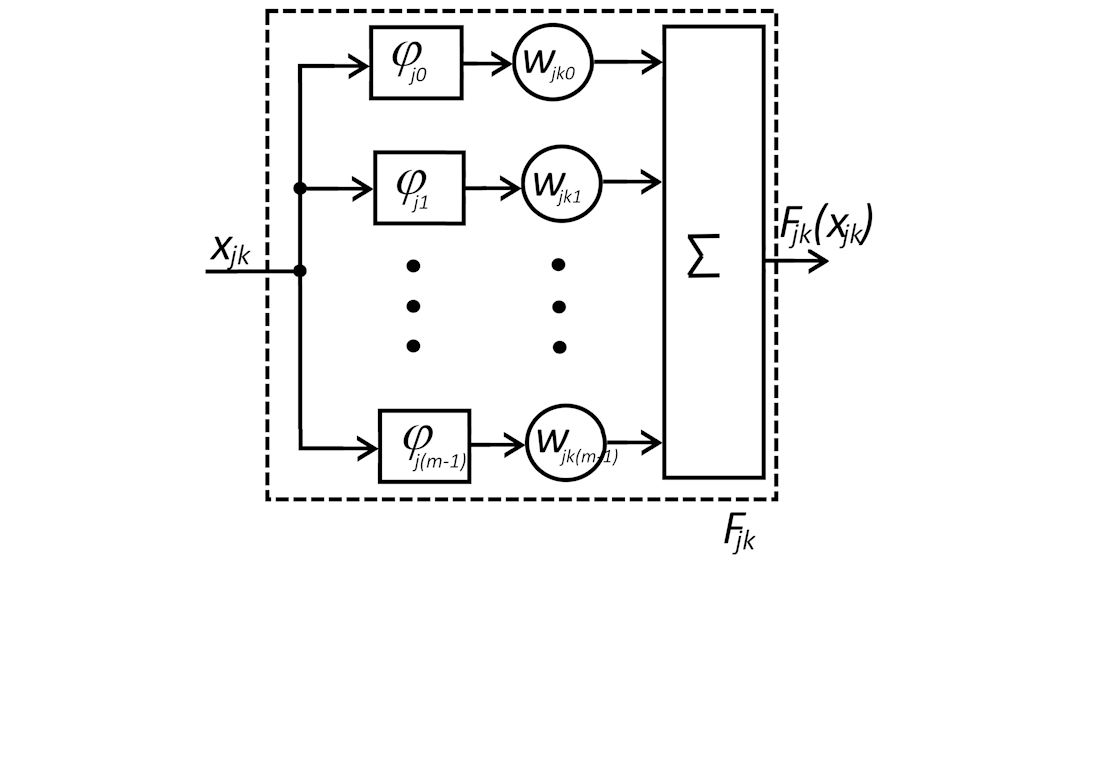
Одним із перспективних напрямів щодо підвищення якості розпізнавання об'єктів на зображеннях та розпаралелювання обчислень є використання ансамблевих класифікаторів зі стекінгом. Нейронна мережа на другому ступені дозволяє досягти результуючої якості класифікації, істотно більшої, ніж кожна з мереж першого ступеня окремо. Якість класифікації всього ансамблевого класифікатора зі стекінгом залежить від ефективності нейронних мереж на першому ступені, їх кількості та якості класифікації нейронної мережі другого ступеня. У статті запропоновано архітектуру нейронної мережі для другого ступеня ансамблевого класифікатора, що поєднує в собі апроксимуючі властивості традиційних нейронів і функцій активації, що навчаються. Для реалізації функцій активації, що навчаються, були обрані гауссівські радіальні базисні функції (RBF), які підсумовуються з вагами, що навчаються. Проведені експериментальні дослідження показали, що при роботі з набором даних CIFAR-10 найкращі результати виходять при використанні шести RBF. Порівняння з використанням на другому ступені багатошарового персептрону (MLP) показало зменшення помилок класифікації на 0,45 %–1,9 % залежно від кількості нейронних мереж на першому ступені. При цьому запропонована архітектура нейронної мережі для другого ступеня мала в 1,69–3,7 разів менше коефіцієнтів, що навчаються, ніж MLP. Цей результат пояснюється тим, що використання вихідного шару зі звичайними нейронами дозволило не вводити в архітектуру багато функцій активації, що навчаються, для кожного вихідного сигналу першого ступеня, а обмежитися тільки однією. Оскільки результати були отримані на універсальному наборі даних CIFAR-10, аналогічний ефект можна отримати на великій кількості аналогічних практичних наборів даних
Посилання
- Rokach, L. (2019). Ensemble Learning. Series in Machine Perception and Artificial Intelligence. https://doi.org/10.1142/11325
- Galchonkov, O., Babych, M., Zasidko, A., Poberezhnyi, S. (2022). Using a neural network in the second stage of the ensemble classifier to improve the quality of classification of objects in images. Eastern-European Journal of Enterprise Technologies, 3 (9 (117)), 15–21. https://doi.org/10.15587/1729-4061.2022.258187
- Liu, Z., Wang, Y., Vaidya, S., Ruehle, F., Halverson, J., Soljačić, M. et al. (2024). KAN: Kolmogorov-Arnold Networks. arXiv. https://doi.org/10.48550/arXiv.2404.19756
- Hornik, K., Stinchcombe, M., White, H. (1989). Multilayer feedforward networks are universal approximators. Neural Networks, 2 (5), 359–366. https://doi.org/10.1016/0893-6080(89)90020-8
- Braun, J., Griebel, M. (2009). On a Constructive Proof of Kolmogorov’s Superposition Theorem. Constructive Approximation, 30 (3), 653–675. https://doi.org/10.1007/s00365-009-9054-2
- Hao, H., Zhang, X., Li, B., Zhou, A. (2024). A First Look at Kolmogorov-Arnold Networks in Surrogate-assisted Evolutionary Algorithms. arXiv. https://doi.org/10.48550/arXiv.2405.16494
- Drokin, I. (2024). Kolmogorov-Arnold Convolutions: Design Principles and Empirical Studies. arXiv. https://doi.org/10.48550/arXiv.2407.01092
- Tolstikhin, I., Houlsby, N., Kolesnikov, A., Beyer, L., Zhai, X., Unterthiner, T. et al. (2021). MLP-Mixer: An all-MLP Architecture for Vision. arXiv. https://doi.org/10.48550/arXiv.2105.01601
- Cheon, M. (2024). Demonstrating the efficacy of Kolmogorov-Arnold Networks in vision tasks. arXiv. https://doi.org/10.48550/arXiv.2406.14916
- Zhang, F., Zhang, X. (2024). GraphKAN: Enhancing Feature Extraction with Graph Kolmogorov Arnold Networks. arXiv. https://doi.org/10.48550/arXiv.2406.13597
- Xu, J., Chen, Z., Li, J., Yang, S., Wang, W., Hu, X. et al. (2024). FourierKAN-GCF: Fourier Kolmogorov-Arnold Network – An Effective and Efficient Feature Transformation for Graph Collaborative Filtering. arXiv. https://doi.org/10.48550/arXiv.2406.01034
- Vaca-Rubio, C. J., Blanco, L., Pereira, R., Caus, M. (2024). Kolmogorov-Arnold Networks (KANs) for Time Series Analysis. arXiv. https://doi.org/10.48550/arXiv.2405.08790
- Inzirillo, H., Genet, R. (2024). SigKAN: Signature-Weighted Kolmogorov-Arnold Networks for Time Series. arXiv. https://doi.org/10.48550/arXiv.2406.17890
- Ismayilova, A., Ismayilov, M. (2023). On the universal approximation property of radial basis function neural networks. Annals of Mathematics and Artificial Intelligence, 92 (3), 691–701. https://doi.org/10.1007/s10472-023-09901-x
- Li, Z. (2024). Kolmogorov-Arnold Networks are Radial Basis Function Networks. arXiv. https://doi.org/10.48550/arXiv.2405.06721
- Bao, X., Liu, G., Yang, G., Wang, S. (2020). Multi-instance Multi-label Text Categorization Algorithm Based on Multi-quadric Function Radial Basis Network Model. 2020 3rd International Conference on Artificial Intelligence and Big Data (ICAIBD), 1998, 133–136. https://doi.org/10.1109/icaibd49809.2020.9137478
- Basha Kattubadi, I., Murthy Garimella, R. (2020). Novel Deep Learning Architectures: Feature Extractor and Radial Basis Function Neural Network. 2020 International Conference on Computational Performance Evaluation (ComPE), 024–027. https://doi.org/10.1109/compe49325.2020.9200146
- He, Z.-R., Lin, Y.-T., Lee, S.-J., Wu, C.-H. (2018). A RBF Network Approach for Function Approximation. 2018 IEEE International Conference on Information and Automation (ICIA), 9, 105–109. https://doi.org/10.1109/icinfa.2018.8812435
- Panda, S., Panda, G. (2022). On the Development and Performance Evaluation of Improved Radial Basis Function Neural Networks. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 52 (6), 3873–3884. https://doi.org/10.1109/tsmc.2021.3076747
- Wu, C., Kong, X., Yang, Z. (2018). An Online Self-Adaption Learning Algorithm for Hyper Basis Function Neural Network. 2018 2nd IEEE Advanced Information Management,Communicates,Electronic and Automation Control Conference (IMCEC), 9, 215–220. https://doi.org/10.1109/imcec.2018.8469684
- Seydi, S. T. (2024). Exploring the Potential of Polynomial Basis Functions in Kolmogorov-Arnold Networks: A Comparative Study of Different Groups of Polynomials. arXiv. https://doi.org/10.48550/arXiv.2406.02583
- Seydi, S. T. (2024). Unveiling the Power of Wavelets: A Wavelet-based Kolmogorov-Arnold Network for Hyperspectral Image Classification. arXiv. https://doi.org/10.48550/arXiv.2406.07869
- Qiu, Q., Zhu, T., Gong, H., Chen, L., Ning, H. (2024). ReLU-KAN: New Kolmogorov-Arnold Networks that Only Need Matrix Addition, Dot Multiplication, and ReLU. arXiv. https://doi.org/10.48550/arXiv.2406.02075
- Krizhevsky, A. The CIFAR-10 dataset. Available at: https://www.cs.toronto.edu/~kriz/cifar.html
- Hassani, A., Walton, S., Shah, N., Abuduweili, A., Li, J., Shi, H. (2021). Escaping the Big Data Paradigm with Compact Transformers. arXiv. https://doi.org/10.48550/arXiv.2104.05704
- Guo, M.-H., Liu, Z.-N., Mu, T.-J., Hu, S.-M. (2022). Beyond Self-Attention: External Attention Using Two Linear Layers for Visual Tasks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1–13. https://doi.org/10.1109/tpami.2022.3211006
- Lee-Thorp, J., Ainslie, J., Eckstein, I., Ontanon, S. (2022). FNet: Mixing Tokens with Fourier Transforms. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. https://doi.org/10.18653/v1/2022.naacl-main.319
- Liu, H., Dai, Z., So, D. R., Le, Q. V. (2021). Pay Attention to MLPs. arXiv. https://doi.org/10.48550/arXiv.2105.08050
- Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z. et al. (2021). Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. 2021 IEEE/CVF International Conference on Computer Vision (ICCV). https://doi.org/10.1109/iccv48922.2021.00986
- Brownlee, J. (2021). Weight Initialization for Deep Learning Neural Networks. Available at: https://machinelearningmastery.com/weight-initialization-for-deep-learning-neural-networks/
- Code examples. Computer vision. Keras. Available at: https://keras.io/examples/vision/
##submission.downloads##
Опубліковано
Як цитувати
Номер
Розділ
Ліцензія
Авторське право (c) 2024 Oleg Galchonkov, Oleksii Baranov, Svetlana Antoshchuk, Oleh Maslov, Mykola Babych

Ця робота ліцензується відповідно до Creative Commons Attribution 4.0 International License.
Закріплення та умови передачі авторських прав (ідентифікація авторства) здійснюється у Ліцензійному договорі. Зокрема, автори залишають за собою право на авторство свого рукопису та передають журналу право першої публікації цієї роботи на умовах ліцензії Creative Commons CC BY. При цьому вони мають право укладати самостійно додаткові угоди, що стосуються неексклюзивного поширення роботи у тому вигляді, в якому вона була опублікована цим журналом, але за умови збереження посилання на першу публікацію статті в цьому журналі.
Ліцензійний договір – це документ, в якому автор гарантує, що володіє усіма авторськими правами на твір (рукопис, статтю, тощо).
Автори, підписуючи Ліцензійний договір з ПП «ТЕХНОЛОГІЧНИЙ ЦЕНТР», мають усі права на подальше використання свого твору за умови посилання на наше видання, в якому твір опублікований. Відповідно до умов Ліцензійного договору, Видавець ПП «ТЕХНОЛОГІЧНИЙ ЦЕНТР» не забирає ваші авторські права та отримує від авторів дозвіл на використання та розповсюдження публікації через світові наукові ресурси (власні електронні ресурси, наукометричні бази даних, репозитарії, бібліотеки тощо).
За відсутності підписаного Ліцензійного договору або за відсутністю вказаних в цьому договорі ідентифікаторів, що дають змогу ідентифікувати особу автора, редакція не має права працювати з рукописом.
Важливо пам’ятати, що існує і інший тип угоди між авторами та видавцями – коли авторські права передаються від авторів до видавця. В такому разі автори втрачають права власності на свій твір та не можуть його використовувати в будь-який спосіб.







