Development of a TRIE-BERT pipeline for automatic spacing and low resource language classification in Batak Toba and Angkola scriptio continua texts
DOI:
https://doi.org/10.15587/1729-4061.2026.352682Keywords:
trie, BERT, scriptio continua, low resource, Batak languageAbstract
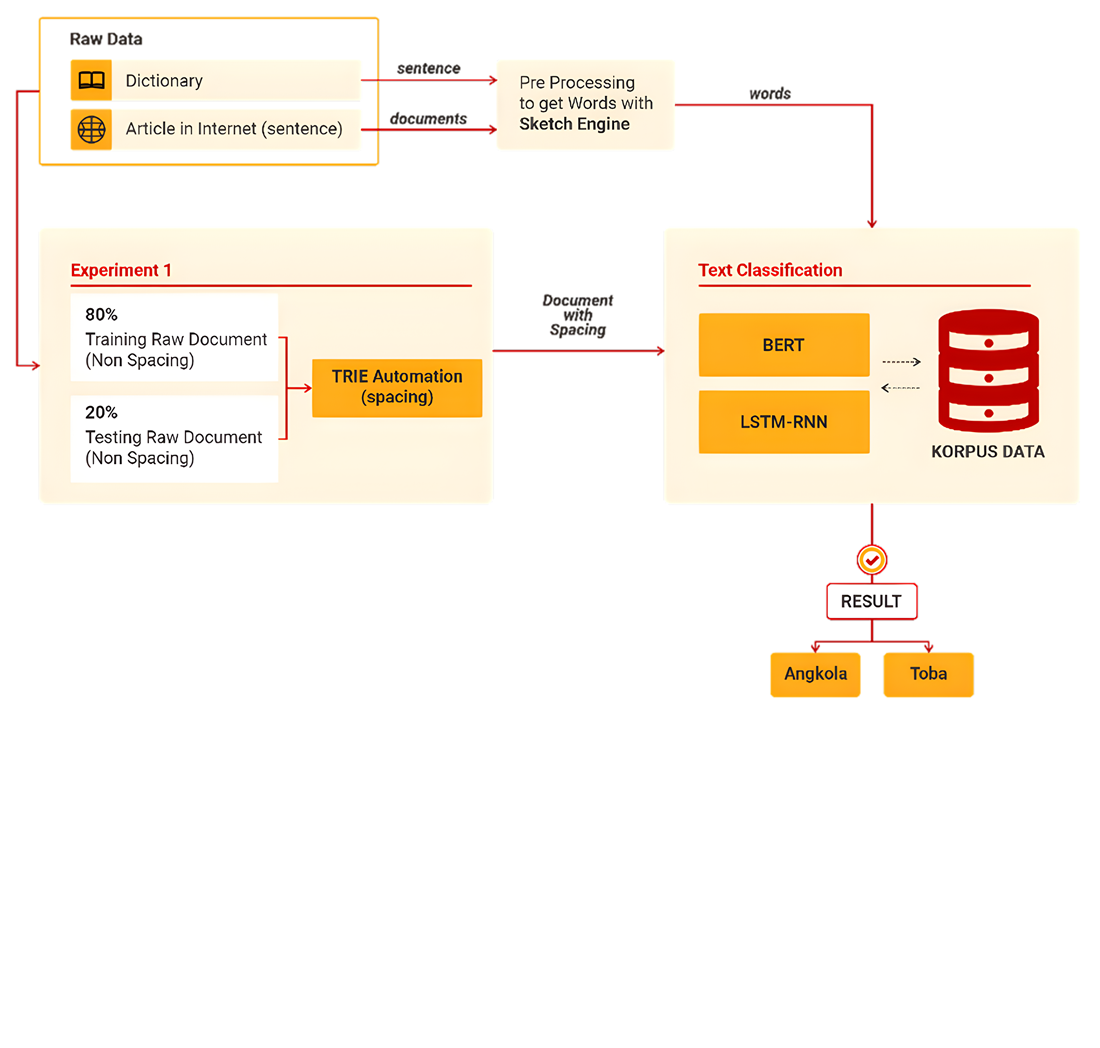
Batak Toba and Batak Angkola texts written in scriptio continua form without spaces are the object of this study. The work solves a low-resource variety classification problem where the two varieties are similar and missing word boundaries introduce segmentation noise. A hybrid TRIE-BERT pipeline was developed in which trie automation performs deterministic spacing, the restored spacing is fixed, and the spaced text becomes a stable input interface for a Bidirectional Encoder Representations from Transformers (BERT) classifier. Experiments used a Batak lexicon of 19,070 word entries and 8,000 sentences, 4,000 per variety, evaluated under four data schemes from 1,000 to 8,000 sentences and five epoch settings from 5 to 50 with an 80:20 split. After lexicon recalibration of about 70 sentences, spacing reached 98 percent accuracy. The best setting at 8,000 sentences and 50 epochs achieved 0.85 test accuracy with 0.343 training loss, 0.85 ROC AUC, and 0.85 F1-score, exceeding a long short-term memory recurrent neural network baseline (LSTM-RNN) at 0.80 accuracy, 0.397 loss, 0.803 ROC AUC, and 0.80 F1-score. Class-wise evaluation yielded precision 0.81 and recall 0.92 for Toba and precision 0.90 and recall 0.79 for Angkola, explaining averaged precision 0.86 and recall 0.85. The improvement is associated with the combined use of deterministic trie-based boundary recovery and contextual BERT classification, where spacing is fixed before classification to reduce token ambiguity and stabilize the input structure. The results support Batak text processing pipelines that require automatic spacing and variety detection under limited labels, provided lexicon coverage is maintained and spelling variation is controlled
References
- Otter, D. W., Medina, J. R., Kalita, J. K. (2021). A Survey of the Usages of Deep Learning for Natural Language Processing. IEEE Transactions on Neural Networks and Learning Systems, 32 (2), 604–624. https://doi.org/10.1109/tnnls.2020.2979670
- Min, B., Ross, H., Sulem, E., Veyseh, A. P. B., Nguyen, T. H., Sainz, O., Agirre, E. et al. (2023). Recent Advances in Natural Language Processing via Large Pre-trained Language Models: A Survey. ACM Computing Surveys, 56 (2), 1–40. https://doi.org/10.1145/3605943
- Qiu, X., Sun, T., Xu, Y., Shao, Y., Dai, N., Huang, X. (2020). Pre-trained models for natural language processing: A survey. Science China Technological Sciences, 63 (10), 1872–1897. https://doi.org/10.1007/s11431-020-1647-3
- Ranathunga, S., Lee, E.-S. A., Prifti Skenduli, M., Shekhar, R., Alam, M., Kaur, R. (2023). Neural Machine Translation for Low-resource Languages: A Survey. ACM Computing Surveys, 55 (11), 1–37. https://doi.org/10.1145/3567592
- Zampieri, M., Nakov, P., Scherrer, Y. (2020). Natural language processing for similar languages, varieties, and dialects: A survey. Natural Language Engineering, 26 (6), 595–612. https://doi.org/10.1017/s1351324920000492
- Haq, I., Qiu, W., Guo, J., Tang, P. (2023). Correction of whitespace and word segmentation in noisy Pashto text using CRF. Speech Communication, 153, 102970. https://doi.org/10.1016/j.specom.2023.102970
- Widiarti, A. R., Pulungan, R. (2020). A method for solving scriptio continua in Javanese manuscript transliteration. Heliyon, 6 (4), e03827. https://doi.org/10.1016/j.heliyon.2020.e03827
- Liu, C., Peng, Y., Chng, E. S. (2025). Zero-shot Context Biasing with Trie-based Decoding using Synthetic Multi-Pronunciation. 2025 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), 873–878. https://doi.org/10.1109/apsipaasc65261.2025.11249064
- Alsuwaylimi, A. A. (2024). Arabic dialect identification in social media: A hybrid model with transformer models and BiLSTM. Heliyon, 10 (17), e36280. https://doi.org/10.1016/j.heliyon.2024.e36280
- Chabane, M., Harrag, F., Shaalan, K. (2025). Advancing low-resource dialect identification: A hybrid cross-lingual model leveraging CAMeLBERT and FastText for Algerian Arabic. Expert Systems with Applications, 284, 127816. https://doi.org/10.1016/j.eswa.2025.127816
- El Mekki, A., El Mahdaouy, A., Berrada, I., Khoumsi, A. (2022). AdaSL: An Unsupervised Domain Adaptation framework for Arabic multi-dialectal Sequence Labeling. Information Processing & Management, 59 (4), 102964. https://doi.org/10.1016/j.ipm.2022.102964
- Saleh, H., AlMohimeed, A., Hassan, R., Ibrahim, M. M., Alsamhi, S. H., Hassan, M. R., Mostafa, S. (2025). Advancing arabic dialect detection with hybrid stacked transformer models. Frontiers in Human Neuroscience, 19. https://doi.org/10.3389/fnhum.2025.1498297
- Hwang, T., Jung, S., Roh, Y. (2021). Korean automatic spacing using pretrained transformer encoder and analysis. ETRI Journal, 43 (6), 1049–1057. https://doi.org/10.4218/etrij.2020-0092
- Ryu, J., Lim, S., Kwon, O., Na, S. (2024). Transformer‐based reranking for improving Korean morphological analysis systems. ETRI Journal, 46 (1), 137–153. https://doi.org/10.4218/etrij.2023-0364
- Liu, Z., Prud’hommeaux, E. (2022). Data-driven Model Generalizability in Crosslinguistic Low-resource Morphological Segmentation. Transactions of the Association for Computational Linguistics, 10, 393–413. https://doi.org/10.1162/tacl_a_00467
- Algayres, R., Ricoul, T., Karadayi, J., Laurençon, H., Zaiem, S., Mohamed, A. et al. (2022). DP-Parse: Finding Word Boundaries from Raw Speech with an Instance Lexicon. Transactions of the Association for Computational Linguistics, 10, 1051–1065. https://doi.org/10.1162/tacl_a_00505
- Sandeep, S., Sanjith, S., Sudarsan, B. (2025). Word segmentation of ancient Tamil text extracted from inscriptions. Npj Heritage Science, 13 (1). https://doi.org/10.1038/s40494-025-01612-2
- Muchtar, M. A., Salim Sitompul, O., Lydia, M. S., Efendi, S. (2022). Implementation of Trie Automation Algorithm for Problem Solving Scriptio Continua. 2021 International Seminar on Machine Learning, Optimization, and Data Science (ISMODE), 28–32. https://doi.org/10.1109/ismode53584.2022.9743133
- Purba, M. A. (2019). Bibel Batak Toba-Indonesia. Available at: https://bibeltobaindonesia.wordpress.com/
- Kamus bahasa Batak Toba-Indonesia. Available at: https://digilib.usu.ac.id/en/detail.php?ib=16214&i=
- Lubis, S., Lubis, S., Mariahati, M., Naibaho, J. (1995) Kamus bahasa Indonesia - Angkola. Pusat Pembinaan dan Pengembangan Bahasa, Jakarta. Available at: https://repositori.kemendikdasmen.go.id/26811/
- Ortakci, Y., Borhan, B. (2025). Optimizing SBERT for long text clustering: two novel approaches with empirical insights. The Journal of Supercomputing, 81 (8). https://doi.org/10.1007/s11227-025-07414-4
- RKaban, R., Sihombing, P., Efendi, S., Lydia, M. S. (2025). Enhancing retrieval performance in social media with corpus-based query expansion using bidirectional encoder representations from transformers. Eastern-European Journal of Enterprise Technologies, 5 (2 (137)), 70–83. https://doi.org/10.15587/1729-4061.2025.340258
- Mswahili, M. E., Hwang, J., Rajapakse, J. C., Jo, K., Jeong, Y.-S. (2025). Positional embeddings and zero-shot learning using BERT for molecular-property prediction. Journal of Cheminformatics, 17 (1). https://doi.org/10.1186/s13321-025-00959-9
- Anggrainingsih, R., Hassan, G. M., Datta, A. (2025). Evaluating BERT-based language models for detecting misinformation. Neural Computing and Applications, 37(16), 9937–9968. https://doi.org/10.1007/s00521-025-11101-z
- Shi, J., He, Q., Wang, Z. (2021). An LSTM-based severity evaluation method for intermittent open faults of an electrical connector under a shock test. Measurement, 173, 108653. https://doi.org/10.1016/j.measurement.2020.108653
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2026 Muhammad Anggia Muchtar, Opim Salim Sitompul, Maya Silvi Lydia, Syahril Efendi

This work is licensed under a Creative Commons Attribution 4.0 International License.
The consolidation and conditions for the transfer of copyright (identification of authorship) is carried out in the License Agreement. In particular, the authors reserve the right to the authorship of their manuscript and transfer the first publication of this work to the journal under the terms of the Creative Commons CC BY license. At the same time, they have the right to conclude on their own additional agreements concerning the non-exclusive distribution of the work in the form in which it was published by this journal, but provided that the link to the first publication of the article in this journal is preserved.
A license agreement is a document in which the author warrants that he/she owns all copyright for the work (manuscript, article, etc.).
The authors, signing the License Agreement with TECHNOLOGY CENTER PC, have all rights to the further use of their work, provided that they link to our edition in which the work was published.
According to the terms of the License Agreement, the Publisher TECHNOLOGY CENTER PC does not take away your copyrights and receives permission from the authors to use and dissemination of the publication through the world's scientific resources (own electronic resources, scientometric databases, repositories, libraries, etc.).
In the absence of a signed License Agreement or in the absence of this agreement of identifiers allowing to identify the identity of the author, the editors have no right to work with the manuscript.
It is important to remember that there is another type of agreement between authors and publishers – when copyright is transferred from the authors to the publisher. In this case, the authors lose ownership of their work and may not use it in any way.






