Development of a fake news detection tool for Vietnamese based on deep learning techniques
DOI:
https://doi.org/10.15587/1729-4061.2022.265317Keywords:
fake news detection, natural language processing, deep learning, CNN, RNNAbstract
With the development of the Internet, social networks and different communication channels, people can get information quickly and easily. However, in addition to real and useful news, we also receive false and unreal information. The problem of fake news has become a difficult and unresolved issue. For languages with few users, such as Vietnamese, the research on fake news detection is still very limited and has not received much attention.
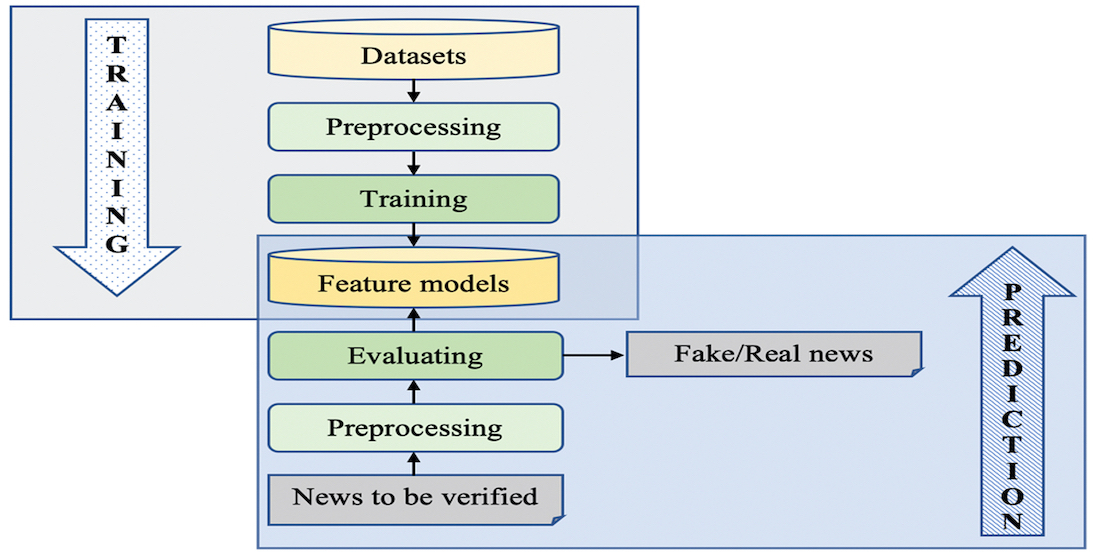
In this paper, we present research results on building a tool to support fake news detection for Vietnamese. Our idea is to apply text classification techniques to fake news detection. We have built a database of 4 groups of 2 topics about politics (fake news and real news) and about Covid-19 (fake news and real news). Then use deep learning techniques CNN (Convolutional Neural Network) and RNN (Recurrent Neural Network) to create the corresponding models. When there is new news that needs to be verified, we just need to apply the classification to see which of the four groups they label into to decide whether it is fake news or not. The tool was able to detect fake news quickly and easily with a correct rate of about 85 %. This result will be improved when getting a larger training data set and adjusting the parameters for the machine learning model. These results make an important contribution to the research on detecting fake news for Vietnamese and can be applied to other languages. In the future, besides using classification techniques (based on content analysis), we can combine many other methods such as checking the source, verifying the author's information, checking the distribution process to improve the quality of fake news detection.
Supporting Agency
- This research was funded by the Ministry of Education and Training (Vietnam) through the project code B2022-DNA-17.
References
- Watson, A. (2022). Trust in media worldwide 2021. Statista. Available at: https://www.statista.com/statistics/683336/media-trust-worldwide/
- Fallis, D. (2015). What Is Disinformation? Library Trends, 63 (3), 401–426. doi: https://doi.org/10.1353/lib.2015.0014
- Wardle, C., Derakhshan, H. (2017). Information disorder: Toward an interdisciplinary framework for research and policy making. Council of Europe, 109.
- Nguyen, D. Q., Tuan Nguyen, A. (2020). PhoBERT: Pre-trained language models for Vietnamese. Findings of the Association for Computational Linguistics: EMNLP 2020. doi: https://doi.org/10.18653/v1/2020.findings-emnlp.92
- Le, D.-T., Vu, X.-S., To, N.-D., Nguyen, H.-Q., Nguyen, T.-T., Le, L. et. al. (2020). ReINTEL: A multimodal data challenge for responsible information identification on social network sites. arXiv. doi: https://doi.org/10.48550/arXiv.2012.08895
- Molina, M. D., Sundar, S. S., Le, T., Lee, D. (2019). “Fake News” Is Not Simply False Information: A Concept Explication and Taxonomy of Online Content. American Behavioral Scientist, 65 (2), 180–212. doi: https://doi.org/10.1177/0002764219878224
- Miller, T., Howe, P., Sonenberg, L. (2017). Explainable AI: Beware of inmates running the asylum or: How I learnt to stop worrying and love the social and behavioural sciences. arXiv. doi: https://doi.org/10.48550/arXiv.1712.00547
- Chadwick, A., Stanyer, J. (2021). Deception as a Bridging Concept in the Study of Disinformation, Misinformation, and Misperceptions: Toward a Holistic Framework. Communication Theory, 32 (1), 1–24. doi: https://doi.org/10.1093/ct/qtab019
- Zhou, X., Wu, J., Zafarani, R. (2020). SAFE: Similarity-Aware Multi-modal Fake News Detection. Lecture Notes in Computer Science, 354–367. doi: https://doi.org/10.1007/978-3-030-47436-2_27
- Zhou, X., Zafarani, R. (2019). Network-based Fake News Detection. ACM SIGKDD Explorations Newsletter, 21 (2), 48–60. doi: https://doi.org/10.1145/3373464.3373473
- Kollias, D., Zafeiriou, S. (2021). Exploiting Multi-CNN Features in CNN-RNN Based Dimensional Emotion Recognition on the OMG in-the-Wild Dataset. IEEE Transactions on Affective Computing, 12 (3), 595–606. doi: https://doi.org/10.1109/taffc.2020.3014171
- Elhadad, M. K., Li, K. F., Gebali, F. (2019). A Novel Approach for Selecting Hybrid Features from Online News Textual Metadata for Fake News Detection. Lecture Notes in Networks and Systems, 914–925. doi: https://doi.org/10.1007/978-3-030-33509-0_86
- Keeling, R., Chhatwal, R., Huber-Fliflet, N., Zhang, J., Wei, F., Zhao, H. et. al. (2019). Empirical Comparisons of CNN with Other Learning Algorithms for Text Classification in Legal Document Review. 2019 IEEE International Conference on Big Data (Big Data). doi: https://doi.org/10.1109/bigdata47090.2019.9006248
- Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). doi: https://doi.org/10.3115/v1/d14-1181
- Yu, Y., Si, X., Hu, C., Zhang, J. (2019). A Review of Recurrent Neural Networks: LSTM Cells and Network Architectures. Neural Computation, 31 (7), 1235–1270. doi: https://doi.org/10.1162/neco_a_01199
- Ketkar, N. (2017). Introduction to Keras. Deep Learning with Python, 97–111. doi: https://doi.org/10.1007/978-1-4842-2766-4_7
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2022 Trung Hung Vo, Thi Le Thuyen Phan, Khanh Chi Ninh

This work is licensed under a Creative Commons Attribution 4.0 International License.
The consolidation and conditions for the transfer of copyright (identification of authorship) is carried out in the License Agreement. In particular, the authors reserve the right to the authorship of their manuscript and transfer the first publication of this work to the journal under the terms of the Creative Commons CC BY license. At the same time, they have the right to conclude on their own additional agreements concerning the non-exclusive distribution of the work in the form in which it was published by this journal, but provided that the link to the first publication of the article in this journal is preserved.
A license agreement is a document in which the author warrants that he/she owns all copyright for the work (manuscript, article, etc.).
The authors, signing the License Agreement with TECHNOLOGY CENTER PC, have all rights to the further use of their work, provided that they link to our edition in which the work was published.
According to the terms of the License Agreement, the Publisher TECHNOLOGY CENTER PC does not take away your copyrights and receives permission from the authors to use and dissemination of the publication through the world's scientific resources (own electronic resources, scientometric databases, repositories, libraries, etc.).
In the absence of a signed License Agreement or in the absence of this agreement of identifiers allowing to identify the identity of the author, the editors have no right to work with the manuscript.
It is important to remember that there is another type of agreement between authors and publishers – when copyright is transferred from the authors to the publisher. In this case, the authors lose ownership of their work and may not use it in any way.





