Покращення розпізнавання дій на основі скелета за допомогою гібридних реальних та згенерованих наборами даних
DOI:
https://doi.org/10.15587/1729-4061.2024.317092Ключові слова:
розпізнавання дій, згорточна нейронна мережа, генеративні змагальні мережі, LSTMАнотація
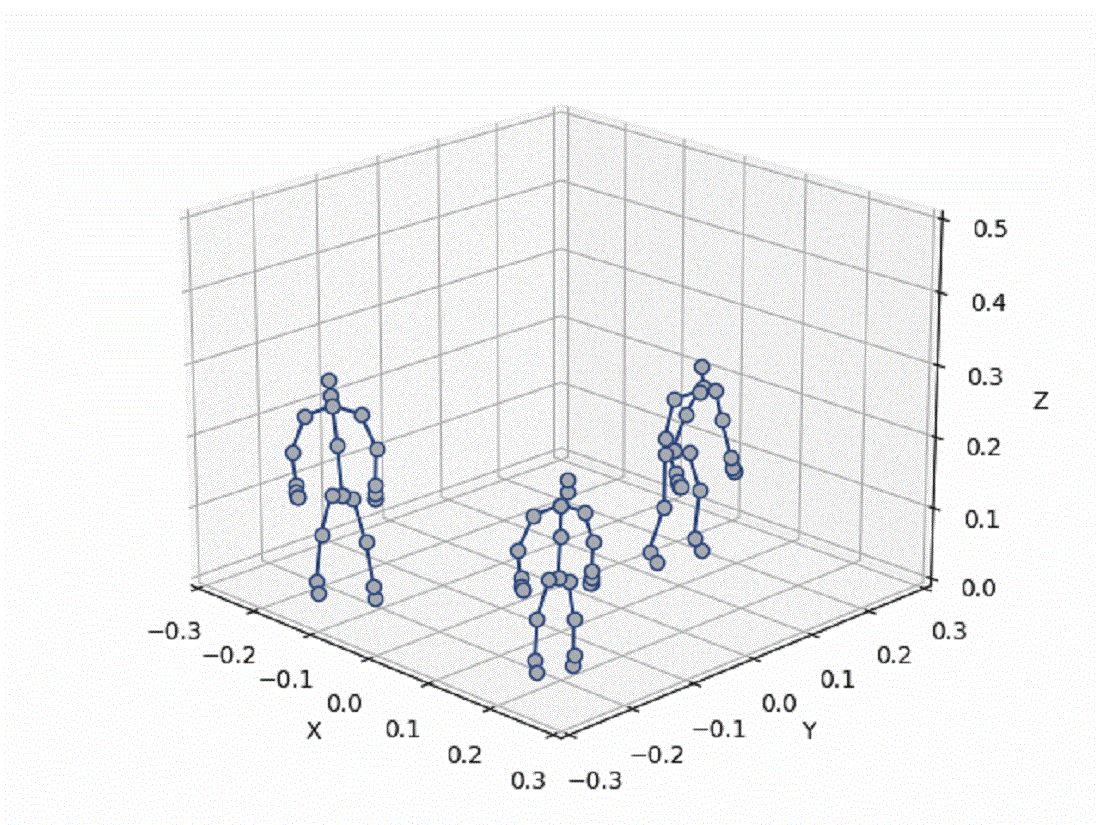
Це дослідження стосується критичної проблеми розпізнавання взаємних дій за участю кількох осіб, важливого завдання для таких програм, як відеоспостереження, взаємодія людини з комп’ютером, автономні системи та аналіз поведінки. Ідентифікація цих дій із тривимірних послідовностей рухів скелета створює значні проблеми через необхідність точного захоплення складних просторових і часових моделей у різноманітних, динамічних і часто непередбачуваних середовищах. Щоб вирішити цю проблему, було розроблено надійну структуру нейронної мережі, яка поєднує згорткові нейронні мережі (CNN) для ефективного вилучення просторових ознак із мережами довготривалої короткочасної пам’яті (LSTM) для моделювання часових залежностей у розширених послідовностях. Відмінною рисою цього дослідження є створення гібридного набору даних, який поєднує дані про рух скелета в реальному світі з синтетично згенерованими зразками, створеними за допомогою генеративних змагальних мереж (GAN). Цей набір даних збагачує варіативність, покращує узагальнення та пом’якшує проблеми дефіциту даних. Експериментальні результати в трьох різних мережевих архітектурах демонструють, що запропонований в даному дослідженні метод значно підвищує точність розпізнавання, в основному завдяки інтеграції CNN і LSTM разом із розширеним набором даних. Такий підхід успішно визначає складні взаємодії та забезпечує стабільну продуктивність у різних точках зору та в умовах навколишнього середовища. Підвищена надійність розпізнавання вказує на те, що цю структуру можна ефективно використовувати в практичних програмах, таких як системи безпеки, моніторинг натовпу та інших областях, де точне виявлення взаємних дій є критичним, особливо в реальному часі та динамічних середовищах
Посилання
- Pareek, P., Thakkar, A. (2020). A survey on video-based Human Action Recognition: recent updates, datasets, challenges, and applications. Artificial Intelligence Review, 54 (3), 2259–2322. https://doi.org/10.1007/s10462-020-09904-8
- Cermeño, E., Pérez, A., Sigüenza, J. A. (2018). Intelligent video surveillance beyond robust background modeling. Expert Systems with Applications, 91, 138–149. https://doi.org/10.1016/j.eswa.2017.08.052
- Fang, M., Chen, Z., Przystupa, K., Li, T., Majka, M., Kochan, O. (2021). Examination of Abnormal Behavior Detection Based on Improved YOLOv3. Electronics, 10 (2), 197. https://doi.org/10.3390/electronics10020197
- Hejazi, S. M., Abhayaratne, C. (2022). Handcrafted localized phase features for human action recognition. Image and Vision Computing, 123, 104465. https://doi.org/10.1016/j.imavis.2022.104465
- Yan, S., Xiong, X., Arnab, A., Lu, Z., Zhang, M., Sun, C., Schmid, C. (2022). Multiview Transformers for Video Recognition. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 3323–3333. https://doi.org/10.1109/cvpr52688.2022.00333
- Tong, Z., Song, Y., Wang, J., Wang, L. (2022). VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training. arXiv. https://arxiv.org/abs/2203.12602
- Hochreiter, S., Schmidhuber, J. (1997). Long Short-Term Memory. Neural Computation, 9 (8), 1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735
- Soltau, H., Liao, H., Sak, H. (2017). Neural Speech Recognizer: Acoustic-to-Word LSTM Model for Large Vocabulary Speech Recognition. Interspeech 2017. https://doi.org/10.21437/interspeech.2017-1566
- Kozhirbayev, Z., Yessenbayev, Z., Karabalayeva, M. (2017). Kazakh and Russian Languages Identification Using Long Short-Term Memory Recurrent Neural Networks. 2017 IEEE 11th International Conference on Application of Information and Communication Technologies (AICT), 1–5. https://doi.org/10.1109/icaict.2017.8687095
- Lu, Y., Lu, C., Tang, C.-K. (2017). Online Video Object Detection Using Association LSTM. 2017 IEEE International Conference on Computer Vision (ICCV). https://doi.org/10.1109/iccv.2017.257
- Huang, R., Zhang, W., Kundu, A., Pantofaru, C., Ross, D. A., Funkhouser, T., Fathi, A. (2020). An LSTM Approach to Temporal 3D Object Detection in LiDAR Point Clouds. Computer Vision – ECCV 2020, 266–282. https://doi.org/10.1007/978-3-030-58523-5_16
- Yuan, Y., Liang, X., Wang, X., Yeung, D.-Y., Gupta, A. (2017). Temporal Dynamic Graph LSTM for Action-Driven Video Object Detection. 2017 IEEE International Conference on Computer Vision (ICCV). https://doi.org/10.1109/iccv.2017.200
- Zhang, B., Yu, J., Fifty, C., Han, W., Dai, A. M., Pang, R., Sha, F. (2021). Co-training Transformer with Videos and Images Improves Action Recognition. arXiv. https://doi.org/10.48550/arxiv.2112.07175
- Wang, Y., Li, K., Li, Y., He, Y., Huang, B., Zhao, Z. et al. (2022). InternVideo: General Video Foundation Models via Generative and Discriminative Learning. arXiv. https://doi.org/10.48550/arXiv.2212.03191
- Kay, W., Carreira, J., Simonyan, K., Zhang, B., Hillier, C., Vijayanarasimhan, S. et al. (2017). The Kinetics Human Action Video Dataset. arXiv. https://doi.org/10.48550/arXiv.1705.06950
- Carreira, J., Noland, E., Banki-Horvath, A., Hillier, C., Zisserman, A. (2018). A short note about kinetics-600. arXiv. https://doi.org/10.48550/arXiv.1808.01340
- Carreira, J., Noland, E., Hillier, C., Zisserman, A. (2019). A short note on the kinetics-700 human action dataset. arXiv. https://doi.org/10.48550/arXiv.1907.06987
- Goyal, R., Kahou, S. E., Michalski, V., Materzynska, J., Westphal, S., Kim, H. et al. (2017). The “Something Something” Video Database for Learning and Evaluating Visual Common Sense. 2017 IEEE International Conference on Computer Vision (ICCV). https://doi.org/10.1109/iccv.2017.622
- Heilbron, F. C., Escorcia, V., Ghanem, B., Niebles, J. C. (2015). ActivityNet: A large-scale video benchmark for human activity understanding. 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). https://doi.org/10.1109/cvpr.2015.7298698
- Zhao, H., Torralba, A., Torresani, L., Yan, Z. (2019). HACS: Human Action Clips and Segments Dataset for Recognition and Temporal Localization. 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 8667–8677. https://doi.org/10.1109/iccv.2019.00876
- Kuehne, H., Jhuang, H., Garrote, E., Poggio, T., Serre, T. (2011). HMDB: A large video database for human motion recognition. 2011 International Conference on Computer Vision, 2556–2563. https://doi.org/10.1109/iccv.2011.6126543
- Shahroudy, A., Liu, J., Ng, T.-T., Wang, G. (2016). NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). https://doi.org/10.1109/cvpr.2016.115
- Liu, J., Shahroudy, A., Perez, M., Wang, G., Duan, L.-Y., Kot, A. C. (2020). NTU RGB+D 120: A Large-Scale Benchmark for 3D Human Activity Understanding. IEEE Transactions on Pattern Analysis and Machine Intelligence, 42 (10), 2684–2701. https://doi.org/10.1109/tpami.2019.2916873
- Degardin, B., Neves, J., Lopes, V., Brito, J., Yaghoubi, E., Proenca, H. (2022). Generative Adversarial Graph Convolutional Networks for Human Action Synthesis. 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2753–2762. https://doi.org/10.1109/wacv51458.2022.00281
- Caetano, C., Sena, J., Bremond, F., Dos Santos, J. A., Schwartz, W. R. (2019). SkeleMotion: A New Representation of Skeleton Joint Sequences based on Motion Information for 3D Action Recognition. 2019 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS). https://doi.org/10.1109/avss.2019.8909840
- Groleau, G. A., Tso, E. L., Olshaker, J. S., Barish, R. A., Lyston, D. J. (1993). Baseball bat assault injuries. The Journal of Trauma: Injury, Infection, and Critical Care, 34 (3), 366–372. https://doi.org/10.1097/00005373-199303000-00010
- DegardinBruno/Kinetic-Gan. Available at: https://github.com/DegardinBruno/Kinetic-GAN
- Li, C., Zhong, Q., Xie, D., Pu, S. (2017). Skeleton-based action recognition with convolutional neural networks. 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), 597–600. https://doi.org/10.1109/icmew.2017.8026285
- Goodfellow, I. J., Warde-Farley, D., Mirza, M., Courville, A. C., Bengio, Y. (2013). Maxout networks. arXiv. https://doi.org/10.48550/arXiv.1302.4389
- Zheng, W., Li, L., Zhang, Z., Huang, Y., Wang, L. (2019). Relational Network for Skeleton-Based Action Recognition. 2019 IEEE International Conference on Multimedia and Expo (ICME), 826–831. https://doi.org/10.1109/icme.2019.00147
##submission.downloads##
Опубліковано
Як цитувати
Номер
Розділ
Ліцензія
Авторське право (c) 2024 Talgat Islamgozhayev, Beibut Amirgaliyev, Zhanibek Kozhirbayev

Ця робота ліцензується відповідно до Creative Commons Attribution 4.0 International License.
Закріплення та умови передачі авторських прав (ідентифікація авторства) здійснюється у Ліцензійному договорі. Зокрема, автори залишають за собою право на авторство свого рукопису та передають журналу право першої публікації цієї роботи на умовах ліцензії Creative Commons CC BY. При цьому вони мають право укладати самостійно додаткові угоди, що стосуються неексклюзивного поширення роботи у тому вигляді, в якому вона була опублікована цим журналом, але за умови збереження посилання на першу публікацію статті в цьому журналі.
Ліцензійний договір – це документ, в якому автор гарантує, що володіє усіма авторськими правами на твір (рукопис, статтю, тощо).
Автори, підписуючи Ліцензійний договір з ПП «ТЕХНОЛОГІЧНИЙ ЦЕНТР», мають усі права на подальше використання свого твору за умови посилання на наше видання, в якому твір опублікований. Відповідно до умов Ліцензійного договору, Видавець ПП «ТЕХНОЛОГІЧНИЙ ЦЕНТР» не забирає ваші авторські права та отримує від авторів дозвіл на використання та розповсюдження публікації через світові наукові ресурси (власні електронні ресурси, наукометричні бази даних, репозитарії, бібліотеки тощо).
За відсутності підписаного Ліцензійного договору або за відсутністю вказаних в цьому договорі ідентифікаторів, що дають змогу ідентифікувати особу автора, редакція не має права працювати з рукописом.
Важливо пам’ятати, що існує і інший тип угоди між авторами та видавцями – коли авторські права передаються від авторів до видавця. В такому разі автори втрачають права власності на свій твір та не можуть його використовувати в будь-який спосіб.






