Розпізнавання говорячого за надкороткими висловлюваннями
DOI:
https://doi.org/10.15587/1729-4061.2025.327907Ключові слова:
розпізнавання диктора, надкороткі висловлювання, пофонемне розпізнавання, ECAPA-TDNN, фонеми казахської мовиАнотація
Об'єктом дослідження є точність ідентифікації дикторів за короткими висловлюваннями.
Для розв'язання проблеми ідентифікації мовця за надкороткими мовленнєвими висловлюваннями в межах дослідження був запропонований пофонемний підхід до побудови голосових моделей. Обґрунтованість цього підходу базується на тому, що в коротких висловлюваннях зазвичай присутня обмежена кількість фонем. У зв'язку з цим у роботі була висунута гіпотеза про те, що для підвищення точності ідентифікації дикторів за короткими висловлюваннями потрібно аналізувати звучання конкретних фонем різними дикторами.
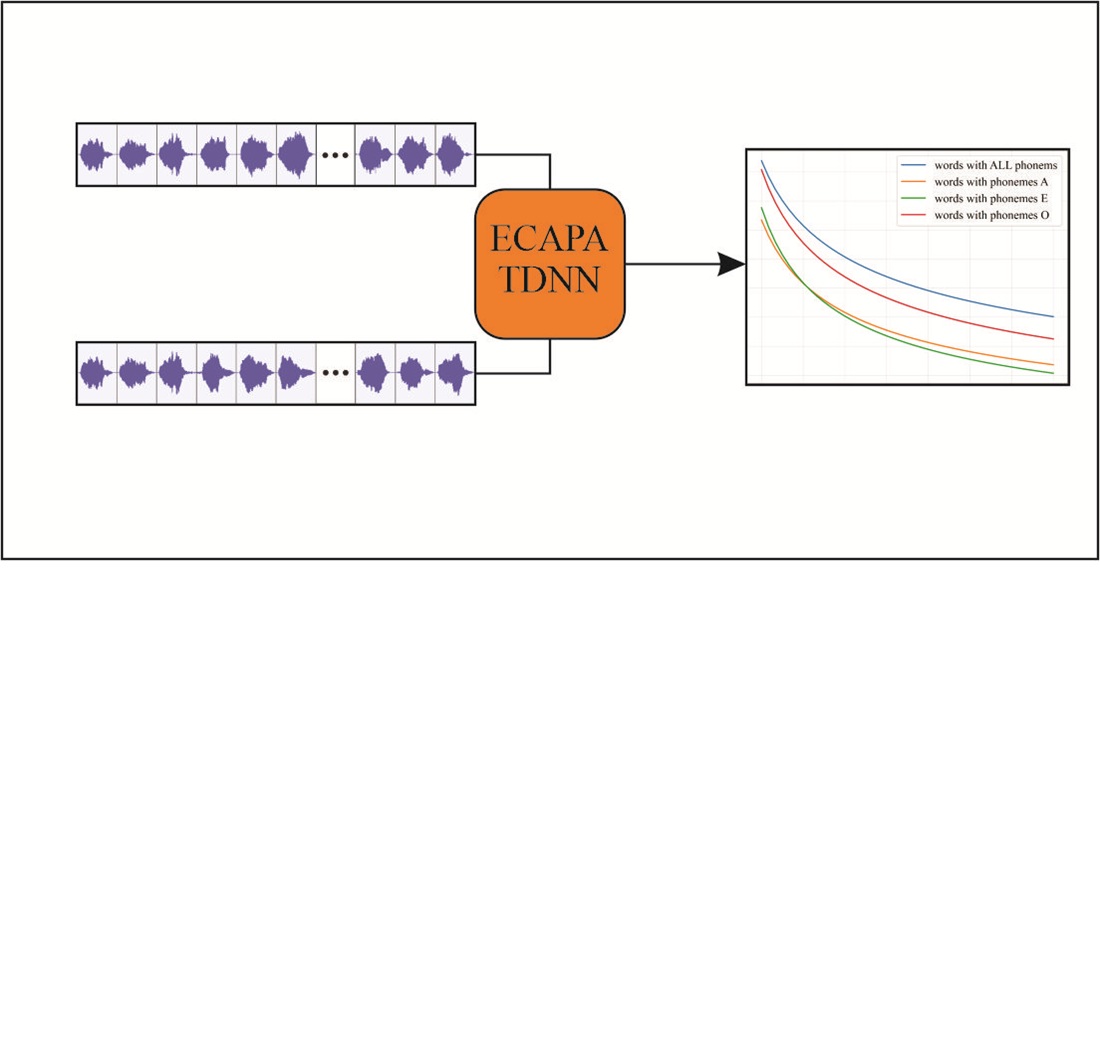
У експериментах використовувалися мовленнєві записи односкладових слів із відповідними фонемами, на основі яких за допомогою нейромережевої архітектури ECAPA-TDNN були побудовані голосові моделі дикторів. Проведені експериментальні дослідження показали, що голосові моделі, побудовані на основі звуків лише однієї фонеми, забезпечують вищу точність ідентифікації дикторів порівняно з узагальненими моделями, побудованими за всіма мовленнєвими звуками.
Також було встановлено, що різні фонеми забезпечують різну точність ідентифікації дикторів. Наприклад, при тривалості мовного сигналу 2–3 секунди точність ідентифікації дикторів за допомогою узагальненої моделі склала 75 %, тоді як точність ідентифікації за моделлю, побудованою на основі лише фонеми «Е», за тих самих вхідних даних склала 85 %, що на 10 процентних пунктів вище, ніж у загальної моделі
Посилання
- Sharif-Noughabi, M., Razavi, S. M., Mohamadzadeh, S. (2025). Improving the Performance of Speaker Recognition System Using Optimized VGG Convolutional Neural Network and Data Augmentation. International Journal of Engineering, 38 (10), 2414–2425. https://doi.org/10.5829/ije.2025.38.10a.17
- Tomar, S., Koolagudi, S. G. (2025). Blended-emotional speech for Speaker Recognition by using the fusion of Mel-CQT spectrograms feature extraction. Expert Systems with Applications, 276, 127184. https://doi.org/10.1016/j.eswa.2025.127184
- Chauhan, N., Isshiki, T., Li, D. (2024). Enhancing Speaker Recognition Models with Noise-Resilient Feature Optimization Strategies. Acoustics, 6 (2), 439–469. https://doi.org/10.3390/acoustics6020024
- Kohler, O., Imtiaz, M. (2025). Investigation of Text-Independent Speaker Verification by Support Vector Machine-Based Machine Learning Approaches. Electronics, 14 (5), 963. https://doi.org/10.3390/electronics14050963
- Missaoui, I., Lachiri, Z. (2025). Stationary wavelet Filtering Cepstral coefficients (SWFCC) for robust speaker identification. Applied Acoustics, 231, 110435. https://doi.org/10.1016/j.apacoust.2024.110435
- Zhang, X., Tang, J., Cao, H., Wang, C., Shen, C., Liu, J. (2025). A Self-Supervised Method for Speaker Recognition in Real Sound Fields with Low SNR and Strong Reverberation. Applied Sciences, 15 (6), 2924. https://doi.org/10.3390/app15062924
- Li, P., Hoi, L. M., Wang, Y., Yang, X., Im, S. K. (2025). Enhancing Speaker Recognition with CRET Model: a fusion of CONV2D, RESNET and ECAPA-TDNN. EURASIP Journal on Audio, Speech, and Music Processing, 2025 (1). https://doi.org/10.1186/s13636-025-00396-4
- Ohi, A. Q., Mridha, M. F., Hamid, M. A., Monowar, M. M., Lee, D., Kim, J. (2020). A Lightweight Speaker Recognition System Using Timbre Properties. arXiv. https://doi.org/10.48550/arXiv.2010.05502
- Kye, S. M., Jung, Y., Lee, H. B., Hwang, S. J., Kim, H. (2020). Meta-Learning for Short Utterance Speaker Recognition with Imbalance Length Pairs. Interspeech 2020. https://doi.org/10.21437/interspeech.2020-1283
- Wang, W., Zhao, H., Yang, Y., Chang, Y., You, H. (2023). Few-shot short utterance speaker verification using meta-learning. PeerJ Computer Science, 9, e1276. https://doi.org/10.7717/peerj-cs.1276
- Chen, Y., Zheng, S., Wang, H., Cheng, L., Zhu, T., Huang, R. et al. (2025). 3D-Speaker-Toolkit: An Open-Source Toolkit for Multimodal Speaker Verification and Diarization. ICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1–5. https://doi.org/10.1109/icassp49660.2025.10888389
- Desplanques, B., Thienpondt, J., Demuynck, K. (2020). ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN Based Speaker Verification. Interspeech 2020. https://doi.org/10.21437/interspeech.2020-2650
- Ravanelli, M., Parcollet, T., Moumen, A., de Langen, S., Subakan, C., Plantingaet, P. al. (2024). Open-Source Conversational AI with SpeechBrain 1.0. arXiv. https://arxiv.org/abs/2407.00463
- Ravanelli, M., Parcollet, T., Plantinga, P., Rouhe, A., Cornell, S., Lugosch, L. et al. (2021). SpeechBrain: A General-Purpose Speech Toolkit. arXiv. https://arxiv.org/abs/2106.04624
##submission.downloads##
Опубліковано
Як цитувати
Номер
Розділ
Ліцензія
Авторське право (c) 2025 Bekbolat Medetov, Aigul Nurlankyzy, Timur Namazbayev, Ainur Akhmediyarova, Kairatbek Zhetpisbayev, Ainur Zhetpisbayeva, Aliya Kargulova

Ця робота ліцензується відповідно до Creative Commons Attribution 4.0 International License.
Закріплення та умови передачі авторських прав (ідентифікація авторства) здійснюється у Ліцензійному договорі. Зокрема, автори залишають за собою право на авторство свого рукопису та передають журналу право першої публікації цієї роботи на умовах ліцензії Creative Commons CC BY. При цьому вони мають право укладати самостійно додаткові угоди, що стосуються неексклюзивного поширення роботи у тому вигляді, в якому вона була опублікована цим журналом, але за умови збереження посилання на першу публікацію статті в цьому журналі.
Ліцензійний договір – це документ, в якому автор гарантує, що володіє усіма авторськими правами на твір (рукопис, статтю, тощо).
Автори, підписуючи Ліцензійний договір з ПП «ТЕХНОЛОГІЧНИЙ ЦЕНТР», мають усі права на подальше використання свого твору за умови посилання на наше видання, в якому твір опублікований. Відповідно до умов Ліцензійного договору, Видавець ПП «ТЕХНОЛОГІЧНИЙ ЦЕНТР» не забирає ваші авторські права та отримує від авторів дозвіл на використання та розповсюдження публікації через світові наукові ресурси (власні електронні ресурси, наукометричні бази даних, репозитарії, бібліотеки тощо).
За відсутності підписаного Ліцензійного договору або за відсутністю вказаних в цьому договорі ідентифікаторів, що дають змогу ідентифікувати особу автора, редакція не має права працювати з рукописом.
Важливо пам’ятати, що існує і інший тип угоди між авторами та видавцями – коли авторські права передаються від авторів до видавця. В такому разі автори втрачають права власності на свій твір та не можуть його використовувати в будь-який спосіб.







