Development of a hybrid siamese and feedforward neural networks architecture for semantic text similarity measurement
DOI:
https://doi.org/10.15587/1729-4061.2025.326956Keywords:
feedforward neural network, semantic text similarity, Sentence-BERT, Siamese neural networkAbstract
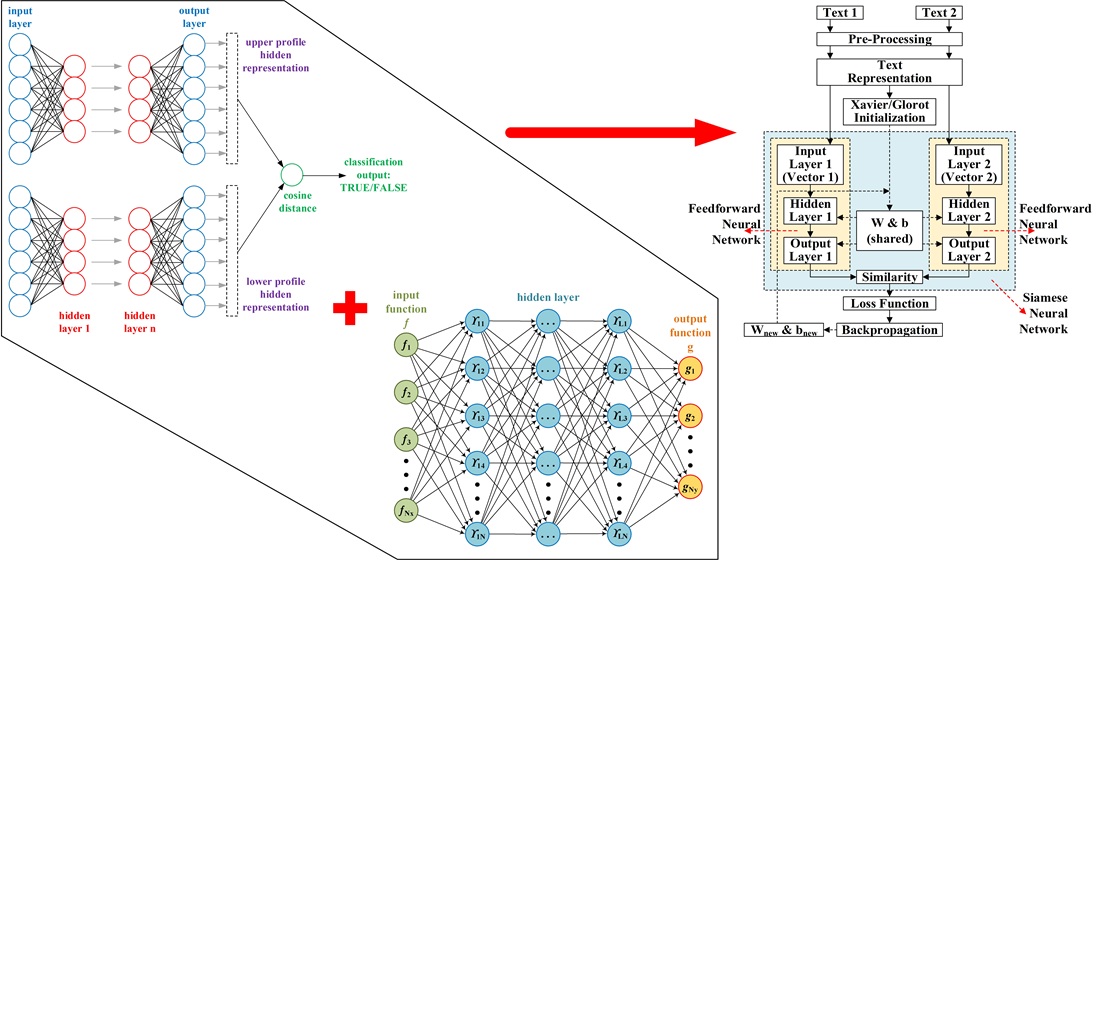
The object of this study is the semantic similarity between two texts. This research focuses on developing a hybrid architecture that combines Siamese Neural Network (SNN) with Feedforward Neural Network (FNN) to measure the semantic text similarity, with text representation using Sentence-BERT (SBERT). The problem addressed is the challenge of capturing deep semantic relationships between two texts, which traditional methods, such as Term Frequency-Inverse Document Frequency (TF-IDF) or Word2Vec, find difficult to achieve. This research aims to overcome these weaknesses by combining the two architectures into a more powerful hybrid system. The test results show the highest accuracy of 87.82 % on the Semantic Textual Similarity (STS) dataset using the SBERT “all-MiniLM-L6-v2” model, 76.72 % on the Quora Question Pairs (QQP) dataset using the “multi-qa-MiniLM-L6-cos-v1” model, and 73.79 % on the Microsoft Research Paraphrase Corpus (MSRP) dataset using the “paraphrase-MiniLM-L12-v2” model. The optimal parameters for the number of epochs ranged from 300 to 700, and the optimal learning rate ranged from 0.01 to 0.5. SBERT models, such as “paraphrase-MiniLM-L6-v2” and “paraphrase-MiniLM-L12-v2”, gave the best results on the relevant datasets. The flexibility of the “multi-qa-MiniLM-L6-cos-v1” model also shows that the model designed for question and answer tasks can be used in the paraphrase detection domain. A unique feature of the model is the integration of SBERT as a text representation, which results in a richer semantic vector than traditional methods. The model has potential for wide application in various domains, such as plagiarism detection, legal documents, and question-and-answer systems. However, implementation requires attention to parameter selection, such as learning rate and number of epochs, to avoid overfitting or underfitting
References
- Jinarat, S., Pruengkarn, R. (2024). Enhancing Short Text Semantic Similarity Measurement Using Pretrained Word Embeddings and Big Data. 2024 5th International Conference on Big Data Analytics and Practices (IBDAP), 63–66. https://doi.org/10.1109/ibdap62940.2024.10689695
- Abdalgader, K., Matroud, A. A., Hossin, K. (2024). Experimental study on short-text clustering using transformer-based semantic similarity measure. PeerJ Computer Science, 10, e2078. https://doi.org/10.7717/peerj-cs.2078
- Alnajem, N. A., Binkhonain, M., Shamim Hossain, M. (2024). Siamese Neural Networks Method for Semantic Requirements Similarity Detection. IEEE Access, 12, 140932–140947. https://doi.org/10.1109/access.2024.3469636
- Fan, A., Wang, S., Wang, Y. (2024). Legal Document Similarity Matching Based on Ensemble Learning. IEEE Access, 12, 33910–33922. https://doi.org/10.1109/access.2024.3371262
- Bao, W., Dong, J., Xu, Y., Yang, Y., Qi, X. (2024). Exploring Attentive Siamese LSTM for Low-Resource Text Plagiarism Detection. Data Intelligence, 6 (2), 488–503. https://doi.org/10.1162/dint_a_00242
- Goltaji, M., Abbaspour, J., Jowkar, A., Fakhrahmad, S. M. (2023). Comparison of text-based and linked-based metrics in terms of estimating the similarity of articles. Journal of Librarianship and Information Science, 56 (3), 760–772. https://doi.org/10.1177/09610006231165759
- Korade, N. B., Salunke, M. B., Bhosle, A. A., Kumbharkar, P. B., Asalkar, G. G., Khedkar, R. G. (2024). Strengthening Sentence Similarity Identification Through OpenAI Embeddings and Deep Learning. International Journal of Advanced Computer Science and Applications, 15 (4). https://doi.org/10.14569/ijacsa.2024.0150485
- Reimers, N., Gurevych, I. (2019). Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). https://doi.org/10.18653/v1/d19-1410
- Devlin, J., Chang, M.-W., Lee, K., Toutanova, K. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv. https://doi.org/10.48550/arXiv.1810.04805
- Altamimi, A., Umer, M., Hanif, D., Alsubai, S., Kim, T.-H., Ashraf, I. (2024). Employing Siamese MaLSTM Model and ELMO Word Embedding for Quora Duplicate Questions Detection. IEEE Access, 12, 29072–29082. https://doi.org/10.1109/access.2024.3367978
- Li, R., Cheng, L., Wang, D., Tan, J. (2023). Siamese BERT Architecture Model with attention mechanism for Textual Semantic Similarity. Multimedia Tools and Applications, 82 (30), 46673–46694. https://doi.org/10.1007/s11042-023-15509-4
- Chicco, D. (2020). Siamese Neural Networks: An Overview. Artificial Neural Networks, 73–94. https://doi.org/10.1007/978-1-0716-0826-5_3
- Wong, K., Dornberger, R., Hanne, T. (2022). An analysis of weight initialization methods in connection with different activation functions for feedforward neural networks. Evolutionary Intelligence, 17 (3), 2081–2089. https://doi.org/10.1007/s12065-022-00795-y
- Harumy, T. H. F., Zarlis, M., Lydia, M. S., Efendi, S. (2023). A novel approach to the development of neural network architecture based on metaheuristic protis approach. Eastern-European Journal of Enterprise Technologies, 4 (4 (124)), 46–59. https://doi.org/10.15587/1729-4061.2023.281986
- Han, S., Shi, L., Tsui, F. (Rich). (2025). Enhancing semantical text understanding with fine-tuned large language models: A case study on Quora Question Pair duplicate identification. PLOS ONE, 20 (1), e0317042. https://doi.org/10.1371/journal.pone.0317042
- Faseeh, M., Khan, M. A., Iqbal, N., Qayyum, F., Mehmood, A., Kim, J. (2024). Enhancing User Experience on Q&A Platforms: Measuring Text Similarity Based on Hybrid CNN-LSTM Model for Efficient Duplicate Question Detection. IEEE Access, 12, 34512–34526. https://doi.org/10.1109/access.2024.3358422
- Abdalla, H. I., Amer, A. A. (2021). Boolean logic algebra driven similarity measure for text based applications. PeerJ Computer Science, 7, e641. https://doi.org/10.7717/peerj-cs.641
- Xue, Y., Tong, Y., Neri, F. (2022). An ensemble of differential evolution and Adam for training feed-forward neural networks. Information Sciences, 608, 453–471. https://doi.org/10.1016/j.ins.2022.06.036
- Hemeida, A. M., Hassan, S. A., Mohamed, A.-A. A., Alkhalaf, S., Mahmoud, M. M., Senjyu, T., El-Din, A. B. (2020). Nature-inspired algorithms for feed-forward neural network classifiers: A survey of one decade of research. Ain Shams Engineering Journal, 11 (3), 659–675. https://doi.org/10.1016/j.asej.2020.01.007
- Harumy, T. H. F., Zarlis, M., Effendi, S., Lidya, M. S. (2021). Prediction Using A Neural Network Algorithm Approach (A Review). 2021 International Conference on Software Engineering & Computer Systems and 4th International Conference on Computational Science and Information Management (ICSECS-ICOCSIM), 325–330. https://doi.org/10.1109/icsecs52883.2021.00066
- Saini, J. R., Vaidya, S. (2024). A Novel Page Similarity Classification Algorithm for Healthcare Web URL Classification. Proceedings of Third International Conference on Computing and Communication Networks, 291–301. https://doi.org/10.1007/978-981-97-2671-4_22
- Diamzon, J., Venturi, D. (2025). Uncertainty Propagation in Feed-Forward Neural Network Models. https://doi.org/10.2139/ssrn.5201857
- Goodfellow, I., Bengio, Y., Courville, A. (2016). Deep Learning. MIT Press. Available at: https://www.deeplearningbook.org/
- Shen, Y., Lin, Z. (2024). PatentGrapher: A PLM-GNNs Hybrid Model for Comprehensive Patent Plagiarism Detection Across Full Claim Texts. IEEE Access, 12, 182717–182725. https://doi.org/10.1109/access.2024.3508762
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2025 Ng Poi Wong, Tengku Henny Febriana Harumy, Syahril Efendi

This work is licensed under a Creative Commons Attribution 4.0 International License.
The consolidation and conditions for the transfer of copyright (identification of authorship) is carried out in the License Agreement. In particular, the authors reserve the right to the authorship of their manuscript and transfer the first publication of this work to the journal under the terms of the Creative Commons CC BY license. At the same time, they have the right to conclude on their own additional agreements concerning the non-exclusive distribution of the work in the form in which it was published by this journal, but provided that the link to the first publication of the article in this journal is preserved.
A license agreement is a document in which the author warrants that he/she owns all copyright for the work (manuscript, article, etc.).
The authors, signing the License Agreement with TECHNOLOGY CENTER PC, have all rights to the further use of their work, provided that they link to our edition in which the work was published.
According to the terms of the License Agreement, the Publisher TECHNOLOGY CENTER PC does not take away your copyrights and receives permission from the authors to use and dissemination of the publication through the world's scientific resources (own electronic resources, scientometric databases, repositories, libraries, etc.).
In the absence of a signed License Agreement or in the absence of this agreement of identifiers allowing to identify the identity of the author, the editors have no right to work with the manuscript.
It is important to remember that there is another type of agreement between authors and publishers – when copyright is transferred from the authors to the publisher. In this case, the authors lose ownership of their work and may not use it in any way.






