Метод визначення ймовірного походження та ліцензійних умов програмного коду, згенерованого великими мовними моделями
DOI:
https://doi.org/10.31498/2225-6733.53.1.2026.359775Ключові слова:
великі мовні моделі, генерація програмного коду, походження програмного коду, аналіз подібності коду, ліцензування програмного забезпечення, програмна інженерія, штучний інтелектАнотація
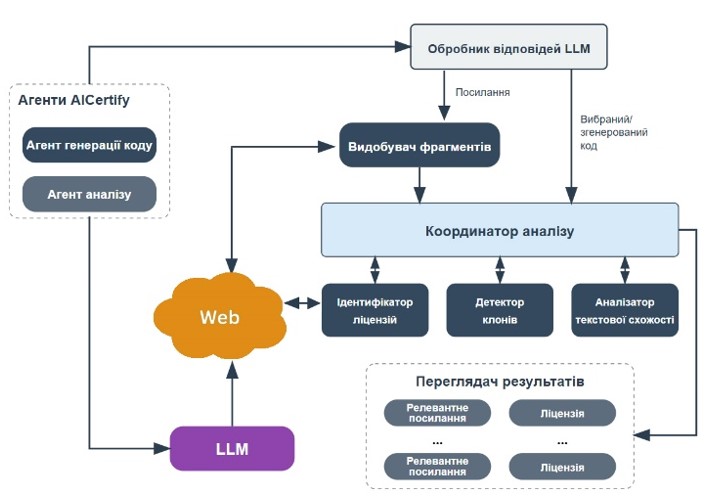
Активне впровадження великих мовних моделей у процес розроблення програмного забезпечення істотно змінює підходи до створення програмного коду. Одним із найбільш поширених сценаріїв використання таких моделей є автоматична генерація програмних фрагментів, що дозволяє підвищити продуктивність розробників та скоротити час реалізації програмних проєктів. Водночас застосування автоматично згенерованого коду породжує низку нових проблем, пов’язаних із відсутністю інформації про його походження, що ускладнює перевірку надійності джерела, а також може призводити до порушення авторських прав і ліцензійних умов. У роботі розглянуто проблему визначення походження програмного коду, створеного за допомогою великих мовних моделей, та запропоновано підхід до її вирішення. Метою дослідження є розроблення методу встановлення ймовірних джерел програмного коду та визначення можливих ліцензій його використання на основі аналізу подібності між згенерованими та знайденими у відкритих джерелах фрагментами. Запропонований підхід передбачає поєднання можливостей мовних моделей із механізмами вебпошуку, подальшим аналізом текстової подібності та виявленням клонів програмного коду. У результаті формується перелік вебресурсів, що можуть містити схожі фрагменти коду, а також здійснюється спроба автоматичного визначення їхніх ліцензійних умов. Отримані результати демонструють можливість ефективної фільтрації нерелевантних джерел та підвищення прозорості використання автоматично згенерованого програмного забезпечення. Наукова новизна дослідження полягає у поєднанні методів аналізу подібності програмного коду з інструментами вебпошуку для встановлення його ймовірного походження. Практична значущість роботи полягає у можливості використання запропонованого підходу для підвищення надійності програмних продуктів і зменшення ризиків порушення ліцензійних вимог. Перспективним напрямом подальших досліджень є удосконалення алгоритмів пошуку програмного коду та розширення методів автоматичного визначення його ліцензійних характеристик
Посилання
- Extracting Training Data from Large Language Models / N. Carlini et al. Proceedings of the 30-th USENIX Security Symposium, 11–13 August 2021. Pp. 2633–2650.
- Quantifying Memorization Across Neural Language Models / N. Carlini et al. arXiv preprint. arXiv:2202.07646. 2023. Pp. 1–34. DOI: https://doi.org/10.48550/arXiv.2202.07646.
- Evaluating Large Language Models Trained on Code / M. Chen et al. arXiv preprint. arXiv:2107.03374. 2021. Pp. 3–14. DOI: https://doi.org/10.48550/arXiv.2107.03374.
- GitHub Copilot AI pair programmer: Asset or Lia-bility? / A. M. Dakhel et al. Journal of Systems and Software. 2023. Vol. 203. Article 111734. DOI: https://doi.org/10.1016/j.jss.2023.111734.
- GitHub Copilot Documentation. URL: https://docs.github.com/en/copilot (дата звернення: 11.08.2025).
- Google Open Source. License Classifier. URL: https://github.com/google/licenseclassifier (дата звернення: 11.08.2025).
- Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation / Liu J., Xia C. S., Wang Y., Zhang L. arXiv preprint. arXiv:2305.01210. 2023. DOI: https://doi.org/10.48550/arXiv.2305.01210.
- CodeSearchNet Challenge: Evaluating the State of Semantic Code Search / H. Husain et al. arXiv pre-print. arXiv:1909.09436. 2019. DOI: https://doi.org/10.48550/arXiv.1909.09436.
- On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? / Bender E. M., Gebru T., McMillan-Major A., Shmitchell S. Proceedings of the 2021 ACM Conference on Fairness, Ac-countability, and Transparency, 3–10 March 2021. Pp. 610–623. DOI: https://doi.org/10.1145/3442188.3445922.
- SPDX License List. Software Package Data Exchange (SPDX). URL: https://spdx.org/licenses/ (дата звернення: 11.08.2025).
- Training language models to follow instructions with human feedback / L. Ouyang et al. arXiv pre-print. arXiv:2203.02155. 2022. Pp. 1–46. DOI: https://doi.org/10.48550/arXiv.2203.02155.
- Unveiling Memorization in Code Models / Z. Yang et al. arXiv preprint. arXiv:2308.09932. 2023. Pp. 1–11. DOI: https://doi.org/10.48550/arXiv.2308.09932.
- Kamiya T., Kusumoto S., Inoue K. CCFinder: a multilinguistic token-based code clone detection system for large scale source code. IEEE Transactions on Software Engineering. 2002. Vol. 28, no. 7. Pp. 654–670. DOI: https://doi.org/10.1109/TSE.2002.1019480.
- Deep Learning Meets Software Engineering: A Survey on Pre-Trained Models of Source Code / Niu C., Li C., Luo B., Ng V. Thirty-First International Joint Conference on Artificial Intelligence (IJCAI-22), Vienna, Austria, 23-29 July 2022. Pp. 5546–5555. DOI: https://doi.org/10.24963/ijcai.2022/775.
- Code Clone Detection based on Event Embedding and Event Dependency / Huang C., Zhou H., Ye C., Li B. arXiv preprint. arXiv:2111.14183. 2021. DOI: https://doi.org/10.48550/arXiv.2111.14183.
- Program Synthesis with Large Language Models / J. Austin et al. arXiv preprint. arXiv:2108.07732. 2021. Pp. 1–12. DOI: https://doi.org/10.48550/arXiv.2108.07732.
##submission.downloads##
Опубліковано
Як цитувати
Номер
Розділ
Ліцензія

Ця робота ліцензується відповідно до Creative Commons Attribution 4.0 International License.
Журнал "Вісник Приазовського державного технічного університету. Серія: Технічні науки" видається під ліцензією СС-BY (Ліцензія «Із зазначенням авторства»).
Дана ліцензія дозволяє поширювати, редагувати, поправляти і брати твір за основу для похідних навіть на комерційній основі із зазначенням авторства. Це найзручніша з усіх пропонованих ліцензій. Рекомендується для максимального поширення і використання неліцензійних матеріалів.

Автори, які публікуються в цьому журналі, погоджуються з наступними умовами:
1. Автори залишають за собою право на авторство своєї роботи та передають журналу право першої публікації цієї роботи на умовах ліцензії Creative Commons Attribution License, яка дозволяє іншим особам вільно розповсюджувати опубліковану роботу з обов'язковим посиланням на авторів оригінальної роботи та першу публікацію роботи в цьому журналі.
2. Автори мають право укладати самостійні додаткові угоди, які стосуються неексклюзивного поширення роботи в тому вигляді, в якому вона була опублікована цим журналом (наприклад, розміщувати роботу в електронному сховищі установи або публікувати у складі монографії), за умови збереження посилання на першу публікацію роботи в цьому журналі.





